En esta entrada vamos a ver cómo dotar de la capacidad de entender la voz y responder con audio.
Para ello usaremos tres proyectos (realmente dos) con tres modelos diferentes:
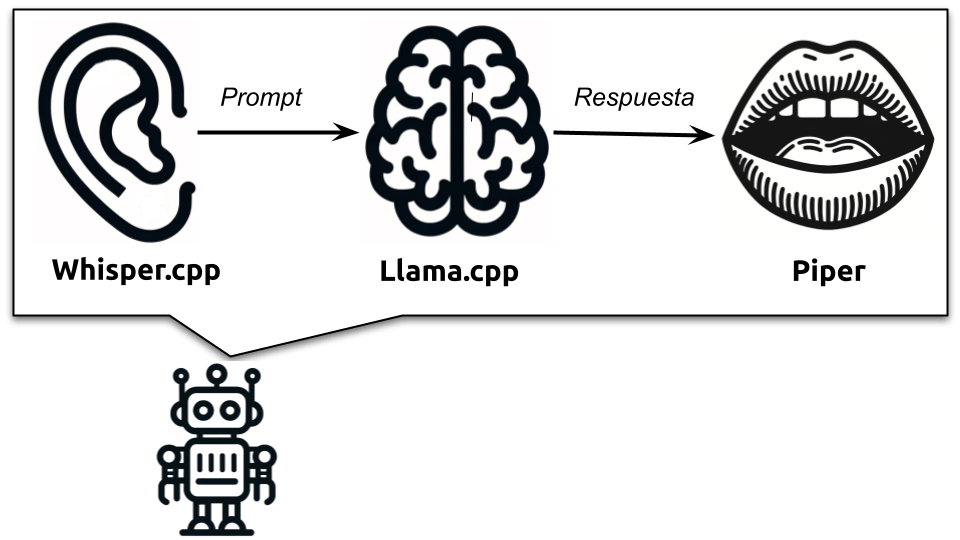
- Whisper.cpp, para convertir el audio en texto que pasaremos al modelo de lenguaje.
- Llama.cpp, como motor del modelo de lenguaje.
- Piper, para sintetizar audio a partir de la respuesta dada por el modelo de lenguaje.
Puedes ver la explicación y una demo de como funciona esto en el siguiente vídeo:

Instalar todo
Si nunca has descargado un proyecto de github o nunca has compilado un programa es posible que los siguientes pasos se te hagan cuesta arriba.
1. Descargar Whisper.cpp
git clone https://github.com/ggerganov/whisper.cpp.git
2. Construir Whisper.cpp
cd whisper.cpp
make
3. Descargar el modelo de audio a voz
Hay disponibles varios modelos:
| Modelo | Lenguaje | Espacio en disco | Memoria RAM |
|---|---|---|---|
| tiny.en | Multilenguaje | 75 MiB | ~273 MB |
| tiny.en | Inglés | 75 MiB | ~273 MB |
| base | Multilenguaje | 142 MiB | ~388 MB |
| base.en | Inglés | 142 MiB | ~388 MB |
| small | Multilenguaje | 466 MiB | ~852 MB |
| small.en | Inglés | 466 MiB | ~852 MB |
| medium | Multilenguaje | 1.5 GiB | ~2.1 GB |
| medium.en | Inglés | 1.5 GiB | ~2.1 GB |
| large-v1 | Multilenguaje | 2.9 GiB | ~3.9 GB |
| large-v2 | Multilenguaje | 2.9 GiB | ~3.9 GB |
| large-v3 | Multilenguaje | 2.9 GiB | ~3.9 GB |
A más grande sea el modelo mejor resultado da, pero al mismo tiempo más potencia y memoria necesita para funcionar correctamente. Si no vas a hablar en inglés necesitas descargar un modelo multilenguaje.
make medium
4. Construir el programa talk-llama
Es necesario incluir la librería libsdl2-dev
# Debian
sudo apt-get install libsdl2-dev
# Fedora
sudo dnf install SDL2 SDL2-devel
# Mac OS
brew install sdl2
En Windows puedes descargar el instalable de aqui
Construir:
make talk-llama
5. Descargar el modelo de lenguaje
Whisper.cpp incluye su propia versión de llama.cpp por lo que no hace falta que instalemos y compilemos este proyecto. Si que es necesario que descarguemos cualquier modelo de lenguaje de los que soporta.
Yo he usado Llama-3B-Instruct cuantizado.
Hasta este punto el programa seria funcional, escucharía del micrófono, transcribiría el audio, lo pasaría al modelo del lenguaje y este respondería.
Si estas en Windows o MacOs deberías oírlo hablar. Puedes saltar al punto 9
Si estas en Linux, continua.
6. Instalar piper
pip install piper-tts
Puede ser necesario instalar también aplay
pip install aplay
7. Descargar una voz para piper
Puedes encontrar el listado de voces aqui.
Descarga el fichero del modelo de voz que desees y el fichero de configuración. ambos tiene que ir en el mismo directorio y tienen que tener el mismo nombre, solo que el fichero de configuración.
En mi caso:
es_ES-davefx-medium.onnx
es_ES-davefx-medium.onnx.json
8. Modificar el fichero speak
El fichero se encuentra en whisper.cpp/examples/talk-llama/speak
Busca las siguientes lineas:
if installed espeak; then
espeak -v en-us+m$1 -s 225 -p 50 -a 200 -g 5 -k 5 -f $2
elif installed piper && installed aplay; then
cat $2 | piper --model ~/en_US-lessac-medium.onnx --output-raw | aplay -q -r 22050 -f S16_LE -t raw -
Eliminas las dos primeras para evitar que use espeak (es un horror, tiene la calidad de audio una trituradora de metal).
Cambias la invocación a piper cambiando el elif por if y poniendo la ruta al modelo de piper que has descargado:
if installed piper && installed aplay; then
cat $2 | piper --model ../es_ES-davefx-medium.onnx --output-raw | aplay -q -r 22050 -f S16_LE -t raw -
9 Ejecutarlo
Puedes ejecutar la aplicación talk-llama, los parámetros mínimos son:
-mw indica la ruta al modelo e whisper
-ml indica al ruta al modelo de lenguaje
-p indica el promtp inicial
-l el lenguaje, es buena idea indicarlo
./talk-llama -mw ./models/ggml-medium.bin -ml ~/llama-3-8B-Instruct-Q8_0.gguf -p "User" -l es
Debo señalar que aunque «user» no es el prompt correcto para Llama 3, pero funciona correctamente.
El principal problema es que todo el sistema esta pensado para hablar en inglés. Así que hay que indicarle de alguna forma que hable en español, puedes decirselo al principio de la conversación o puedes forzarlo con:
./talk-llama -mw ./models/ggml-medium.bin -ml ~/llama-3-8B-Instruct-Q8_0.gguf -p "Esta conversación es en español. User" -l es
El resultado
Esta conversación es en español. User: Hola, cmo ests?
LLaMA: Hola, estoy bien, gracias por preguntar.
Esta conversación es en español. User: Cul es la capital de Francia?
LLaMA: La capital de Francia es París.
Esta conversación es en español. User:
Se puede apreciar que faltan los «caracteres especiales del español» como tildes, ñ o símbolos de apertura y cierre de exclamación o interrogación.
