No se vosotros pero últimamente he estado viendo montón de anuncios, artículos y titulares que hablan del prompt engineering y parecen reducirlo a saber unos poco trucos. No digo que esos trucos no sean útiles para hacer buenos prompts, pero los prompts son solo una parte de todo lo que puedes configurar en un modelo del lenguaje para conseguir los resultados que deseas.
En la siguiente imagen se puede ver el proceso de funcionamiento de un modelo de lenguaje con cada una de las partes que se vamos a ver:
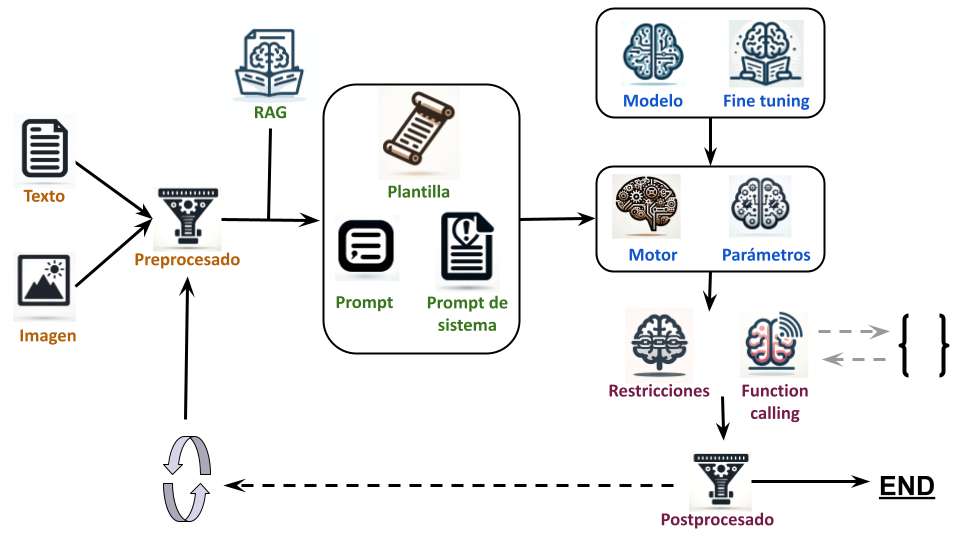
Elegir modelo y motor:
- Elegir modelo: Para elegir el modelo necesitamos saber cuanta memoria VRAM tenemos (o podemos permitirnos). Como truco de calculo podemos aproximar que por cada parámetro el modelo ocupa 4 bytes (32 bits). Así que un modelo de 30B ocupa unos 120GB de memoria VRAM. Hay opciones como los modelos cuantizados, que bajan la precisión de cada parámetro. Por ejemplo si la bajas de 32 a 16 bits el modelo ocuparía la mitad. A cambio el modelo empeora. ¿Es mejor un modelo de 30B cuantizado a 4 bits, uno de 15B cuantizado a 8 bit, uno de 7B cuantizado a 16 bits o uno de 3,5B sin cuantizar? Todos ocupan casi lo mismo.
Otra característica importante del modelo es para que está entrenado, básicamente puede estar entrenado para completar texto, seguir ordenes o chatear. Esto afecta a como va a interactuar con el usuario y como se van a escribir los prompts.
Ademas es importante saber en que idiomas funciona el modelo y si ha sido entrenado o «finetuneado» con datos que necesitas, por ejemplo: un modelo entrenado para programar.
No hay que olvidar la posibilidad de la multimodalidad (audio, voz, imágenes, vídeo, …) - Elegir motor: Una vez elegido el modelo habrá que elegir el motor para ejecutarlo. Dependerá básicamente de tres cosas: las características del modelo (familia y cuantización), de la API que necesitemos (servidor, librería, lenguaje de programación,…) y del hardware donde vaya a ejecutarse (GPU, CPU, RAM, VRAM)
- Parámetros: Al ejecutar un modelo en el motor hay diferentes parámetros (dependen del motor y el modelo). Al configurarlos podemos obtener diversos resultados, un modelo más o menos original o coherente, variar las probabilidades de algunas palabras, sacrificar calidad por velocidad, …
- Fine tuning: Si no se encuentra el modelo adecuado habrá que plantearse adaptar uno existente con fine tuning
Preprocesado
- Preprocesado: Antes de enviar el texto al modelos habrá que tener en cuenta si es necesario procesarlo, cosas como: censurarlo, darle formato, traducirlo, …
- Texto: Los datos en formato texto sobre los que vamos a trabajar
- Multimedia: Si el modelo es multimodal no solo tendremos datos en forma de texto, también tendremos otro tipo de datos. Por supuesto habrá que preprocesar esos datos también.
Procesado:
- RAG: Si queremos incluir documentos o información externa relacionada con el prompt podemos usar RAG. Para usar esta técnica tenemos que tomar varia decisiones: el algoritmo que se usa para elegir los documentos (puede ser necesario elegir otro modelo de lenguaje), el tamaño de los bloques que se van a elegir, como estos documentos se van a procesar para crear esos bloques, ….
- Plantilla para el prompt: Hay que definir la plantilla que va a usar el modelo del lenguaje, vendrá definida por el entrenamiento y fine tuning del modelo de lenguaje.
- Prompt de sistema: Aquí empieza ya la magia del prompt. Este es el prompt inicial que se le pasa al modelo describiendo su rol , comportamiento y funciones. Es importante definir lo correctamente
- Restricciones: No tenia muy claro como llamar esta parte. Consiste en limitar la salida de texto a unas reglas definidas. Por ejemplo, usando expresiones regulares o gramáticas BNF. Sirve para obligar a que la respuesta tenga un formato concreto.
- Function calling: Al modelo se le pueden pasar la descripción y firma de diversas funciones de código y, si esta entrenado para ello, puede invocarlas eligiendo los parámetros para las mismas.
- Prompt: ¡Por fin! Aquí está el famoso prompt, el texto del prompt ha de integrar los demás datos y funcionalidades, describir correctamente lo que deseamos que el modelo de lenguaje haga.
En muchos casos el prompt tiene varios pasos y es necesario pasar varias veces por el LLM para procesarlo.
Postprocesado:
- Postprocesado: Una vez generado el texto será necesario procesar la respuesta.
- Iteraciones extras: Hay flujos de trabajo que se dividen en varias iteraciones o pasos, sigues alguno de estos es posible que tengas que plantearte modelos para los siguientes pasos o
- Function calling: Si se determina que hay que llamar a alguna función, este es el punto donde se le llama y se procesa la respuesta.
Es te flujo ha de considerarse un resumen simplificado. Hay más opciones y técnicas, pero aqui se recogen prácticamente las mínimas a usar hoy en día.
¿Y por qué te has centrado en modelos de lenguaje y no otras IA generativas que usan prompts como las que generan imágenes? Por que los modelos de lenguaje son sencillos. Por ejemplo, Stable Difussion tiene tantas formas de alterar su funcionamiento y resultados que no se si seria capaz de citar las más usadas.
Puedes ver un vídeo explicativo en mi canal de Youtube:

