Vamos a ver como usar juntos varios pequeños modelos de lenguaje que aprendimos a crear en este otro post.
Básicamente hay tres arquitecturas:
LLM en linea

En este caso el prompt pasa por el primer modelo que lo trata y lo usa para generar el prompt que pasa al segundo modelo. Es un sistema muy habitual y ya lo hemos visto en otros post: Autotune para escritores, Integrar tus documentos en tus conversaciones con un chatbot Si queréis ver un ejemplo de funcionamiento podéis recurrir a ellos.
Esta arquitectura es útil para añadir las ventajas de varios modelos. Por ejemplo GPT4 lo usa para crear prompts para DALL-E 3. Si le pides que cree una imagen puedes ver como genera varios prompts para usarlos con DALL-E 3
Varios LLM en paralelo
Esta arquitectura se basa en tener varios modelos que pueden recibir tu prompt simultáneamente pero solo se tiene en cuenta la respuesta de uno de ellos. Hay dos formas de montar este sistema:
Selección de la mejor respuesta
En este caso podemos usar varios modelos de lenguaje o varias instancias del mismo modelo. Se parte de un único prompt que se pasa en paralelo a estos modelos. La respuestas son juzgadas ya sea por otra IA o por una algoritmo más convencional para quedarse con la mejor de todas.

En nuestro caso partimos del modelo que ya entrenamos en otro post. Este modelo esta pensado para controlar la domótica de una casa, se le pasa una petición del usuario en formato texto y la respuesta llega en forma de comando que indica que aparato de la casa hay que apagar o encender. El problema que tiene es que no siempre devuelve el comando correcto, por eso vamos a usar tres instancias el mismo y a quedarnos con el comando que devuelvan dos al menos dos de ellas (el típico sistema de votación).
Para ello usaremos el comando batched de llama.cpp que permite ejecutar en paralelo el mismo prompt sobre un único modelo de lenguaje, aunque con la pega de que divide el contexto entre cada una de las instancias. En este caso pasaremos el prompt a 3 instancias:
./batched ./ggml-onoff-256x8x16-f32.gguf \
"<s> [ORDEN] apaga la luz del salon [COMANDO]" 3
...
sequence 0:
<s>
[ORDEN] apaga la luz del salon
[COMANDO] LUZ_SL OFF
</s
sequence 1:
<s>
[ORDEN] apaga la luz del salon
[COMANDO] LUZ_SL ON
</s>
sequence 2:
<s>
[ORDEN] apaga la luz del salon
[COMANDO] LUZ_SL ON
</s>
Podemos ver que responde dos comandos LUZ_SL ON y uno LUZ_SL OFF por lo tanto elegiríamos LUZ_SL ON
Seleción del mejor modelo a partir del prompt
Es el mismo esquema que el modelo anterior pero «al revés» primero pasamos por el selector que elige a que modelo enviar el prompt.
En este ejemplo vamos a tener tres modelos. Uno de ellos es el que controla la domótica, otro que responde el tiempo que hace (este no existe realmente pero para el caso da igual) y un último que actúa como discriminador eligiendo a que modelo se le pasa cada prompt.
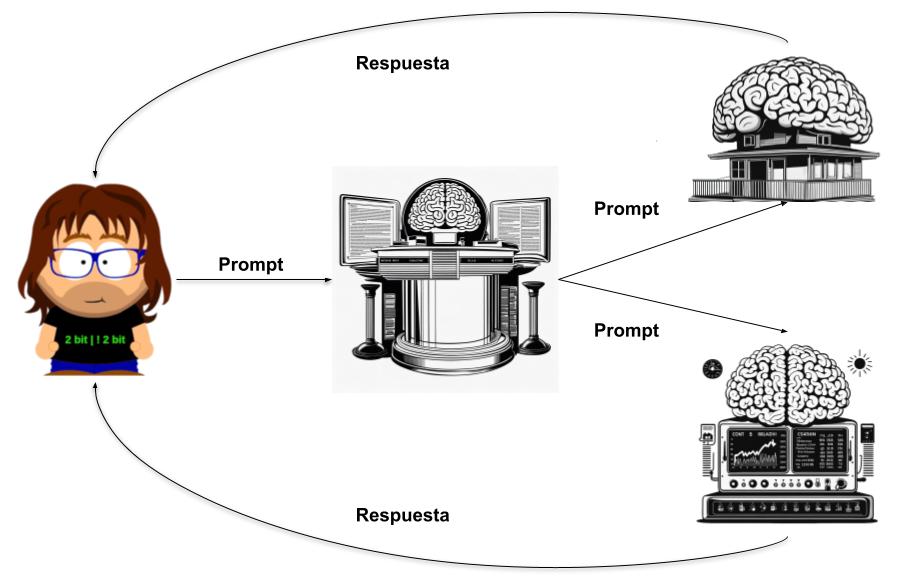
Vamos a ver como entrenamos el modelo discriminador. Para ellos crearemos un fichero de entrenamiento con un millón de prompts (medio millón de cada modelo). Con el entrenaremos un modelos al que le pensamos el prompt del usuario y nos dice que modelo es el más adecuado para ocuparse de él: LLM1 (domótica) o LLM2 (tiempo)
Un ejemplo del fichero de entrenamiento:
<s>
[ORDEN] oye activa led de la salon
[COMANDO] LLM1
</s>
<s>
[ORDEN] hey como es el dia en la calle
[COMANDO] LLM2
</s>
El comando usado para entrenar este modelo:
./train-text-from-scratch \
--vocab-model ./models/llama-2-13b.Q4_K_M.gguf \
--ctx 64 --embd 256 --head 8 --layer 16 \
--checkpoint-in chk-select-256x16x32.gguf \
--checkpoint-out chk-select-256x16x32.gguf \
--model-out ggml-select-256x16x32-f32.gguf \
--train-data "sentencias2LLM.txt" \
-t 6 -b 64 --seed 1 --adam-iter 1024
Vamos ha probarlo
./main -m ggml-select-256x16x32-f32.gguf -r "</s>" \
-p "<s>\n [ORDEN] apaga la luz del salon\n [COMANDO]"
....
<s>
[ORDEN] apaga la luz del salon
[COMANDO] LLM1
</s>
./main -m ggml-select-256x16x32-f32.gguf -r "</s>" \
-p "<s>\n [ORDEN] que tiempo hace\n [COMANDO]"
...
<s>
[ORDEN] que tiempo hace
[COMANDO] LLM2
</s>
Puede ver todo esto en funcionamiento en el siguiente vídeo de mi canal de Youtube:

