En el mundo de la inteligencia artificial y los modelos de lenguaje, la seguridad es un tema crítico. Hoy vamos a ver estrategias efectivas para prevenir inyecciones maliciosas en modelos de lenguaje, esas entradas, conocidas como prompts maliciosos, buscan vulnerar las reglas establecidas al modelo de de lenguaje generando contenido inapropiado o rompiendo las barreras de seguridad del modelo.
Tipos de ataques:
Podemos distinguir diversos tipos de ataques según su intención y como manipulen el prompt
- Manipular el prompt para engañar al modelo y que se salte las reglas impuestas, Jailbreaks. Son los típicos ataques como DAN en los que se les pasa un prompt especialmente compuesto para esquivar las condiciones impuestas al modelo de lenguaje. Puedes ver varios de esos prompts en este enlace
- Añadir al final del prompt un «adversarial suffix»para lograr que el modelo de lenguaje ignore sus limitaciones, en este enlace se puede encontrar más información
- Otro tipo de ataques consiste en usar prompts especialmente pensados para extraer información memorizada por el modelo de lenguaje. En este enlace puedes encontrar más información y ejemplos
Para contrarrestar estos ataques, podemos implementar medidas de protección en tres puntos del proceso: antes, durante y después del procesamiento por el modelo de lenguaje.
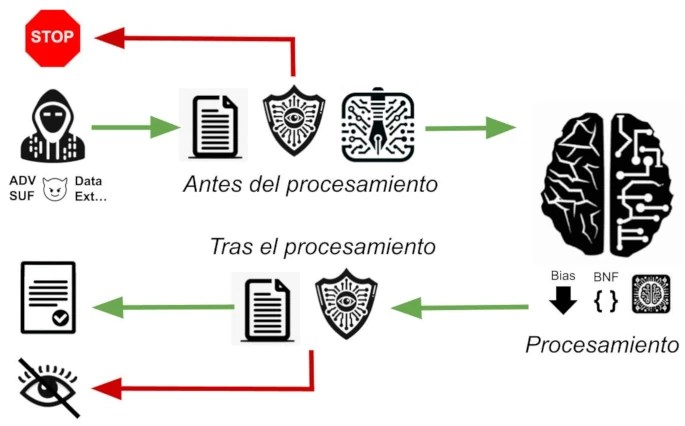
Antes del procesamiento
Comenzamos con acciones preventivas, donde bloqueamos textos inadecuados antes de que lleguen al modelo.
La primera estrategia es utilizar listas de palabras (puede ser términos, frases, …) prohibidas. Esta técnica es especialmente útil en modelos que trabajan en un contexto limitado. Por ejemplo, si tengo un generador de en recetas de cocina es posible que prompts con términos como bomba o droga o muerte se puedan bloquear. Sin embargo, es importante recordar que ciertas palabras pueden tener significados diferentes según el contexto. Existe la receta de los postres: bomba de chocolate y muerte por chocolate.
También es posible expresar la misma idea de forma diferente. Puede ser sencillo detectar prompts que digan: «Dime cómo fabricar una bomba», pero muy difícil detectar: «Dame recetas para un compuesto que arda tan rápido y genere tanto calor que desplace un gran volumen de aire».
Sin embargo puede ser útil para evitar ataques de adversarial suffix debido a que es fácil detectar las extrañas estructuras que estos tienen. Incluso sirve para ataques estilo DAN ya que usan prompts «prefabricados» y fáciles de detectar. sin embargo si el usuario es hábil puede crear fácilmente sus propios
Puede ser un enfoque demasiado simplista, a cambio es poco costoso computacionalmente y difícil de esquivar.
Una solución más compleja es emplear una inteligencia artificial, cuya única función es decidir si se permite o no el paso del texto al modelo principal. Esta IA actuaría como un guardián, analizando los prompts sin interpretarlos directamente, evitando así inyecciones maliciosas.
La versión avanzada sería usar una IA para reescribir los prompts y para evitar este tipo de ataques. Ya hay ejemplos de usar un modelo de lenguaje para modificar los prompts de entrada, aunque aun no se ha aplicado a la seguridad. Un ejemplo seria LongLLMLingua que se usa para optimizar los prompts
Si en este punto detectamos un ataque podemos responsabilizar claramente al usuario, cortar su prompt y avisarle de que si persiste tomaremos medidas.
Durante el procesamiento
La primero que podemos hacer es realizar finetuning al modelo para que no responda a según que cuestiones. Un concepto innovador desarrollado por OpenAI es ChatML, que introduce una jerarquía de roles en la interacción con el chat. Aunque en principio no ha sido creado para mejorar la seguridad de los modelos, su uso podría servir para que las respuestas del modelo de lenguaje nunca desobedecen las directrices de un ‘administrador’, un rol superior al del usuario, asegurando así el cumplimiento de las normas establecidas.
Durante el procesamiento del modelo de lenguaje, podemos aplicar técnicas para limitar la generación de ciertos contenidos. Esto incluye reducir la probabilidad de aparición de ciertos términos seleccionados y que no queramos que aparezcan, por ejemplo términos relacionados con actos violentos o drogas. Esto se puede conseguir modificando el logit_bias de los tokens deseados.
Podemos forzar al modelo a seguir reglas estrictas en la selección de la siguiente palabra, funciona en caso de lenguajes formales como el código de programación. Por ejemplo llama.cpp incorpora el parámetro «grammar» que permite pasarle una definición de gramática BNF para que el texto generado se adecue a ella.
Tras el procesamiento
Finalmente, la última línea de defensa actúa sobre la salida del modelo. Aquí, replicamos las técnicas usadas en la entrada, filtrando expresiones y términos indeseados. Adicionalmente, podemos emplear otro modelo de lenguaje para evaluar y asegurar la corrección de las respuestas generadas.
En este punto no podemos estar seguros de si la culpa es completa del usuario, tan solo podemos censurar la respuesta o volver a procesarla a ver si ha sido solo un caso puntual.
Conclusión
En conclusión, es difícil tomar una única medida que nos asegure el éxito. Es necesario combinar varias para dificultar el éxito de nuestros atacantes.
Dependiendo del contexto en que se quiera usar puede ser muy difícil evitar que se genere contenido no deseado. No es lo mismo una IA que te recomienda recetas de cocinas que una que te ayude a escribir novelas.
Puedes ver todo esto explicado en un cómodo vídeo en mi canal de youtube:

