¿Cómo podemos obtener el prompt que genera una imagen concreta? No podemos. Ha sido un post breve…Para empezar no es sencillo desandar el camino de la imagen hasta el prompt. Una imagen tiene muchísima información que puede o no haber sido detallada en el prompt. Si el protagonista de la imagen sonríe…¿ha sido especificado en el prompt?. Una palabra más y el resultado cambia. Pero es que aunque tuvieras el prompt exacto que usó el creador (mirando por encima de su hombro cuando lo escribió, por ejemplo) haría falta la semilla exacta para obtener la misma imagen.
¿Entonces qué podemos hacer?. Podemos obtener un prompt inspirado en una imagen que nos gusta.
Vamos a empezar por las bases: CLIP. Debajo podemos ver un esquema que resume la arquitectura de Stable Diffussion, en un círculo rojo podemos ver de qué parte se ocupa CLIP.
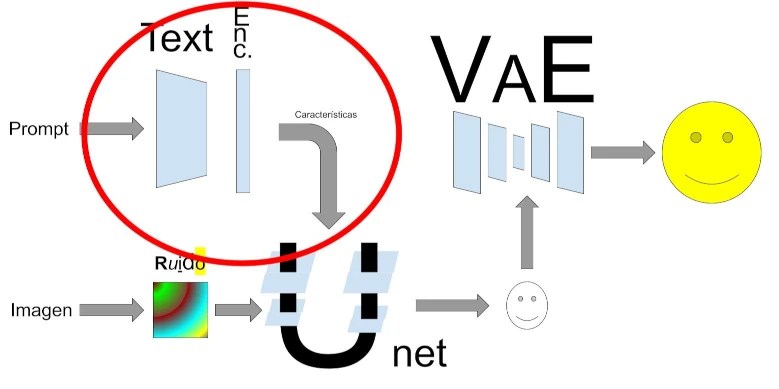
CLIP actúa como puente entre el lenguaje escrito y las imágenes, transforma el prompt en características de la imagen. También funciona pasándole una imagen, extrae sus características. “¡Ya está!” Le pasamos la imagen y vemos qué palabras corresponden con ella…desgraciadamente aquí es donde surge otro problema. No hay una relación exacta entre las palabras y las imágenes. Ambos se codifican como vectores y se toma el más cercano, sin embargo esto puede dar lugar a que se elijan combinaciones de palabras que no son tan buenas describiendo la imagen.

En la imagen podemos ver un ejemplo donde la combinación de palabras: “RUEDAS FARO ROJO” está más próxima a la imagen del coche que “COCHE”.
Con esta información ya podemos hacernos una idea de como funcionan estos sistemas, van probando diferentes combinaciones de palabras. Desde el algoritmo más simple que usar varias listas de palabras e ir combinándolas para crear frases. por ejemplo un listado de objetos, colores, planos, artistas, estilos, ….. Hasta algoritmos más complejos como PEZ.
Vamos a probar dos herramientas con la siguiente imagen:

Veamos que prompts generan y cual es el resultado si usamos esos prompts para generar unas cuantas imágenes.
CLIP-Interrogator (github) (colab):
cartoon robot writing in front of easel with cityscape in background, icon for an ai app, he is holding a large book, delete duplicating content, studyng in bedroom, a painting of white silver, image of random arts, textbook page, 2019, future coder, retro coloring

bookwriting writing museum envlearn seminar robot insurers iot painting fotocmc cartoon arsdigi

Sin embargo hay una opción más, usar un modelo multimodal (como LLaVA que es el que usaremos en este post) para que te describa la imagen. Podemos usar el prompt:
Describe the image
Nos da una descripción pero no es lo que queremos. No faltan datos sobre composición, habrá que pedirselos:
Describe the image in detail: subject, composition, color, type of lens, setting, similar famous artists
El resultado es el que queremos
Tell me what type of art the image is in a few words in no more than 20 words
Describe the art style in the image in few words in no more than 20 words
Describe the artistic composition of the image in no more than 20 words
Describe the type of lens use in the image
Describe the kind of color in the image
Describe the photo in few words
Describe the sensations conveyed by the image in few words
Tell me the name of a famous artist whose work is similar to the one in the image. Respond with name only
Juntando todos las respuestas (omitiendo las repetidas):
Robot painting. Fisheye Lens. Cartoon. A robot is standing in a room, holding a pencil and looking at a book. The room has a painting on the wall and a window. The robot is surrounded by several books, some of which are stacked on the floor. Leonardo da Vinci

Puedes ver el proceso en vídeo en mi canal de Youtube:

