DeepSeek ha presentado una propuesta técnica que podría marcar un antes y un después en la arquitectura de los Transformers: Engram. Se trata de una idea que busca solucionar un problema que, aunque no solemos ver, está afectando seriamente la eficiencia de los modelos de lenguaje actuales.
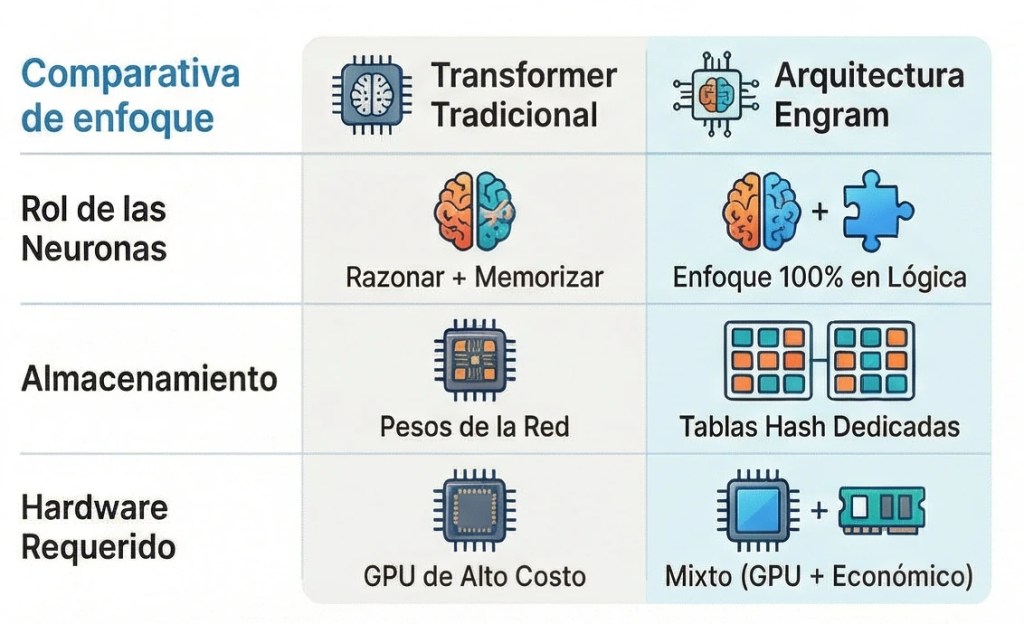
El problema: Las redes neuronales no son lo mejor para memorizar
Cuando le preguntas a una IA «¿Cuál es la capital de Francia?», la respuesta («París») es un dato memorizado, no el resultado de un proceso de razonamiento complejo. Actualmente, las redes neuronales de los modelos de lenguaje tienen que hacer ambas tareas a la vez: razonar (resolver problemas) y memorizar (almacenar datos estáticos).
El problema es que las redes neuronales no son la mejor herramienta para memorizar. Al obligarlas a guardar datos, estamos desperdiciando una potencia de cómputo inmensa que podría aprovecharse mejor.
La solución de Engram: Separar la memoria
La propuesta de Engram es elegante: separar estos dos procesos. La idea es crear un mecanismo óptimo dedicado exclusivamente a la memoria y dejar que las redes neuronales se dediquen 100% a la resolución de problemas (lo que llamamos «razonamiento» como símil).
¿Cómo funciona?
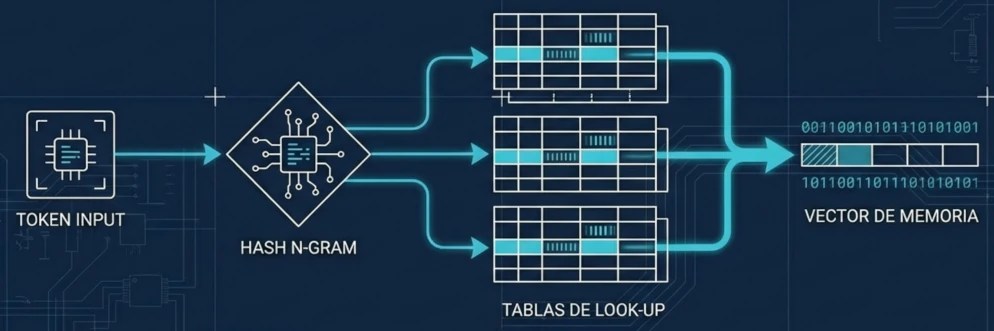
- Tablas y hashes: El sistema utiliza tablas de datos donde la información se recupera mediante un «hash» calculado a partir del token actual y los anteriores.
- Inyección de información: Esos datos recuperados se convierten en vectores que se inyectan en el flujo de trabajo del Transformer para aportarle información estática.
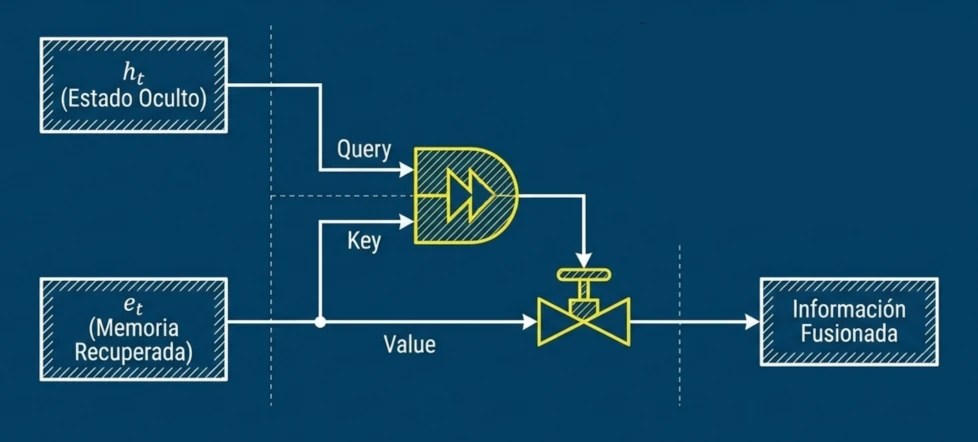
- La puerta de control: Para evitar errores (como cuando el contexto cambia y Francia no es un país, sino un planeta extraterrestre), existe una «puerta» reguladora. Es un vector que decide, valor a valor, cuánta de esa memoria inyectada es realmente válida para el contexto actual.
Problemas y soluciones
Al usar tablas con un hash existen dos tipos de problemas:
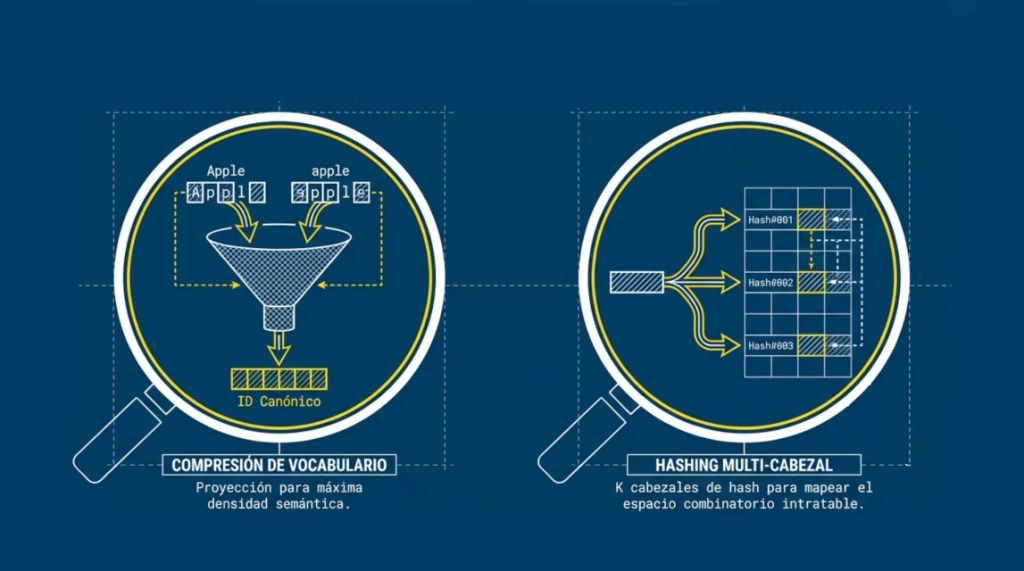
- Asignar a tokens similares direcciones diferentes: esto ocurre porque ls funciones hash tienen a «dispersar» los resultados y dos tokens parecidos (patata y Patata) pueden apuntar a espacios de memoria diferentes. Para evitar eso se toma la medida de simplificar los tokens para que ambos sean el mismo.
- Colisiones, asignar a tokens diferentes la misma dirección: el caso contrario, dos tokens distintos (camión y patata) apuntan al mismo espacio en memoria, cómo hay varias tablas de hash diferentes, aunque ocurra con una tabla el resto de valores compensaran esta respuesta errónea
La proporción adecuada
Uno de los puntos más prometedores es la eficiencia. Según los datos actuales, dedicar entre un 20% y un 25% de los pesos del modelo a este sistema de memoria permite que la IA «razone» mejor con el mismo número de parámetros.
Eficiencia, velocidad y hardware barato
Pero hay más: recuperar datos de estas tablas es muchísimo más rápido que procesar inputs a través de todas las capas de una red neuronal. Esto significa que este proceso se puede hacer en paralelo e incluso utilizando hardware más barato o de menor calidad sin que el rendimiento general del sistema sufra. Es una doble victoria: menos cálculo necesario y hardware más económico.
¿Qué esperar de Engram?
Aunque siempre hay que tomar el optimismo de los nuevos estudios con cautela, Engram es una idea sumamente interesante. El reto ahora es ver cómo escala en modelos masivos de cientos de miles de millones de parámetros.
Sin duda, no es una idea que lo cambie todo de la noche a la mañana, pero sí es un camino muy inteligente hacia una inteligencia artificial más eficiente y especializada.