Durante los últimos años, hemos estado acostumbrados a que los modelos de lenguaje funcionen de forma autorregresiva. Es decir, generan el texto una palabra (o token) a la vez, donde cada palabra nueva depende de las anteriores, pero nunca puede influir en lo que ya se escribió. Sin embargo, una vieja idea está regresando con fuerza para desafiar este dominio: los modelos de lenguaje basados en difusión.
¿Qué es un modelo de lenguaje de difusión?
A diferencia de los modelos tradicionales, los modelos de difusión generan bloques enteros de texto al mismo tiempo. Imagina que todas las palabras de un párrafo comienzan siendo una «máscara» (un estado desconocido) y, poco a poco, el modelo va resolviendo esas máscaras hasta revelar el texto definitivo.
Esto prometía una velocidad altísima y una mejor relación entre todos los términos del bloque. Sin embargo, tenían un gran problema: a veces un token se «desenmascaraba» antes de tiempo y el modelo tenía que volver a taparlo para corregirlo, lo que acababa arruinando la velocidad y la calidad del resultado.
Recientemente han surgido dos propuestas que están rescatando esta tecnología del olvido:
Dflash: Velocidad extrema mediante «borradores»
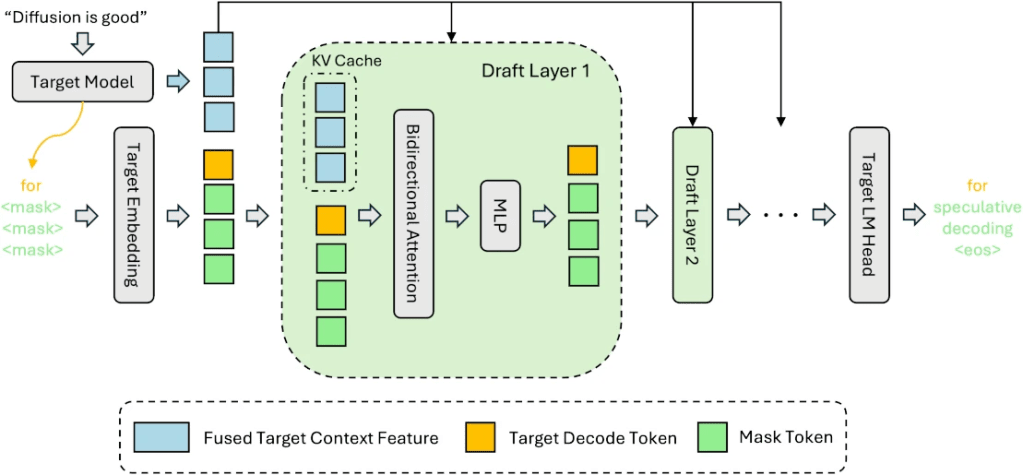
La idea de Dflash es combinar lo mejor de ambos mundos. Utiliza un modelo de difusión como un «modelo de borrador» para acelerar a un modelo más grande mediante una técnica llamada speculative decoding.
El modelo de difusión genera rápidamente una ráfaga de tokens y el modelo grande los valida todos en paralelo. Si el modelo de difusión acierta, hemos generado muchísimos tokens en un solo paso. En tareas predecibles, como las matemáticas o la programación, se han logrado incrementos de velocidad de hasta 8 o 9 veces respecto al método tradicional.
Dmax y los modelos UDLM: tokens con certeza
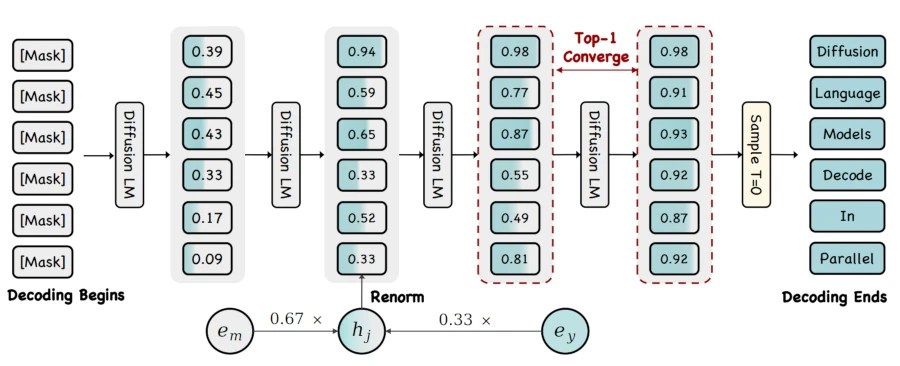
La segunda gran innovación es Dmax, que introduce los Modelos de Difusión de Lenguaje Uniforme (UDLM). Aquí se abandona la idea de que un token está «tapado» o «destapado».
En su lugar, cada posición en el texto es una probabilidad continua entre la incertidumbre absoluta (la máscara) y una palabra concreta (como «francia»). A medida que el proceso avanza, la probabilidad de la palabra crece y la de la máscara disminuye basándose en el contexto global. Esto permite que el texto evolucione de forma fluida y orgánica, evitando los errores de los modelos de difusión anteriores.
¿Por qué debería importarnos?
Estos avances no son solo técnicos; representan una forma de procesar la información mucho más cercana a la intuición humana. Nosotros no pensamos estrictamente palabra por palabra, sino que solemos visualizar ideas en bloques o párrafos.
Aunque los modelos autorregresivos siguen siendo los reyes del mercado, técnicas como DMAX ya están alcanzando niveles de calidad muy cercanos a ellos. Estamos ante un paso de gigante que podría cambiar la forma en que nuestras IAs escriben, programan y razonan en el futuro cercano.
