El mundo de la inteligencia artificial no descansa, y DeepSeek acaba de dar un golpe sobre la mesa con el lanzamiento de su versión 4.0. Esta nueva entrega no solo busca competir en potencia, sino que redefine lo que significa la eficiencia y la viabilidad comercial en modelos de gran lenguaje.
Dos Versiones, Un Contexto Gigante
DeepSeek 4.0 llega en dos sabores principales: Flash y Pro. La versión Flash, a pesar de ser la «pequeña», cuenta con 284B parámetros (13B activos), mientras que la versión Pro escala hasta los 1,6T parámetros con 49B activos
Ambos modelos utilizan una arquitectura de Mezcla de Expertos (MoE) y ofrecen una ventana de contexto impresionante de 1 millón de tokens. Además, han simplificado la interacción con tres niveles de razonamiento: sin razonamiento, nivel alto y nivel máximo.
Cuantización (QAT)
Uno de los movimientos más audaces de DeepSeek ha sido lanzar sus modelos Instruct ya cuantizados. Mientras que otras empresas prefieren lanzar modelos sin comprimir para ganar puntos en los tests de rendimiento, DeepSeek ha utilizado una técnica llamada QAT (Quantization-Aware Training).
Este proceso consiste en simular la pérdida de precisión (mezclando 8 bits y 4 bits) durante el propio entrenamiento. El resultado es un modelo mucho más resiliente y optimizado para su uso real, demostrando que la empresa prioriza un producto comercialmente viable frente a las «carreras locas» de lanzamientos cada pocos meses.
Magia en la Memoria: Optimizando la Atención
El mayor avance técnico se encuentra en cómo gestionan la atención. Han logrado reducir el tamaño de la caché de memoria de 50 GB a menos de 5 GB en contextos de un millón de tokens mediante tres técnicas combinadas:
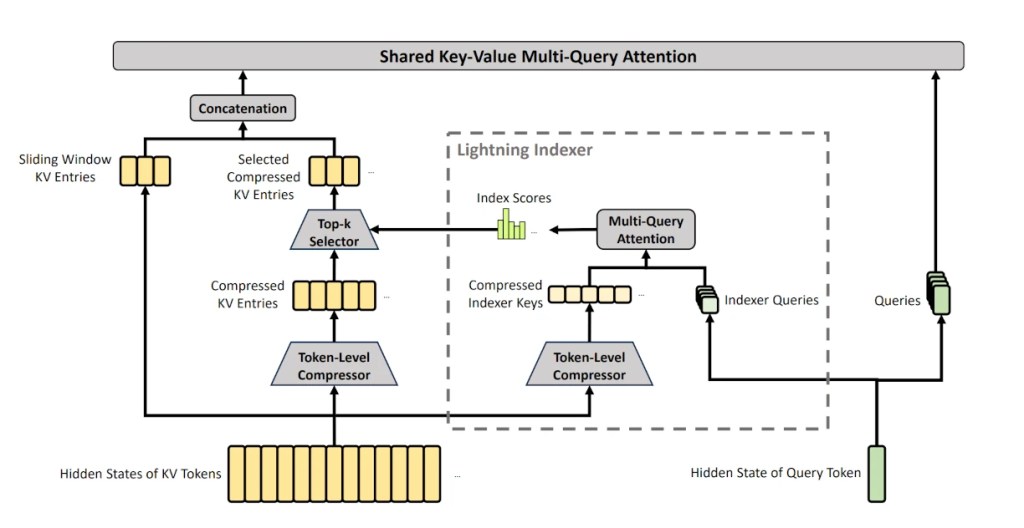
- CSA (Compress Sparse Attention): Comprime grupos de 4 tokens en uno solo.
- HCA (Heavily Compressed Attention): Lleva la compresión al extremo, resumiendo 128 tokens en uno.
- DSA: Un sistema que selecciona los tokens más interesantes de la caché comprimida para mantener la relevancia global.
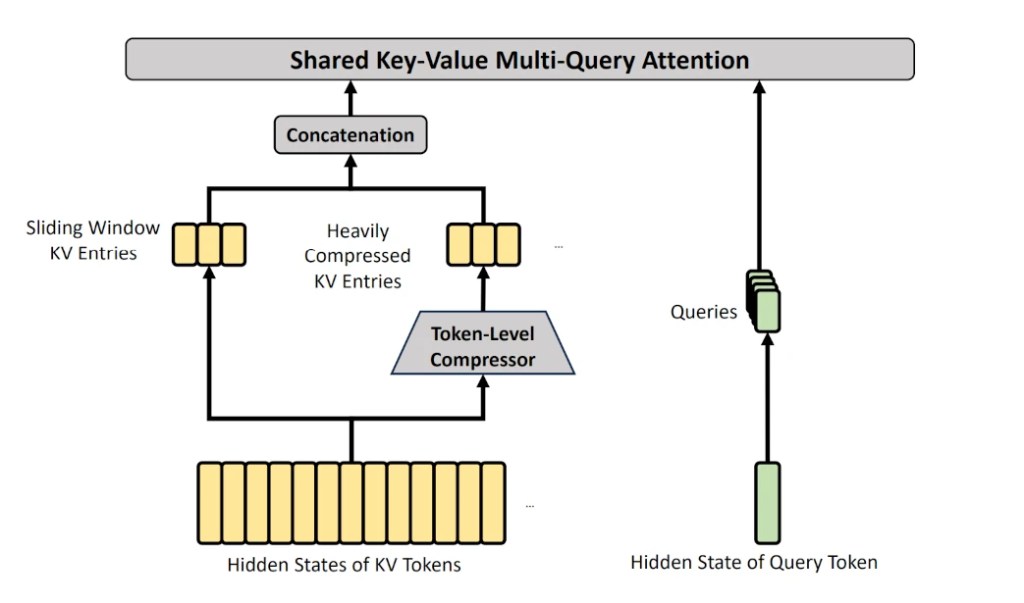
Para no perder los detalles finos, el modelo combina esta visión global resumida con una ventana deslizante que mantiene los últimos tokens con todo su detalle original.
Innovación Estructural: mHC
DeepSeek 4.0 sustituye las clásicas conexiones residuales por un nuevo sistema llamado mHC (Manifold Constrained Hyper Connections). En lugar de un único camino para que los datos fluyan y ayuden al aprendizaje, mHC utiliza múltiples canales. Aunque esto añade carga computacional, las fuertes restricciones matemáticas aplicadas logran una estabilidad y unos resultados que superan con creces a los métodos tradicionales.
¿Qué esperar del futuro?
Una de las novedades a esperar es que el modelo se vuelva multimodal (lo dicen en el propio paper).
DeepSeek 4.0 no es solo un modelo más potente; es una declaración de intenciones sobre cómo la ingeniería inteligente puede hacer que la tecnología más avanzada sea, por fin, sostenible y accesible.
