Recientemente, hemos visto cómo grandes empresas como IBM, Nvidia o Qwen han comenzado a lanzar modelos basados en una nueva arquitectura de Transformer. Uno de los cambios más revolucionarios de esta arquitectura se encuentra en su núcleo: el mecanismo de atención. En esta entrada, vamos a desglosar qué es este cambio, por qué es tan importante y qué beneficios nos trae.
El Problema de la Atención Clásica en los Transformers
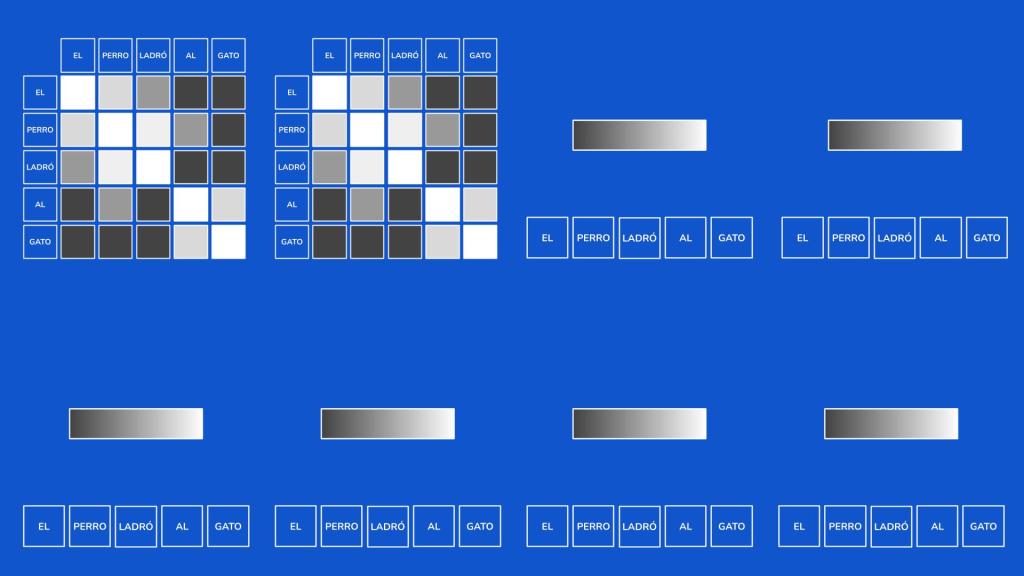
Para entender la innovación, primero debemos recordar cómo funciona la atención clásica en un modelo de lenguaje. De forma sencilla, su función es calcular la relación que existe entre cada palabra (o token) de un texto. Por ejemplo, en la frase «El perro ladró al gato», la atención ayuda al modelo a entender que «ladró» tiene una relación mucho más fuerte con «perro» que con «gato». Esto se representa internamente como una matriz de valores numéricos que mide la afinidad entre todos los tokens.

Aunque este mecanismo es muy efectivo, tiene dos grandes problemas, ambos relacionados con el mismo factor:
1. Consumo de Memoria: La matriz de atención crece de forma cuadrática a medida que añadimos más tokens. Si tenemos 3 tokens, necesitamos 9 valores; con 4 tokens, 16; con 5, 25, y así sucesivamente. Esto dispara el consumo de memoria.
2. Carga Computacional: No solo se trata de almacenar estas realciones, sino de operar con ellas. A más tokes, más relaciones y más operaciones, lo que incrementa enormemente la carga de cálculo.
Hay que tener en cuenta que un modelo no tiene un solo mecanismo de atención, sino varios trabajando en paralelo.
La Alternativa: La Atención Lineal y su «Gran» Defecto
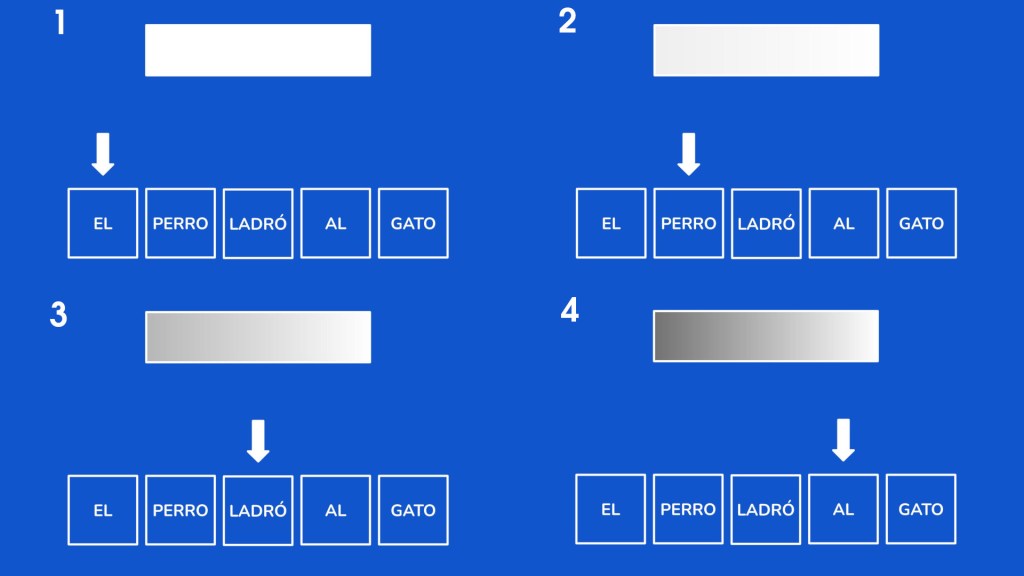
Aquí es donde entra en juego la atención lineal, una solución que ya existía en modelos como Mamba. A diferencia de la atención clásica, la atención lineal procesa los tokens de forma secuencial, uno por uno, utilizando un conjunto de estados de tamaño fijo que se va actualizando.
Las ventajas son enormes:
• El cálculo crece de forma lineal con el número de tokens, no exponencial.
• El uso de memoria es constante y no aumenta, sin importar la longitud del texto.
• Necesita menos datos para aprender4
Sin embargo, como suele pasar en ingeniería, no se puede ganar algo sin perder otra cosa. El gran inconveniente de la atención lineal es su dificultad para recordar las palabras exactas que ha procesado. Mientras que es buena prediciendo la siguiente palabra, falla cuando necesita recuperar fragmentos específicos del texto que está analizando. Esto se debe a que la relación entre tokens se representa de una forma más «borrosa» en su estado interno.
La Solución: La Atención Híbrida
Entonces, ¿cómo podemos combinar lo mejor de ambos mundos? La respuesta es la Atención Híbrida4.
La idea es simple pero brillante. Recordad que los modelos tienen múltiples mecanismos de atención funcionando en paralelo. Nada nos obliga a que todos sean del mismo tipo. La atención híbrida combina mecanismos de atención clásica y atención lineal dentro del mismo modelo de lenguaje.
Un gran ejemplo es el modelo Qwen 3 Next, donde:
• El 25% de los mecanismos de atención son clásicos
• El 75% son lineales
Gracias a este enfoque, se consiguen claras mejoras en el rendimiento y, además, se acelera el aprendizaje, ya que se requiere una menor cantidad de datos para alcanzar la misma calidad.
Estamos ante una evolución apasionante que no solo mejora el rendimiento de los modelos de lenguaje, sino también la eficiencia de su entrenamiento. En un próximo vídeo y entrada del blog, exploraremos más a fondo estas nuevas arquitecturas y los demás cambios que traen consigo.

Pingback: DSA (Deepseek Sparse Attention) | Construyendo a Chispas