Sería genial poder introducir nuestros documentos dentro de la información que posee un chatbot, como ChatGPT, para obtener respuestas más personalizadas. Si bien no es posible hacerlo de forma directa hay una manera de incluir la información de estos documentos en lo que le pedimos a nuestros chatbots. Este sistema se conoce como «Retrieval Augmented Generation».
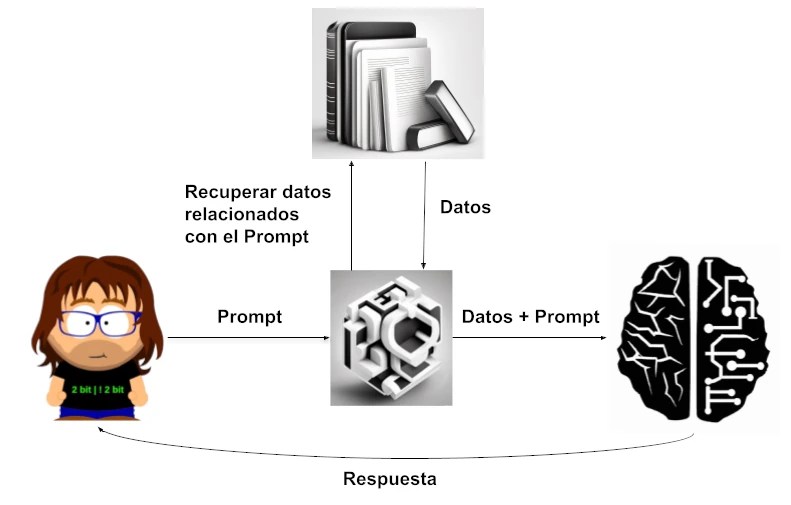
Este sistema funciona con cuatro pasos:
- El usuario escribe el prompt y lo envia.
- El prompt, en lugar de ir directamente al chatbot, pasa por un sistema que partiendo del texto del prompt y buscando en una base de datos o de documentos, recupera información relevante sobre este prompt.
- Incluye los fragmentos más relevantes de estos documentos como contexto del prompt y se envía al chatbot que procesa esta petición.
- El chatbot genera una respuesta y la devuelve al usuario
El paso dos se puede realizar de múltiples maneras, algo muy habitual es usar los embeddings de los documentos para realizar una búsqueda por proximidad con el embedding del prompt. El problema que tiene esto es que generar embeddings suele ser muy costoso. Por lo tanto se pueden usar otros sistemas que en muchos casos pueden funcionar mejor. Por ejemplo, si tú ya tienes una base de datos organizada o ya tienes los documentos estructurados, una simplemente búsqueda por palabras relevantes o como tf-idf que son algoritmos clásicos y bien usados pueden dar resultados tan buenos o incluso mejores como una búsqueda usando embeddings.
Se podría pensar que entrenar un chatbot con los datos que tiene nuestros documentos
podría ser una mejor solución. El problema es que entrenar un chatbot puede llevar muchísima cantidad de tiempo, mientras que simplemente tener los documentos y usar algún algoritmo de búsqueda o preprocesar estos para algún algoritmo de búsqueda simple puede ser bastante menos costoso, además de que podemos tenerlo optimizado prácticamente en tiempo real, cosa que si tuvieramos que entrenar un chatbot sería imposible, ya que ahora mismo entrenar un chatbot requiere bastantes horas, incluso días.
Hay que tener cuidado con este sistema, aunque los documentos sigan en tu local, estás enviando parte de los mismos al chatbot, en el caso de que sean chatbots en una nube de terceros. Hay que tomar las medidas adecuadas para evitar filtraciones.
Configuración de documentos locales en GPT4All
Si queremos probar en local esta técnica podemos usar GPT4All siguiendo los siguientes pasos:
- Descargue e instale la última versión de GPT4All Chat desde el sitio web oficial de GPT4All.
- Una vez instalado, abra la aplicación y diríjase a la pestaña de Configuración (la rueda dentada).
- En la sección de Configuración, busque la opción denominada «LocalDocs» y haga clic en ella. A continuación, deberá configurar una colección o carpeta en su computadora que contenga los archivos a los que desea que su chatbot tenga acceso. Puede crear una nueva carpeta o utilizar una existente. Es importante destacar que puede modificar el contenido de esta carpeta en cualquier momento según sus necesidades, estos cambios se reflejaran automáticamente en los datos que se pasan al chatbot.
- Ahora, puede iniciar una sesión de chat , en la parte superior derecha de la interfaz, encontrará un icono que representa una base de datos.
- Haga clic en este icono y aparecerá un menú desplegable donde podrá seleccionar la colección que desea que su chatbot conozca durante esa sesión de chat .
Si durante la conversación en el prompt haces referencia al contenido de los documentos en local en el resultado se mostrará una cita a los datos extraídos.
Puedes ver un vídeo con ejemplos en mi canal de Youtube:


Pingback: Crea un asistente para consultarle dudas de tus proyectos de software | Construyendo a Chispas