Uno de los problemas de tener un generador de números que parecen aleatorios es estar seguro de si lo son. Hay que tener en cuenta que hablamos de números aleatorios justos, donde todos sean igual de probables, en este caso de números binarios que con un 50% salga 0 o 1 (existen formas de asegurarse de que una fuente aleatoria es justa). Vamos a ver el test de rachas para validar la aleatoriedad.
Test de rachas
En el caso de números binarios este test es muy fácil de entender, contamos el número de rachas que hay en los datos. ¿Qués un racha? Cada vez que un valor es distinto que el valor anterior. Por ejemplo:
00110101100111100
Si lo separamos en rachas:
00 – 11 – 0 – 1 – 0 – 11 – 00 – 1111 – 00
Ahora contamos las rachas, los ceros y los unos. En este caso hay 9 rachas, 8 ceros y 9 unos.
Si el número de rachas es R, el número de ceros es n0, el de uno es n1 y n = n0+n1.
media => u = (2*n0 *n1 / n) + 1
varianza => var = 2*n0*n1*(2*n0*n1-n) / n² * (n-1)
desviación típica => des = sqrt(var)
Z = R + c – u / des
Si R > u → c = -0,5
Si R < u → c = 0,5
El resultado es el Z score. Podemos usar tablas para saber su valor pero si queremos tener una buena aproximación con una seguridad del 95% de que es una distribución aleatoria no puede ser mayor de 1.6 ni menor de -1.6.
R = 9
n0 = 8
n1 = 9
n = 17
u = (298 / 17) +1 = 9,47
var = 298 * (298-17) / 17² * (17-1) = 18,10
des = 4,25
Z = 9 – 0,5 – 9,47 / 4,25 = -0,22
-0,22 esta entre 1.6 y -1.6 con lo cual lo consideraríamos como aleatorio.
Tras ver lo bien que funcionaba VQGAN+CLIP para generar imágenes yo también quería hacer un programa que creara arte a partir de un texto pasado como referencia. Por supuesto el resultado ha sido un fracaso, sin embargo se puede aprender de los fracasos.
La idea
La idea es usar solo CLIP con algoritmos genéticos. CLIP permite calcular (más o menos) la diferencia entre una imagen y un texto. Si le paso el texto «pato» y una foto me dice como de parecido es el contenido de esa foto al texto, en este caso a un pato. La idea es usar CLIP como función fitness. Para ello calculamos el vector que CLIP asocia a la imagen generada por nuestro algoritmo genético (luego vemos esto) y el vector que asocia a nuestro texto de referencia y calculamos la similitud coseno . La similitud coseno devuelve un valor entre -1 y 1:
1 significa que es idéntico
0 significa que no tiene nada que ver (es ortogonal)
-1 que es opuesto
Por lo tanto nuestra función fitness seria:
fitness = 1 - simCos(vectorTexto, vectorImagen)
Vamos a ver un poco de código.
Vector de características de texto:
#vector de carateristicas de texto
text_tokenize = clip.tokenize(TEXT).to(device)
with torch.no_grad():
text_features = model.encode_text(text_tokenize)
text_features /= text_features.norm(dim=-1, keepdim=True)
Vector de características de la imagen:
#vector de carateristicas de la imagen
image = preprocess(im).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
image_features /= image_features.norm(dim=-1, keepdim=True)
Teniendo una función fitness ya puedo usar cualquier metaheurística. En este caso se trata de optimizar una imagen para que se acerque cada vez más a lo que CLIP considera similar al texto.
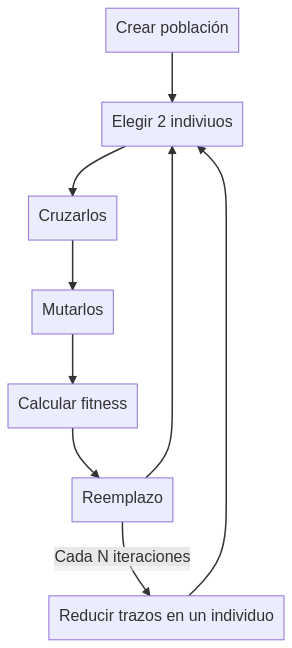
Para este caso vamos a usar algoritmos genéticos. Cada individuo es una imagen. Por lo tanto la población es un conjunto de imágenes que irán evolucionando y cruzándose compitiendo por reducir el valor de la función fitness.
Individuos, cruces y mutaciones
En un primer momento intente que el genotipo fueran los pixeles de la imagen y que las mutaciones y cruces fueran cambios aleatorios en los mismos. Manejar 16 millones de colores por cada pixel me parecían un espacio de soluciones muy amplio y decidí hacerlo en escala de grises por lo que solo tendría 256 posibilidades por pixel. Sin embargo el resultado fue un desastre los pixeles sueltos eran tan «pequeños» que creaba un «ruido» que no era capaz de evolucionar. Como solución intenté crear «píxels» más gordos. Para ello use cuadrados. Tampoco funcionó. Añadir colores dio como resultado cosas que podían tener sentido pro dentro de un ruido de colorines.
Siguiente plan, separar el genotipo y el fenotipo. El genotipo serían las instrucciones para construir la imagen mientras que el fenotipo sería la propia imagen. Como pasos para construir la imagen decidí usar pinceladas. En este caso para simularlas use líneas rectas que van de un punto aleatorio a otro, con color y anchura también aleatorios.
Una vez tenemos definidos los individuos hay que definir sus operaciones de cruce, de mutación y de reemplazo.
Operadores de cruce:
Intercambiar un bloque de trazos
Mezclar todos los trazos
No cruzar
Operadores de mutación:
Mover un trazo
Cambiar de color un trazo
Cambiar de orden un trazo por otro
Añadir un trazo
Como operador de reemplazo se reemplaza al peor individuo de la población (fitness más alto) por aquel hijo que tenga menos fitness que él.
Como el resultado era caótico, lleno de lineas de colores que no aportaban nada a CLIP pero dificultaba que un humano reconociera el dibujo decidí minimizar el número de trazos, para ello cada cierto tiempo se ejecuta una función de optimización local que prueba a eliminar cada uno de los trazos y si no altera o reduce la función fitness lo descarta.
Como último añadido y para dar más variedad a los trazos incluí que un trazo pueda ser una linea, un rectángulo o una elipse. Y una función mutación que cambia el tipo de trazo.
El resultado es un artista minimista que trata de trazar el menor número de líneas para dibujar un concepto.
Una Inteligencia artificial conceptual y minimalista
Hemos logrado un artista que crea con el menor número de trazos posible. Conceptual y minimalista…solo hay un problema que es un autor conceptual y minimalista desde el punto de vista de una IA. Hay imágenes en la que coincidimos, por ejemplo con las rosas:
Rosa
Otras imágenes sin embargo son incomprensibles, por ejemplo cuando le pido que me dibuje un pato le basta con dibujar una linea naranja rodeada de lineas verdosas, me lo hizo varias veces.
Pato ¿?
¿Por qué esa linea es un pato? Seguramente porque lo identifica con el pico y no necesita más para identificar un pato. Así que como nuestro autor minimalista reconoce patos por el pico (su rasgo más distintivo) es difícil que surja una mutación que mejore ese resultado.
Algo parecido me pasa con los dragones que no me pinta el cuerpo solo la cabeza, generalmente con algún tipo de «cresta» y a veces las patas, pero nada de cuerpo. Lo cual tiene sentido ya que su cuerpo se parece al de otros reptiles.
¿El dragón sin cuerpo?
Como herramienta puede ayudarnos a entender que «ve» una IA en una imagen.
Para probarlo dejo este enlace al codebook de Google donde probarlo
Llevo un tiempo probando VQGAN+CLIP para generar imágenes a partir de texto y quería hacer algo con él, pero no sabia el que. Hasta que recordé que hace años tenia un twitter llamado tweetcuento donde publicaba unos microcuentos que escribía. Sin entrar en detalles sobre mi calidad como cuentista me pareció que podría ser una buena idea usarlo de base para un experimento de creación de imágenes
VQGAN+CLIP es la unión de dos sistemas. VQGAN y CLIP . CLIP funciona como un puente entre las imágenes y el texto. Explicado pronto y mal, CLIP generaría el mismo valor (o al menos uno muy cercano) para una foto de una gafas que para la palabra «gafas». Ahí radica la clave de este sistema de generación de imágenes, se le pasa un texto a CLIP y luego una imagen generada por VQGAN. Y trata de que el valor del texto y la imagen se aproximen. VQGAN usa este valor para mejorar su resultado. Si queréis una explicación más exhaustiva DotCSV tiene un video estupendo sobre el tema.
Todo este proceso lo he realizado a partir de un notebook de google colab creado por Katherine Crowson . Sin embargo para usarlo con mis cuentos tenia que realizar varios pasos.
CLIP solo funciona en inglés así que toca traducir los microcuentos. Podría hacerlo yo pero me parece más interesante que lo haga un traductor automático (y es posible que lo haga mejor que yo). He recurrido al traductor de Google, pero no uso directamente sus resultados. Antes los reviso y solo los modifico si hay alguna palabra cuya traducción es errónea ya que podría influir en el resultado. En el resto delos casos dejo la traducción como esta. En las pruebas realizadas hasta ahora no he necesitado modificar la mayoría de los resultados.
Luego adapto el texto para pasarlo a CLIP. Elimino los símbolos que no sean letras o números. Cada frase separada por un punto la separo, los mismo hago con las conversaciones.
- Quiero ese globo - la niña señaló un pobre globo que apenas se elevaba del suelo
- Los hay más bonitos
- Si, pero este sé que no me dejará
Se convierte en
["Quiero ese globo", "la niña señaló un pobre globo que apenas se elevaba del suelo", "Los hay más bonitos", "Si pero este sé que no me dejará"]
En realidad el texto estaría en inglés pero el ejemplo se entiende mejor así.
Otra condición que me he autoimpuesto es que se generan solo 3 imágenes por cada cuento. Elegiré la que me parezca más adecuada, si dudo entre varias imágenes publicaré todas entre las que esté dudando.
Además esperare un par de días para evitar sesgos. He notado que cuando estas mirando como el sistema produce sus imágenes te parecen mucho mas sorprendentes unos que días después.
Las imágenes obtenidas son tal y como las genera VQGAN+CLIP . Muchas de ellas serian fácilmente mejorables con algún pequeño retoque.
Por último y puesto que no podían faltar los NFTs cada imagen es convertida en un NFT y ofrecida en una galería en Opensea. No creo que nadie vaya a comprarlas pero quería aprender el proceso.
Veamos un ejemplo de todo este proceso, partiendo del cuento:
"Las máquinas se rebelaron, ganaron la guerra y esclavizaron a la humanidad. Se convirtieron en los amos del mundo. Esta situación se prolongó durante tres años hasta que las máquinas perdieron ante su mayor enemigo, la obsolescencia programada."
La imagen obtenido ha sido:
Para ver mas ejemplos los iré publicando poco a poco en tweetcuento