En otro post comentaba que los modelos de atención híbridos (atención clásica combinada con atención lineal) parecían ser el futuro. Bueno, pocos días después, Deepseek nos sorprendió lanzando el modelo Deepseek 3.2, que utiliza un mecanismo de coste cuadrático DSA que compite de tú a tú con los modelos lineales.
De hecho, el mecanismo de atención es la única diferencia que existe entre Deepseek 3.2 y su predecesor, Deepseek 3.1.
¿Qué es DSA (Deepseek Sparse Attention)?
La gran pregunta es: ¿Cómo es posible que un mecanismo de coste cuadrático pueda competir con modelos lineales? El problema principal de los cuadráticos es que su coste computacional crece rápidamente.
La respuesta está en la implementación inteligente de DSA (Deepseek Sparse Attention). Aunque tiene una parte cuadrática, han logrado hacerla tan rápida que el impacto general no es tan grande.
El mecanismo de DSA consta de tres pasos:

- Paso 1: Creación de un Índice de Importancia (Coste Cuadrático): Se crea un índice que mide qué tan importante es cada token para los demás tokens. Aunque esto les recordará a la atención clásica, no es atención clásica; es mucho más rápido de calcular. Es la única parte que crece de forma cuadrática con el número de tokens.

- Paso 2: Selección de Tokens: Se calculan los N tokens más importantes según el valor del índice calculado en el primer paso.
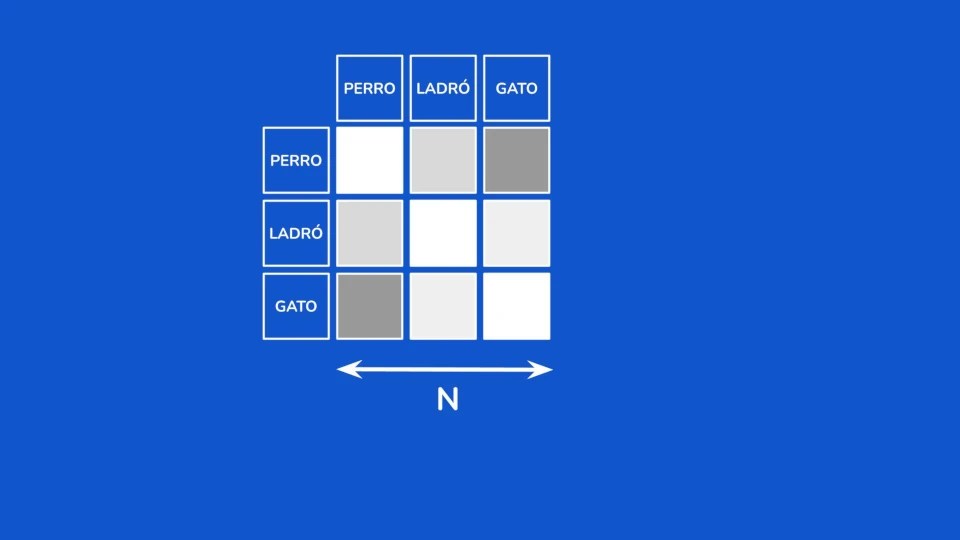
- Paso 3: Aplicación de Atención Clásica (Coste Constante): La atención clásica de toda la vida, con su coste computacional de N² se aplica solo sobre los tokens seleccionados. Lo genial es que el coste de este paso siempre será N², es decir, constante, sin importar el tamaño del texto que esté procesando el modelo de lenguaje.
Deepseek 3.2 crece mucho más lento que Deepseek 3.1. Esto sucede porque solamente el Paso 1 (la parte menos costosa computacionalmente) crece con el contexto.
Es cierto que, para contextos muy pequeños, Deepseek 3.2 tiene un rendimiento peor que 3.1, pero en cuanto el contexto comienza a crecer, lo compensa con creces.
Está la duda de si empeora la calidad de la salidad del modelo. Pues no. Si observan la comparativa de resultados de Deepseek 3.1 y 3.2 en varias pruebas, se ve que no hay una gran diferencia:

Deepseek lo ha vuelto a hacer: ha traído algo novedoso que posiblemente introducirá cambios importantes en los modelos de lenguaje.
Deepseek 3.2 tiene un tamaño de contexto de 160.000 tokens. Personalmente, me queda la duda de cómo se comportaŕa en contexto más grandes. Supongo que pronto lo veremos ya que hay un detalle crucial: para aplicar este tipo de atención, no hace falta entrenar el modelo de lenguaje desde cero. Puedes hacer fine tuning de un modelo ya existente y adaptarlo para que use DSA.
