Hace no mucho Google sacó una herramienta que permite crear podcasts donde dos IAs discuten sobre el texto que les pasas. Meta no hace mucho sacó su propia versión usando Llama que se puede usar en local. Aquí presento mi idea, con código para que podáis jugar vosotros.
Podéis ver el vídeo con más detalles en mi canal de YouTube:

El proceso tiene varias partes:
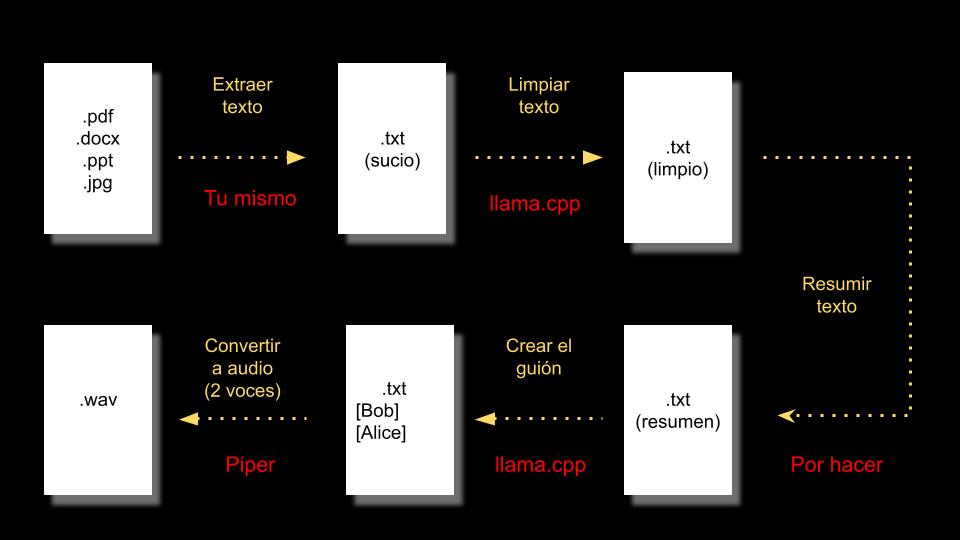
Extraer el texto:
El documento de origen puede tener una gran cantidad de formatos, para que funcione con la IA es necesario pasarlo a texto plano (txt). En este caso esa parte del trabajo os lo dejo a vosotros.
Limpiar el texto:
Es posible que el texto extraído tenga «ruido», caracteres no válidos o que no forman parte del texto principal (cabeceras, notas de pie, número de página). Los resultados son mejores si le pedimos a una IA que limpie el texto.
Resumir el texto:
Su utilidad no es solo tener un podcast más corto y «concentrado». También sirve para lograr que el texto «quepa» dentro del contexto del modelos del lenguaje.
Generar el guión del podcast:
En este caso se generará como si hablaran dos personas. Alice y Bob. Para ello pediremos al modelo de lenguaje que genere un podcast
Generar el audio:
Aquí surge el problema de cómo generar audio con dos voces. En principio con Piper podemos fácilmente usar el parámetro –json-input y un fichero en formato json, indicando la voz usada en cada línea (es necesario un fichero de voz con múltiples voces). Por desgracia es necesario crear tu propia compilación de Piper. Así que haremos algo más simple: dividiremos el texto en líneas aprovechando que cada una va precedida de la voz que lo dice (el uso de [Alice] y [Bob] no es accidental). Y generamos un fichero wav independiente para cada línea. Luego tendremos que unirlos. En mi caso uso la herramienta sox.
const fetch = require('sync-fetch')
const fs = require("fs");
const { execSync } = require('child_process');
const llamaURL = "http://127.0.0.1:8080/completion";
const tokenizerURL = "http://127.0.0.1:8080/tokenize";
const inputFilename = "./text.txt";
//Llama a llama.cpp
function CallIA(prompt, n_predict, temperature) {
console.log("Asking llama.cpp");
let response = fetch(llamaURL, {
method: 'POST',
body: JSON.stringify({
prompt,
n_predict: n_predict,
temperature: temperature,
cache_prompt: true
})
}).json().content;
return response;
}
//Consulta el tamaño en tokens del texto
function callTokenizer(text) {
console.log("Asking llama.cpp");
let response = fetch(tokenizerURL, {
method: 'POST',
body: JSON.stringify({
text,
add_special: true
})
}).json();
console.log(response.tokens);
return response.tokens.length;
}
//Limpiar texto
function generatePromptClean(text){
return "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\nRepite el texto que te voy a pasar, limpia los caracteres extraños y corrige los posibles errores\n"+text+"\n<|im_end|>\n<|im_start|>assistant\n";
}
//Resumir texto
function generatePromptSumarize(text){
return "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\nResume el texto que te voy a pasar, extrae las partes más interesantes y curiosas de él\n"+text+"\n<|im_end|>\n<|im_start|>assistant\n";
}
//Generar guion
function generatePromptDialog(text){
return "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\nConvierte el siguiente texto en una conversacion, en español, animada y divertida entre dos personas: Alice y Bob. Indica cada usuario poniendo delante [Alice] o [Bob].Comienza Alice\n"+text+"\n<|im_end|>\n<|im_start|>assistant\n[Alice]";
}
function generateAudio(text){
//Almacena listado de ficheros para concatenar con sox
var concatSox = "";
//Se separa cada linea que empieza por [
var podcastWithVoices = podcast.split("[");
for(var i = 0; i < podcastWithVoices.length; i++){
var line = podcastWithVoices[i].trim();
//Elegimos la voz Alice/Bob
var speaker;
if(line.startsWith("Alice")){
speaker = 1;
} else {
speaker = 0;
}
//Eliminamos el nombre para que no lo lea
line = line.replace("Alice]", "").replace("Bob]", "");
//Llamamos a Piper para generar el audio en un fichero .wav
execSync(`echo '${line}' | piper --model ./models/es_ES-sharvard-medium.onnx --speaker ${speaker} --output_file podcast${i}.wav`, { encoding: 'utf-8' });
//Añadimos el fichero a la lista para concatenar
concatSox += "podcast"+i+".wav ";
}
//Unimos todos los ficheros .wav
console.log(`sox ${concatSox} podcast.wav`);
execSync(`sox ${concatSox} podcast.wav`);
}
//Leer fichero de texto
var text = fs.readFileSync(inputFilename, 'utf8');
//Tokenizador calcula cuantos tokens ocupa el texto (no he logrado que funcione)
//callTokenizer(text);
//Limpiamos el texto
//text = callIA(generatePromptClean(text), 8000, 0.2)
//Resumimos el texto
//text = callIA(generatePromptSumarize(text), 8000, 0.2)
//Generamos el dialogo
//Es necesario añadir [Alice]
var podcast = "[Alice]"+CallIA(generatePromptDialog(text), 8000, 0.2);
console.log(podcast);
//Limpiamos el texto generado por la IA
podcast = podcast.replace(/(\r\n|\n|\r)/gm, "");
//Llama a piper para generar el audio linea a linea
generateAudio(podcast);
Si queréis ver (bueno, oir) el resultado, tenéis un ejemplo al final del vídeo.
