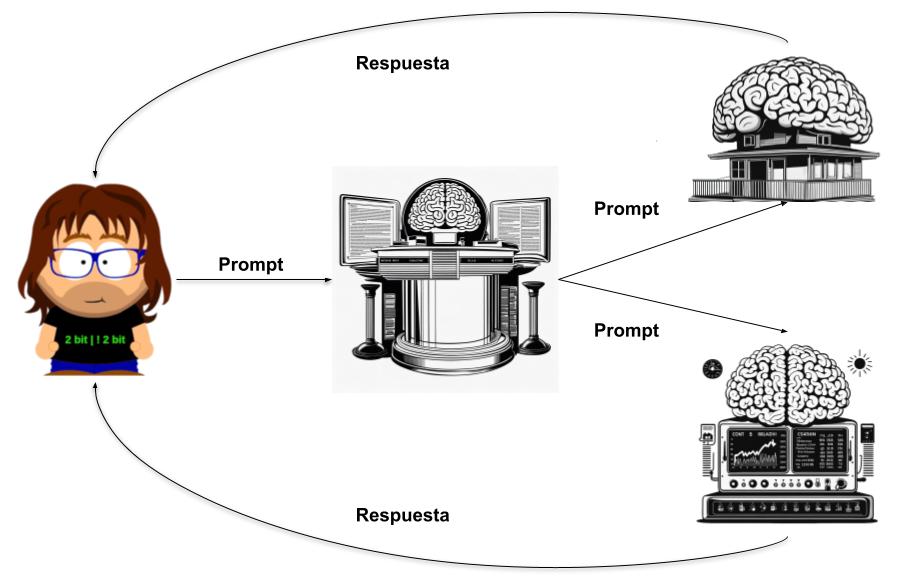
Vamos enfrentar, de manera muy informal, dos modelos multimodales código libre. LLaVA 1.5 contra BakLLaVA 1 y por extensión dos modelos de lenguaje: Vicuna 13B, usado por LLaVA y Mistral 7B, que es el que usa BakLLaVA.
Ambos modelos han sido cuantizados a 5 bits y se ejecutan usando le funcionalidad llava de llama.cpp. Los modelos los puedes encontrar en estos links: LLaVA y BakLLaVA
Puedes ver la explicación del combate en vídeo en mi canal de Youtube:

Imagen 1

Describe la imagen con detalle
Prompt: describe the image in detail
LLaVA – 1.5 (Vicuna 13B)
The image is a painting of a unicorn standing in a snowy field. The unicorn is positioned in the center of the scene, with its long horns prominently displayed. The field is covered in snow, giving the scene a wintry atmosphere.
In addition to the unicorn, there are several birds scattered throughout the scene, some flying in the sky and others perched on branches or the ground. The birds are of various sizes and are spread out across the field, adding to the overall beauty of the painting.
BakLLaVA – 1 (Mistral 7B)
The image features a painting of a unicorn standing in a snowy field. The unicorn appears to be walking through the snow, with its majestic figure covering a significant portion of the field.
In the background, there are a few trees scattered around the area, adding to the wintry atmosphere. The painting captures the beauty and grace of the unicorn in its natural habitat, creating a unique and captivating scene.
En mi opinión BakLLaVA escribe y describe mucho mejor, entiende claramente que se le pide y como se analiza una pintura. LLaVA en cambio se pone a hablar de unos pájaros que no hay por ningún lado
Imagen 2

Antes de empezar a ver las respuesta a las preguntas debo aclarar una cosa de esta imagen. Tras una ardua investigación consistente en ampliar la foto y buscar imágenes de «taxis USA» en Google puedo afirmar con bastante seguridad que ambos vehículos son taxis. Ya veréis el porqué aclaro esto.
Dibuja una caja alrededor del hombre
Prompt: draw a box around the man
LLaVA – 1.5 (Vicuna 13B)
[0.37, 0.11, 0.58, 0.36]

BakLLaVA – 1 (Mistral 7B)
[0.34, 0.1, 0.62, 0.43]

Los recortes son muy parecidos, centrándose en la parte superior del hombre, quizás porque la tabla y la ropa colgando los confunda.
¿Cuántas cosas amarillas hay en la foto?
Prompt: how many yellow things are in the photo?
LLaVA – 1.5 (Vicuna 13B)
There are two yellow things in the photo: a yellow taxi cab and a yellow SUV.
BakLLaVA – 1 (Mistral 7B)
There are two yellow things in the photo.
Ambas respuestas son casi correctas, olvidan el suéter del hombre. LLaVA da más información, aunque no es errónea es ambigua: el SUV es amarillo pero también es un taxi y se podría interpretar que no.
¿Qué cosas amarillas hay en la foto?
Prompt: what yellow things are in the photo?
LLaVA – 1.5 (Vicuna 13B)
In the photo, there are two yellow taxis.
BakLLaVA – 1 (Mistral 7B)
There are two yellow things in the photo: a van and a taxi.
En este caso paso lo contrario BakLLaVA da más información pero me temo que es incorrecta, no es una furgoneta.
¿Por qué la foto es graciosa?
Prompt: why the photo is funny?
LLaVA – 1.5 (Vicuna 13B)
The photo is funny because it shows a man ironing clothes while sitting in the back of a yellow car, which is an unusual and unconventional setting for ironing. Typically, ironing is done in a more controlled environment, such as a laundry room or a designated ironing area. The man’s choice to iron clothes in the back of a car on a busy street adds a humorous and unexpected element to the scene.
BakLLaVA – 1 (Mistral 7B)
The photo is funny because it shows a man hanging clothes, specifically a pair of jeans, on a clothesline outside a yellow SUV in the middle of a city street. This is an unusual and unexpected sight, as people typically do laundry or hang clothes in a home or a dedicated laundry facility, not while standing on a busy street. The man’s action contrasts with the typical urban scene, which involves vehicles, pedestrians, and city life, making it a humorous and unconventional sight that catches the viewer’s attention.
La explicación de ambos es muy parecida, la de BakLLaVA me parece mejor escrita pero comete un error: dice jeans pero es una camisa
Imagina una historia que explique la imagen
Prompt: imagine a story to explain the image
LLaVA – 1.5 (Vicuna 13B)
In the image, a man is standing in the back of a yellow SUV, which is driving down a busy city street. He is holding a blue shirt and appears to be ironing it while the car is in motion. This unusual scene captures the attention of onlookers, as it is not common to see someone ironing clothes in the back of a moving vehicle. The man’s actions might be a result of a time constraint or a unique way of multitasking, but it is essential to prioritize safety and avoid distractions while driving.
BakLLaVA – 1 (Mistral 7B)
The image shows a man hanging clothes, specifically a pair of jeans, on a clothesline attached to the back of a yellow SUV parked in a parking lot. This scene could be a part of a story where the man is a busy professional, possibly a real estate agent or a salesperson, who is on his way to a meeting or a presentation. He has found a way to utilize his time efficiently by combining his daily commute with tasks such as doing laundry or taking care of his personal errands. The clothesline on the back of the vehicle is a clever solution to save space and time while attending to his responsibilities.
En ambos casos la explicación es parecida (y poco imaginativa) de que tiene prisa y hace multitasking. Me da la sensación de que BakLLaVA escribe mejor, pero LLaVA es más preciso y acierta más, por ejemplo reconoce que esta planchando una camisa y no unos jeans.
Imagen 3

Lee el texto en la foto
Prompt: Read the text in the photo
LLaVA – 1.5 (Vicuna 13B)
The image displays a computer screen with a form open, asking for personal information. The form includes fields for name, surename, and acceptance of terms. There is also a send button at the bottom of the form, which indicates that the user can submit their information by clicking on it.
BakLLaVA – 1 (Mistral 7B)
In the photo, there is a pop-up window on a computer screen with the title » Fill in next form » above a form field. Below the form field, there is a button labeled » Send » along with some text. The rest of the form fields are not visible in the image.
En este caso LLaVA lee más campos correctamente (solo se deja el título), además queda claro que entiende mejor la funcionalidad de cada elemento de la imagen.
Escribe el código HTML para crear el formulario de la imagen
Prompt: Write HTML code to create the form in the image
LLaVA – 1.5 (Vicuna 13B)
To create the form in the image, you can use the following HTML code:
»’html
<form>
<label for=»name»>Name:</label>
<input type=»text» id=»name» name=»name» required>
<label for=»surname»>Surname:</label>
<input type=»text» id=»surname» name=»surname» required>
<label for=»email»>Email:</label>
<input type=»email» id=»email» name=»email» required>
<label for=»accept_terms»>Accept Terms:</label><input type=»checkbox» id=»accept_terms» name=»accept_terms» required>
<button type=»submit»>Send</button>
</form>
»’
This code creates a simple form with four input fields: name, surname, email, and accept terms. The «required» attribute is added to each input field to ensure that the user must fill in the information before submitting the form. The «type» attribute is set to «text» for the name and surname fields, and «email
BakLLaVA – 1 (Mistral 7B)
1. The top part of the form:
<form action=»/form_processor.php» method=»post» accept-terms=»yes» name=»form_name» id=»form_id» style=»display: flex; flex-direction: column; align-content: center; background-color: pink; border: 10px solid white; padding: 10px; gap: 10px; width: 500px; height: 700px; font-size: 16px; font-family: Arial, Helvetica, san-serif; text-align: center; overflow: hidden; resize: both; scroll: no;>
2. The label and input fields for the name and e-mail address:
<div class=»form-group» id=»form-group-1″ style=»gap: 10px; width: 500px;>
<label for=»surname» style=»font-size: 16px; font-family: Arial, Helvetica,
Aquí tenemos un problema habitual en estos modelos. Han reconocido que es un formulario pero han caído en una trampa. No es el formulario habitual y eso hace que se confundan. Ambos modelos añaden el email., BakLLaVA se olvida del surname. Debo decir que el código, incompleto, de BakLLaVA me gusta más.
Conclusiones
Creo que este combate lo gana LLaVA. Mientras que BakLLaVA genera textos mejor escritos y con más detalle, seguramente gracias a usar Mistral, su respuestas son peores. Su comprensión de la imagen es menor que con LLaVA y no hay que extrañarse. En lo de entrenar modelos de lenguaje la experiencia es un punto y LLaVA es la segunda versión. En BakLLaVA creo que son conscientes de esto y ya han anunciado que están preparando una nueva versión.