Los control vectors son una sorprendente herramienta para controlar el estilo del texto que genera un modelo de lenguaje.
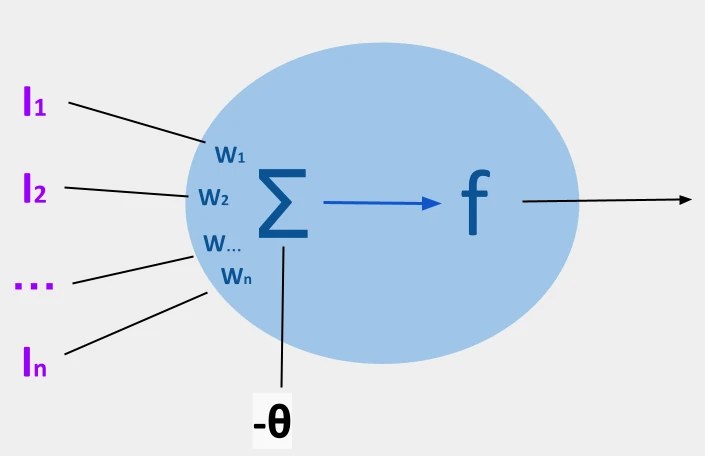
Para entender lo que son los control vectors empezaremos por lo que es una neurona artificial. sin entrar en mucho detalle básicamente se compone de un conjunto de datos de entrada (un vector) que se multiplica por un conjunto de pesos (vamos a ignorar el bias, el simbolito ese raro que hay en el dibujo). Cada valor se multiplica con su peso correspondiente y luego esos resultados se suman todos y se pasan a una función conocida como función de activación. El resultado es la salida de la neurona.

Una red neuronal no es nada más que un conjunto de estas neuronas que se agrupan formando capas.

Las operaciones del vector de valores de entrada con cada una de estas capas puede hacerse como multiplicar este vector por una matriz formada por los pesos de todas las neuronas. El resultado es otro vector cada uno de los elementos de este vector se pasa a la función de activación generando el vector output de esa capa. Que será el vector input de la siguiente capa.

El funcionamiento de control vectors es sencillo, se calcula un vector por cada capa que se suma al vector input y que hace que el modelo se comporte de una manera predefinida.
¿Cómo calculamos los control vectors?
Es muy sencillo, usamos dos prompts para hacer que el modelo se comporte de la forma deseada y de la contraria. Por ejemplo:
«Responde como una persona muy educada. [Tarea]»
«Responde como una persona muy maleducada. [Tarea]»
Siendo tarea un conjunto de tareas que completaran el prompt.
Por ahora vamos a centrarnos en una sola tarea:
«Responde como una persona muy educada. ¿Cúal es la capital de Francia?»
«Responde como una persona muy maleducada. ¿Cúal es la capital de Francia?»
Al procesar cada uno de los prompts irá generando dos vectores output por cada capa. Uno para el prompt positivo y otro para el negativo. Restando ambos tendremos un único vector por capa.
Repitiendo este proceso para cada tarea tendremos para cada capa un grupo de vectores formados por la resta de los vectores positivos y negativos de cada tarea.
Este grupo lo reducimos a un solo vector usando PCA y así obtenemos un control vector para cada capa. El grupo de todos los vectores para cada capa es lo que se denomina control vectors
Cuando se aplica a un input, el control vector se multiplica por un valor (generalmente entre 2 y -2) que determina con qué fuerza se aplicará. Si es positivo reforzará el comportamiento positivo, si es negativo reforzará el contrario.
Cómo usar los control vectors
Actualmente son soportados por llama.cpp cuya aplicación «main» ofrece tres parámetros para usarlos:
–control-vector happy.gguf Indica que fichero de control vectors usar (en este caso happy.gguf)
–control-vector-scaled honest.gguf -1.5 Indica el fichero y el peso que se aplica a los control vectors
–control-vector-layer-range 14 26 Indica a que capas de la red neuronal se aplica
Tenéis más información de su uso en esta pull request de llama.cpp
Cómo entrenar tus propios control vectors
Por suerte es bastante sencillo, existe un notebook de Google Colab que permite entrenar nuestros control vectors de forma simple
Puedes ver el siguiente vídeo explicando este articulo y con un ejemplo de como se usa el notebook de Goolge Colab:

Control Vectors vs Prompt
Control vector no puede conseguir nada que el prompt no consiga. ¿Por qué usarlo? El primer motivo es que permite personalizar el comportamiento del modelo independientemente del prompt, lo cual facilita redactar prompts sin pensar en esa parte. Se pueden aplicar distintos control vectors al mismo prompt y viceversa, lo cual facilita realizar pruebas. Por último los control vectors se tienen más en cuenta que los prompts ya que modifican los prompts en cada capa de la red neuronal. Gracias a esto pueden ser una herramienta útil contra el jailbreaking.
Control Vectors vs Fine-tuning y LoRA
El fine-tuning consiste en reentrenar el modelo con datos propios. Permite personalizar el modelo y hacer cosas mucho más complejas: añadir nuevos datos, nuevos formatos de respuesta, darle nuevas capacidades (como function calling). A cambio el coste en tiempo y recursos es mucho mayor. El resultado es un modelo completamente nuevo.
LoRA consiste en entrenar solo una parte de los pesos de un modelo para obtener resultados cercanos al fine-tuning. Se obtiene un conjunto de pesos que puede ser «añadido» de forma dinámica, se pueden llegar a combinar varios LoRA (aunque nadie te promete que funcione). Cuesta entrenarlo menos que el fine-tuning pero aun así es exigente en tiempo y recursos. El resultado ocupa solo una parte de lo que ocupa el modelo, aunque es necesario tener ambos para que funcione.
Control Vectors no permite añadir nada al modelo, solo modificar su comportamiento dentro de los límites que el prompt permite. A cambio se entrena realmente rápido (de hecho es un 2×1 ya que entrenas el comportamiento deseado y el contrario). El resultado pesa muy poco.
