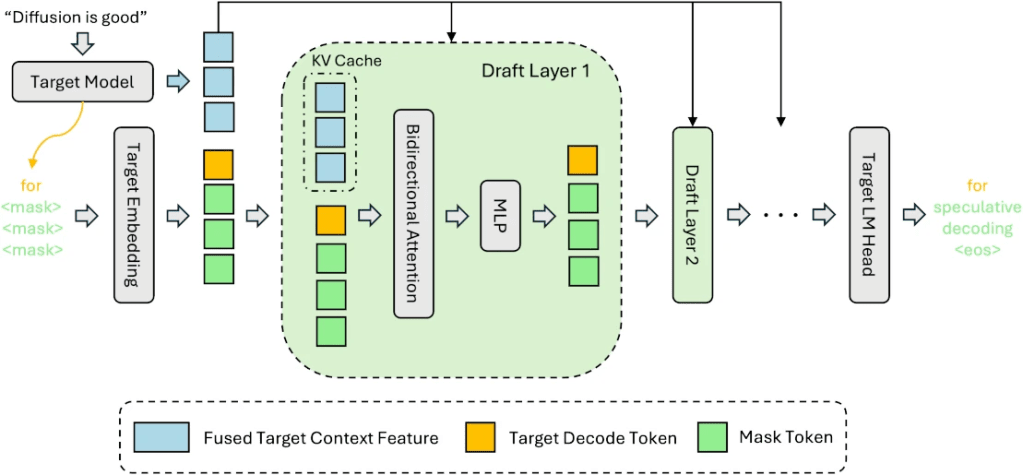
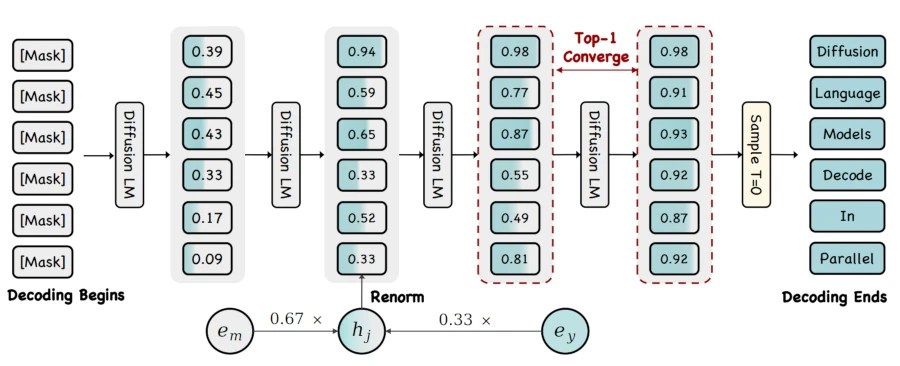
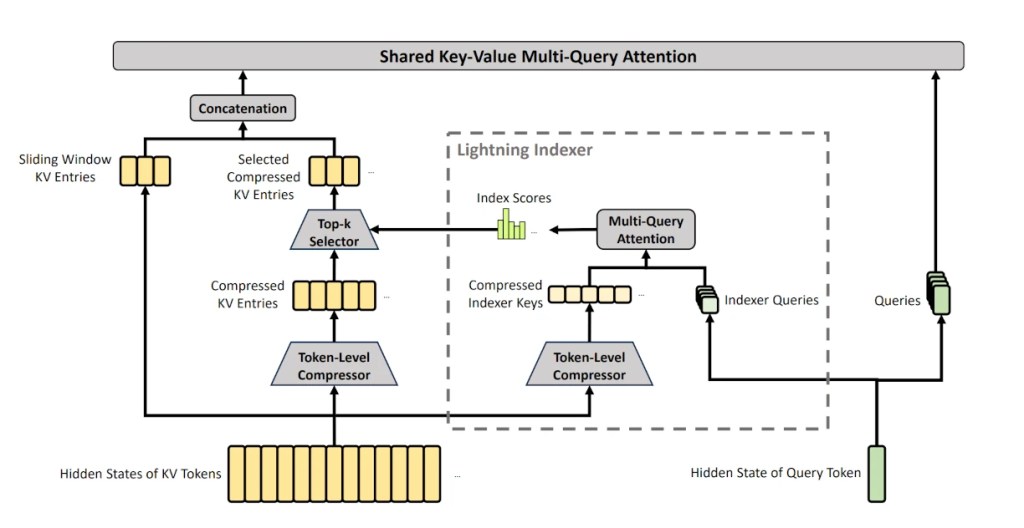
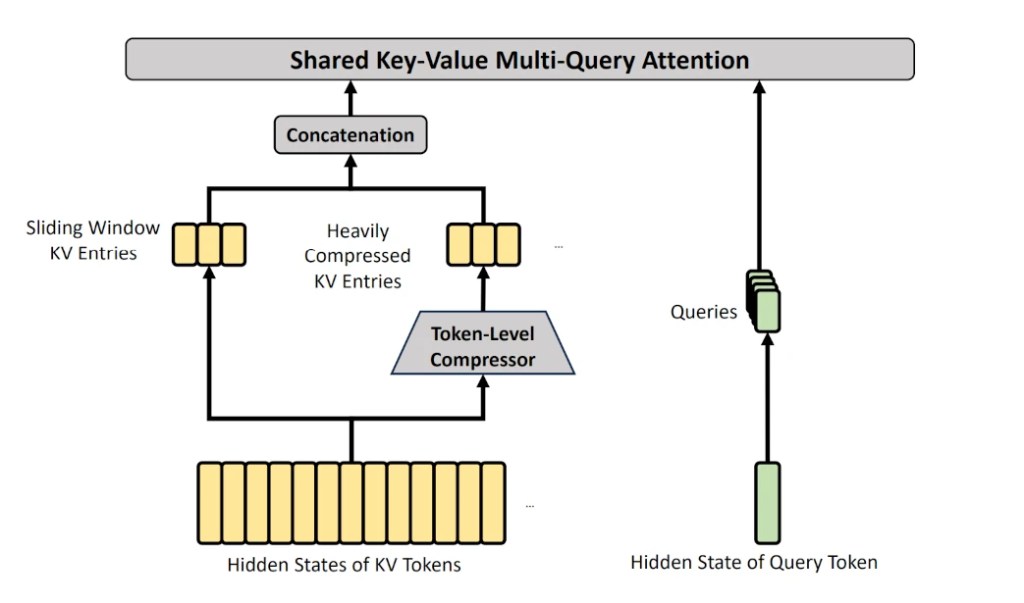
La inteligencia artificial no solo está cambiando nuestra forma de buscar información, sino que está transformando radicalmente el desarrollo y la interacción con la web. Empresas líderes como Google, que controlan gran parte de la infraestructura de internet (desde el navegador Chrome hasta el sistema operativo Android), están impulsando una visión donde la web ya no es solo para humanos, sino también para agentes autónomos. (Para este artículo he partido de esta publicación de Google)
Desarrollo asistido por IA
El desarrollo frontend está adoptando el uso de «skills» (habilidades) que permiten a la IA desarrollar usando correctamente las diversas tecnologías. De hecho algunos creadores de frameworks o tecnologías están publicando sus propias skills para que la IA los use correctamente. Incluso hay frameworks como hyperframes diseñados pensando en que los use la IA antes que en los humanos
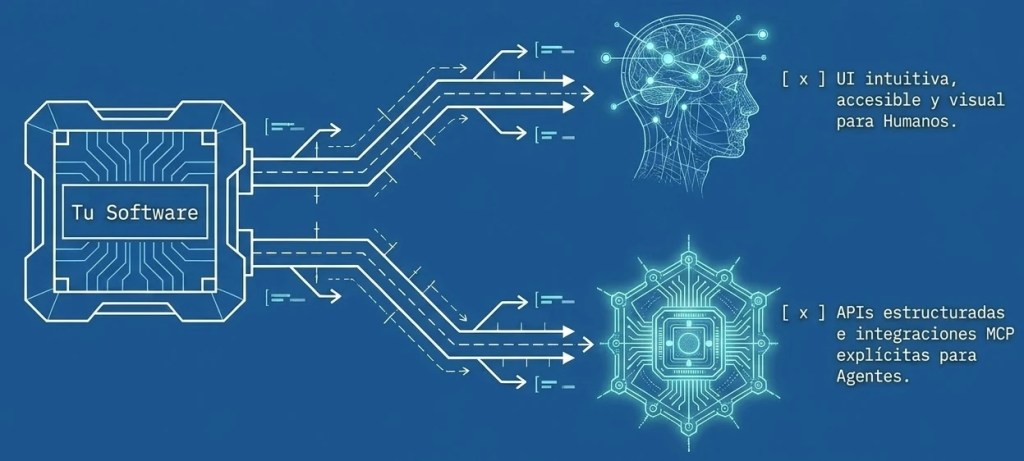
De Webs para Humanos a Webs para Agentes
Tradicionalmente, las webs se diseñan para que un humano las navegue visualmente, pero esto está cambiando. Surge la necesidad de crear webs para que los agentes puedan utilizar las funcionalidades de un sitio de manera eficiente. Un avance crucial en esta área es el protocolo Web MCP, una solución que permite a una página web comunicar directamente a un agente qué funciones tiene disponibles y qué parámetros necesita para ejecutarlas, como en el caso de la compra de entradas.
IA Ejecutada Localmente en el Navegador
Los modelos de IA ya no solo está en la nube, también en el dispositivo del usuario a través de tres tecnologías clave:

- WebAssembly (WASM): Permite migrar herramientas y modelos de lenguajes compilados directamente al navegador.
- WebGPU: Facilita el acceso a la potencia de la tarjeta gráfica desde la web para acelerar los cálculos de los modelos.
- Web Neural Network: Una capa de abstracción de alto nivel, actualmente en fase de borrador, diseñada para ejecutar y posiblemente entrenar redes neuronales en local.
De hecho, navegadores como Chrome ya están integrando modelos como Gemini Nano (un modelo multimodal de 4 GB) de forma nativa. Esto permite que las webs utilicen APIs específicas para tareas como resumir textos, traducir, reescribir contenido o detectar idiomas sin necesidad de enviar datos a servidores externos.
La Era de la Navegación Autónoma
La interacción del usuario evoluciona de una navegación pasiva a una colaboración activa con un «compañero de viaje» de IA, opción ya rpesente en navegadores como Firefox. Este asistente no solo leerá la web, sino que podrá ejecutar tareas mediante diversas interacciones, con acciones del teclado, ratón o con prompts, ya sea escritos o dictados.
Pero que necesidad hay de estar escribiendo los mismos prompts, tenemos la posibilidad de guardados como skills personalizadas para automatizar acciones repetitivas.
El objetivo final es la navegación autónoma, donde el usuario simplemente da una instrucción («mírame tal noticia» o «resume este vídeo») y el agente utiliza el navegador de forma independiente para completarla.
Conclusión para Desarrolladores
Como creadores de software, el reto actual es facilitar que nuestros desarrollos sean «legibles» y utilizables por estos asistentes. La diferencia competitiva del futuro residirá en qué tan bien se comunique nuestra web con los agentes que los usuarios emplearán para navegar por el mundo digital.