En esta entrada vamos a analizar una propuesta que rompe un poco con la tendencia actual de «cuanto más grande, mejor» en el mundo de la inteligencia artificial. Vamos a profundizar en HRM (Hierarchical Reasoning Model) y su evolución, HRM-Text, una arquitectura que está dando mucho que hablar por su eficiencia y su particular forma de razonar.
¿Qué es HRM y por qué es relevante?
Seguramente habéis oído hablar del modelo O3 de OpenAI y su éxito en el test ARC-AGI, un reto que en aquel momento se resistía a las máquinas. Pero mientras que el modelo O3 gastaba el equivalente a un millón de dólares en tokens para superar estas pruebas, surgio HRM: un modelo que, con apenas 27 millones de parámetros, lograba puntuaciones altísimas en ese mismo tests.
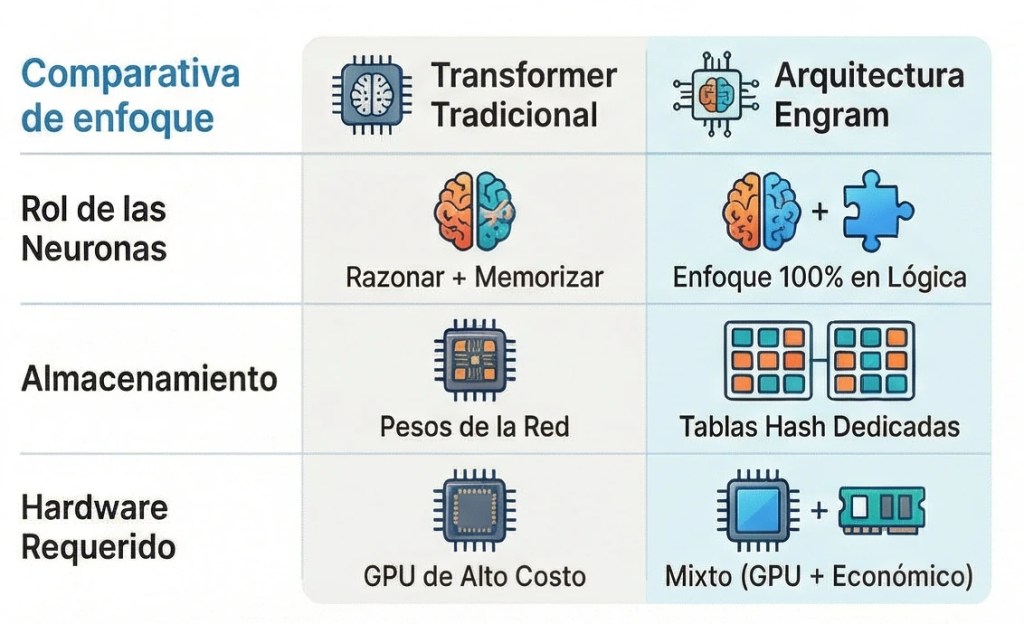
La clave de su éxito no está en el tamaño, sino en su arquitectura. A diferencia de los LLM tradicionales, HRM utiliza bucles internos. En lugar de pasar por los pesos una sola vez, la información circula varias veces por ellos, permitiendo que un modelo pequeño «piense» mucho más de lo que sugeriría su número de parámetros.
El secreto de los módulos H y L
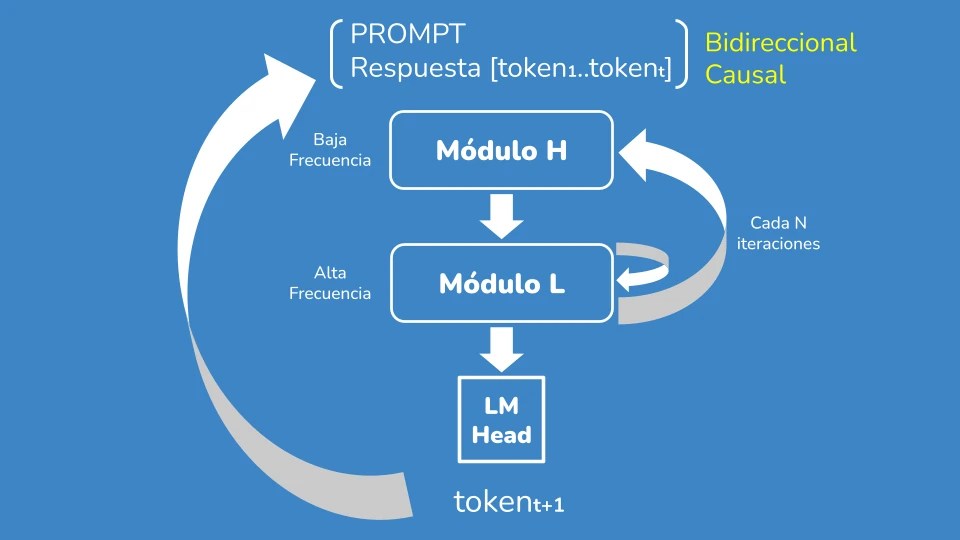
La arquitectura se divide fundamentalmente en dos piezas: el módulo H (de baja frecuencia) y el módulo L (de alta frecuencia). Aunque los nombres suenen complejos, la idea es sencilla y se inspira vagamente en el funcionamiento del cerebro:
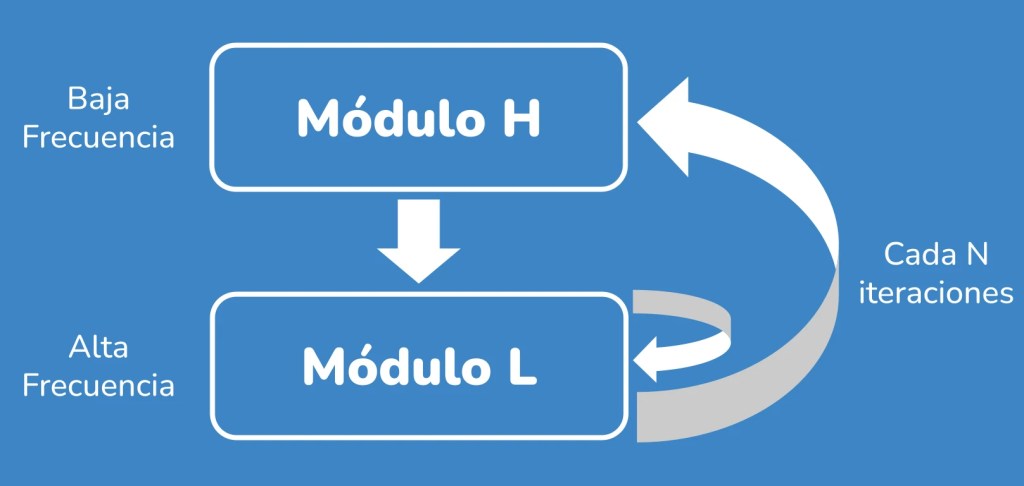
- Módulo H: Se encarga de buscar una solución general, marcando la dirección del razonamiento.
- Módulo L: Es el encargado de refinar esa solución. Se le llama varias veces (de ahí lo de «alta frecuencia») para pulir los detalles antes de devolverle el control al módulo H.
Este proceso de exploración y refinamiento se repite hasta que el sistema decide que ha encontrado una solución satisfactoria.
De HRM a HRM-Text: El salto a la generación de texto
Originalmente, HRM no era un modelo de lenguaje; estaba diseñado para resolver problemas lógicos, laberintos o acertijos visuales. Sin embargo, con la llegada de HRM-Text, la arquitectura ha evolucionado:
- Escalado: Ha pasado de 27 millones a 1.000 millones de parámetros. Sigue siendo pequeño para los estándares actuales, pero mucho más capaz.
- Autorregresión: Ahora es capaz de generar texto de forma secuencial, realimentando cada token producido para generar el siguiente.
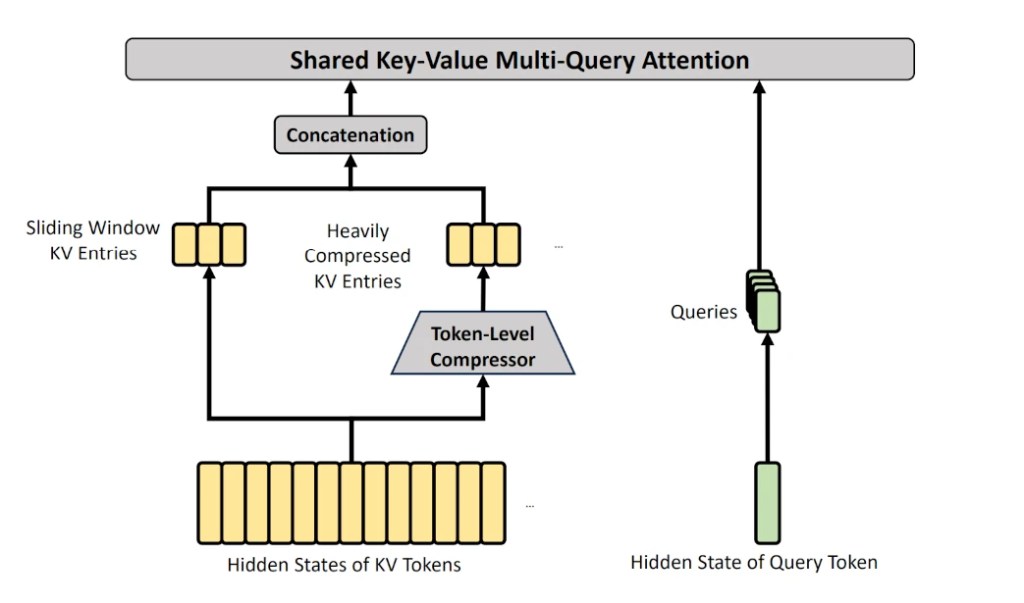
- Atención híbrida: Utiliza atención bidireccional para el «prompt» inicial y atención causal para el texto generado, incorporando un mecanismo de puerta para mantener la coherencia durante las múltiples iteraciones.
Eficiencia extrema y costes reducidos
Uno de los puntos más impactantes de HRM-Text es su entrenamiento. Se ha entrenado con 40.000 millones de tokens en solo 2 días, utilizando 16 GPUs y con un coste aproximado de 1.500 dólares. Comparado con las fortunas que cuesta entrenar modelos comerciales, esto es un cambio de juego total para la democratización de la IA.
Luces y sombras: Razonamiento vs. Conocimiento
No todo es perfecto. Al tener tan pocos parámetros, HRM-Text tiene limitaciones claras:
- Memoria limitada: Menos pesos significan menos capacidad para almacenar datos y conocimientos generales.
- Especialización: Es increíblemente bueno en matemáticas y razonamiento lógico, pero flaquea en tareas que requieren cultura general o matices complejos del lenguaje.
- Contexto: Su ventana de contexto es todavía pequeña (unos 4.000 tokens) y la atención crece de forma cuadrática, lo que dificulta procesar textos larguísimos.
Conclusión: ¿El futuro de los LLM?
HRM-Text nos demuestra que hay otros caminos más allá de simplemente añadir más capas y más parámetros. La idea de introducir bucles internos de razonamiento es fascinante y no me extrañaría ver cómo los grandes modelos empiezan a adoptar técnicas similares en el futuro cercano.