Actualmente hay un interés enorme en revolucionar el corazón de los modelos de lenguaje: el famoso transformer. Hemos hablado de cambios en la atención e incluso en el tokenizador. Vamos a profundizar en una idea para reducir el número de iteraciones para procesar un texto en un trasformer: CALM, una propuesta para agrupar múltiples tokens en un solo vector.
El Corazón de CALM: El Autoencoder
Lo primero que el equipo detrás de esta idea tuvo que demostrar es si esto era siquiera posible: ¿Podríamos tomar varios tokens de texto, convertirlos en un único vector, y luego ser capaces de revertir ese proceso?
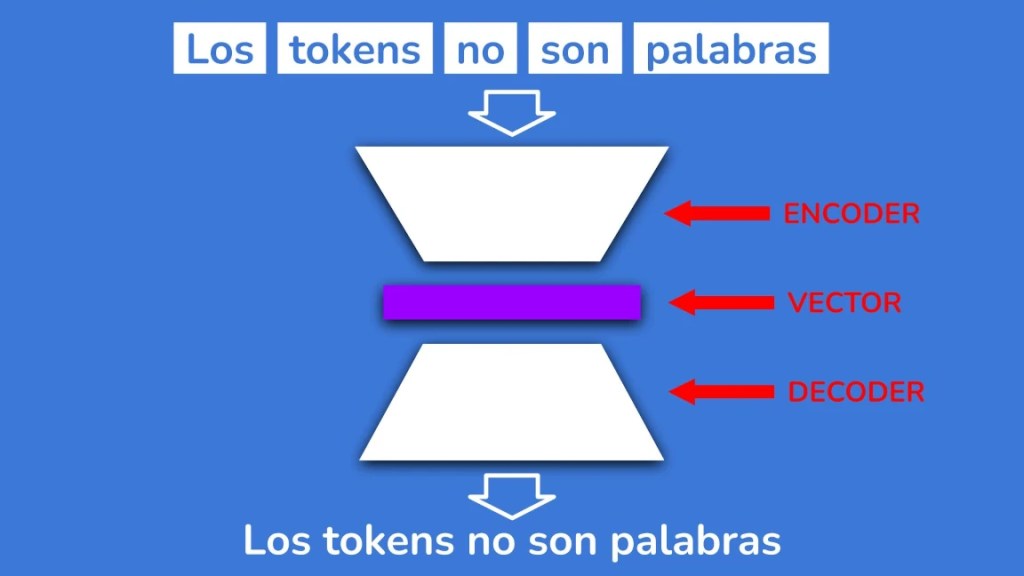
La respuesta es sí, y lo lograron utilizando un autoencoder. El encoder toma un puñado de tokens y los condensa en un vector abstracto que los representa a todos. El decoder toma ese vector y es capaz de sacar el texto original.
El Desafío: Que el Transformer procese vectores en lugar de tokens
A primera vista, el nuevo flujo parecía simple:
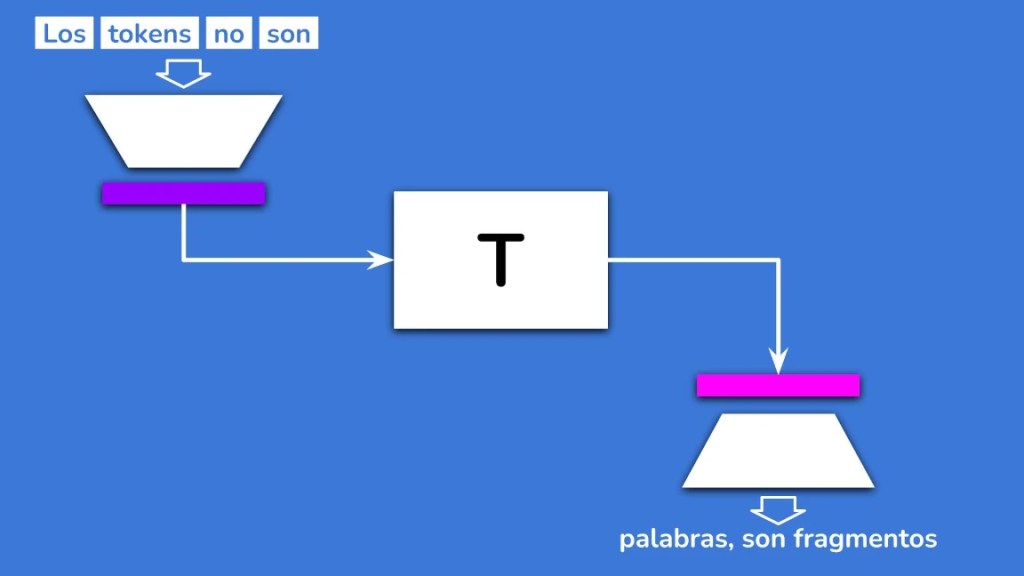
Pero la realidad es un poco más compleja.
El problema es que los Transformers estándar no responden directamente con el siguiente token. Responden con un conjunto de valores que, al aplicar la función Softmax, se convierten en probabilidades para elegir el siguiente token. Ahora, con CALM, no tenemos tokens individuales al final, sino un vector abstracto que agrupa varios de ellos. Simplemente no podemos aplicar Softmax y elegir el siguiente elemento de texto.
Además, perdimos algo vital en el proceso: la temperatura.
La temperatura es ese parámetro que nos permite controlar cuán diversa o «imaginativa» será la respuesta del modelo. Aunque parezca un detalle menor, sin la temperatura adecuada, ciertos procesos cruciales, como el razonamiento en los modelos, fallan y el sistema puede entrar en un bucle sin salida.
Necesitábamos una solución que pudiera interpretar la salida abstracta del transformer y, a la vez, devolvernos el control sobre la temperatura.
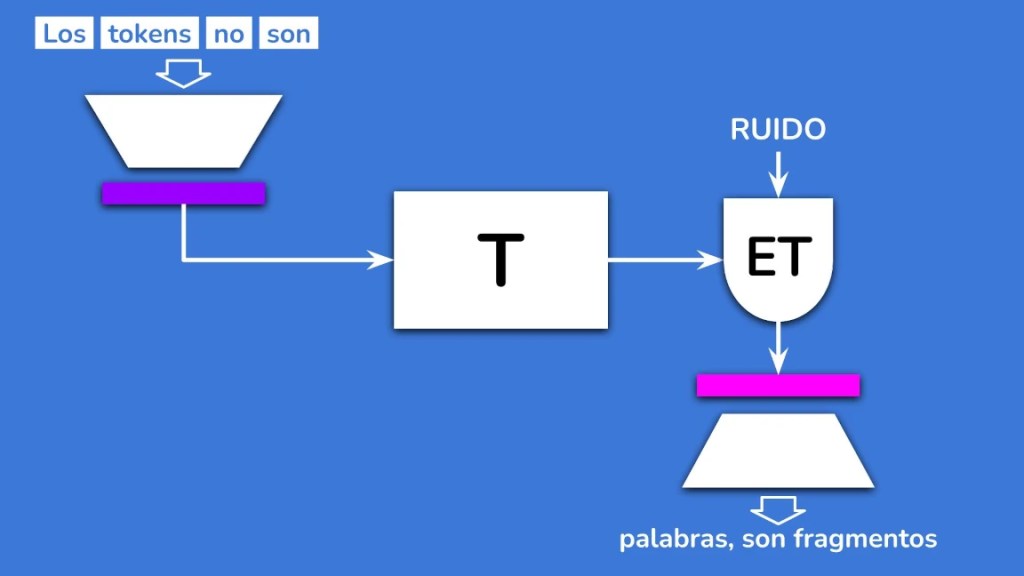
La Solución Ganadora: El Energy Transformer
El equipo exploró tres posibles soluciones: un modelo de difusión, flow matching y un Energy Transformer.
Finalmente, se eligió el Energy Transformer. ¿Por qué? Principalmente por su rendimiento. Es poco costoso de entrenar y, lo más importante, es capaz de generar la respuesta completa en una sola iteración.
Y en cuanto a la temperatura perdida, estas soluciones permiten simular ese comportamiento añadiendo ruido a la entrada. Así recuperamos el control sobre la diversidad del modelo.
Una vez que el Energy Transformer produce su respuesta, se la pasamos al decoder y ¡voilà! Hemos generado múltiples tokens con una sola pasada.
¿Cuánta Velocidad Ganamos?
Ahora, el sistema es verdaderamente multitoken. En el paper, los modelos de ejemplo lograron producir cuatro tokens por vector. Pero el equipo cree que, con modelos mucho más grandes, se podría alcanzar hasta ocho tokens por vector.
Ojo, esto no significa que sea ocho veces más rápido, ya que añadimos pasos adicionales (el encoder y el decoder) que no existen en el transformer normal. Sin embargo, la mejora es más que interesante, y parece que cuanto mayor es el modelo, mayor es la mejora. Esto tiene sentido, ya que en un modelo pequeño el encoder y el decoder representan una parte importante de los cálculos, mientras que en un modelo gigante estos pasos se vuelven insignificantes.
Es cierto que estos modelos CALM son más grandes en términos de pesos, pero esto se debe a que ahora contienen, además del transformer, todos los pesos de los componentes que lo rodean.
Conclusiones
¿Es CALM la solución definitiva a todos nuestros problemas de rendimiento? No lo sé. Pero sin duda, es una idea muy interesante. Me parece una aproximación mucho más robusta que otras que hemos visto, como la de convertir el documento en una imagen para procesar tokens visuales.
Lo que está claro es que el concepto de token tal como lo conocemos necesita una revisión profunda. Hay maneras más eficientes de representar la información que requieren menos iteraciones del modelo.
