En el mundo de la inteligencia artificial, escuchar que algo puede revolucionarlo todo es casi rutina. Sin embargo, esta innovación realmente podría marcar un antes y un después en cómo funcionan los modelos de lenguaje: los Modelos de Lenguaje con Difusión (Diffusion LLMs).
¿Qué es un modelo de difusión?
Para entender esta nueva idea, hay que mirar atrás. Los modelos de difusión clásicos, como Stable Diffusion, se entrenan para limpiar ruido de imágenes de forma progresiva, guiados por un texto (prompt). Este proceso ocurre en el espacio latente y es dirigido por una red llamada UNet.
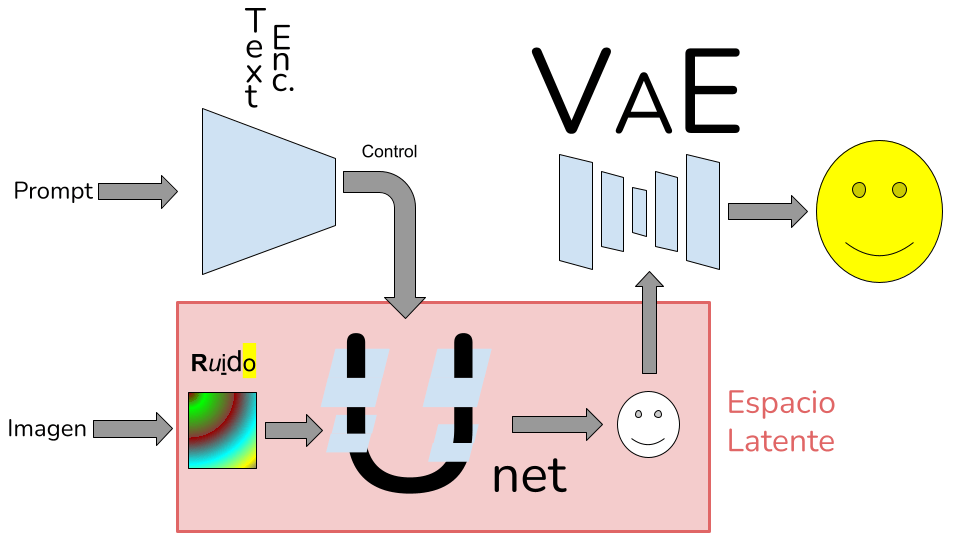
Todo cambió cuando se sustituyó esa UNet por un transformer, el mismo tipo de arquitectura que usan los modelos de lenguaje actuales. Así nació un nuevo enfoque: enseñar a transformers a eliminar ruido. ¿La clave? Estos modelos pueden generar contenido de manera no secuencial.

¿Y si aplicamos esta idea al texto?
Aquí está lo revolucionario. En vez de generar texto palabra por palabra (como hacen los LLMs tradicionales), los modelos de lenguaje con difusión generan todo el texto a la vez. Todas las palabras influyen en las demás desde el inicio, una forma más parecida a cómo pensamos los humanos.
Al no poder crear tokens de texto con ruido se crea una máscara con una entrada para token, que indica si el token es válido (desenmascarado) o ruidoso (en mascarado). Técnicamente, el proceso comienza con todos los tokens del texto enmascarados. Luego, en varias iteraciones, el modelo va desenmascarando aquellos tokens que considera más probables. Incluso puede volver a enmascarar tokens ya revelados para mejorar la coherencia general.
¿Qué modelos existen hoy?
Actualmente hay tres modelos destacados que usan esta técnica:
- Mercury (Inception Labs)
Especializado en generación de código. Es privado. Presume de su velocidad generando código frente a los LLM clásicos. - LLaDA 8B
Un modelo open source con 8.000 millones de parámetros. Tiene versión base e instruct (esta última preparada para seguir instrucciones, como en un chat). LLaDA utiliza un transformer bidireccional y un proceso iterativo de enmascarado y desenmascarado. Curiosamente, el número de iteraciones es fijo, sin importar la longitud del texto, lo que puede suponer ventajas en velocidad, aunque también plantea retos con textos largos. - Block Diffusion
Una propuesta híbrida: aplicar el proceso de difusión por bloques de tokens. Dentro de cada bloque se aplica la lógica de difusión; entre bloques, se mantiene una estructura más parecida a los LLM clásicos. Aunque esta implementación es conservadora (usa bloques pequeños y sin que se puedan volver a enmascarar tokens), tiene un gran potencial, especialmente si se amplía a párrafos u otras unidades mayores.
Pros y contras:
Los modelos de lenguaje con difusión (DLLM) presentan algunas ventajas claras frente a los LLM tradicionales. Al generar todo el texto a la vez en lugar de palabra por palabra, los DLLM pueden lograr una mayor coherencia global, ya que todas las palabras se ajustan mutuamente durante el proceso. Esto se acerca más a cómo razonamos y escribimos los humanos. Además, al tener un número fijo de iteraciones, pueden ser más rápidos en tareas cortas y permiten un razonamiento más flexible en el espacio latente. Sin embargo, también tienen limitaciones: su entrenamiento y optimización todavía están en fases tempranas, carecen de las mejoras acumuladas que ya existen para los LLM, y su rendimiento puede degradarse con textos largos. Además, es más difícil reutilizar cálculos entre iteraciones, lo que puede afectar a su eficiencia en comparación con los modelos tradicionales altamente optimizados.
¿Qué futuro tienen?
Estos modelos podrían integrarse mejor en sistemas multimodales (que combinan texto, imagen, sonido…) y ofrecen nuevas posibilidades para tareas complejas como el razonamiento. Eso sí, todavía estamos dando los primeros pasos. Los LLMs tradicionales están muy optimizados, y cambiar de paradigma implica reaprender muchos procesos.
Un dato curioso: los creadores de LLaDA observaron que el modelo a veces puede generar la respuesta correcta antes de completar todo el razonamiento. Los tokens aún enmascarados ya contienen información útil, lo que sugiere que el razonamiento está ocurriendo en un plano latente.
