Se estima que el 2026 será un año fundamental, con planes de expansión masivos en EE. UU., China y una Europa cada vez más permisiva.
Pero antes de entrar en harina, hay que aclarar algo que suele generar confusión: no es lo mismo un coche autónomo que un coche sin conductor.
Los niveles de autonomía: ¿Dónde estamos realmente?
Para entender la tecnología, primero debemos saber en qué nivel nos movemos. Según la DGT, existen cinco niveles de automatización:
• Nivel 1 y 2: Son los que ya vemos en la calle. El coche controla dirección o velocidad (o ambas), pero el conductor debe estar siempre presente y atento. Curiosamente, al nivel 2 se le llama hand off, aunque es justo lo que no debes hacer: soltar el volante.
• Nivel 3: El coche ya es «autónomo», pero requiere un conductor listo para intervenir si el sistema se ve superado.
• Nivel 4: El vehículo se las apaña solo. Si hay problemas, avisa a un operador remoto. Empresas como Waymo operan en este nivel.
• Nivel 5: La autonomía total. Sin volante ni pedales. A día de hoy, no existe ningún país que permita el nivel 5 de forma comercial, más allá de pruebas muy limitadas.
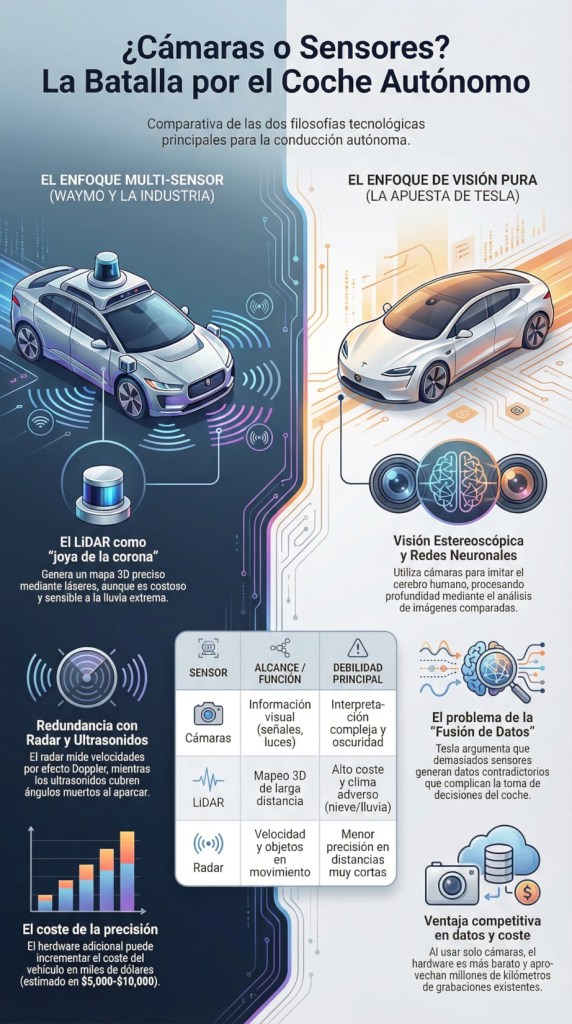
¿Cámaras o sensores?
Aquí es donde la industria se divide en dos bandos. Por un lado, Tesla apuesta exclusivamente por las cámaras. Por otro, el resto del mundo defiende el uso combinado de cámaras, radares, sensores ultrasónicos y el famoso LiDAR.
¿Qué aporta cada uno?
1. Sensores ultrasónicos: Son los típicos de aparcamiento. Funcionan por «tiempo de vuelo» del sonido. Son baratos y útiles en distancias cortas, aunque les afecta la temperatura y el viento.
2. Radares de microondas: Usan ondas electromagnéticas. Son ideales para medir la velocidad de otros vehículos gracias al efecto Doppler y funcionan bien en movimiento.
3. Cámaras: Son inevitables. Necesitamos ver señales, semáforos y luces de freno. Tesla confía en la visión estereoscópica (dos cámaras para emular la profundidad humana) y la luz estructurada para entender el entorno. Su mayor reto es la interpretación de imágenes mediante IA.
4. LiDAR: La joya de la corona. Lanza miles de puntos láser para crear un mapa 3D preciso de todo lo que rodea al coche. Sus enemigos son la lluvia densa, la nieve y los espejos, pero su precisión es asombrosa.
Para más información sobre los sensores puedes ver el siguiente vídeo:
¿Por qué Tesla se queda solo con las cámaras?
Si el LiDAR es tan bueno, ¿por qué prescindir de él? Tesla argumenta tres razones principales:
• Fusión de datos: Cuantos más sensores tienes, más difícil es ponerlos de acuerdo. Si un sensor dice una cosa y otro otra, el sistema puede entrar en conflicto (algo parecido a cuando nos mareamos en un barco porque nuestros sentidos no coinciden).
• Coste: Un equipo completo de sensores y el hardware necesario para procesar tanta información es extremadamente caro.
• Estrategia de datos: Este es el punto clave. Tesla tiene millones de kilómetros grabados solo con cámaras. Si ahora intentara usar LiDAR, empezaría de cero contra competidores como Waymo, que ya tienen todos esos datos procesados. Su apuesta es demostrar que un coche solo con cámaras puede conducir tan bien como uno lleno de sensores, siendo mucho más barato de producir.
¿Por qué Waymo apuesta por cámaras + sensores?
En este aspecto Waymo parte con ventaja. Sus coches ya están desplegados con equipamiento completo de sensores recopilando datos.
• Fusión de datos: La suma de los datos de todos los sensores da un modelo del mundo más completo. Además de ofrecer redundancia de datos.
• Coste: Esta opción requiere un hardware costoso. Es verdad que sus costes están bajando rápidamente. Si quiere ganar lo que ofrezca debe compensar el aumento de costes.
• Estrategia de datos: Waymo esta capturando datos de forma activa. Ahora mismo es su mayor ventaja. La fusión de datos parece estar suficientemente resuelta como para tener, probablemente, el coche más avanzado en cuanto a conducción autónoma.
Conclusión
No se trata de quién tiene la razón técnica absoluta, sino de estrategias económicas y de datos.
Lo que está claro es que la robótica y el hardware para la inteligencia artificial van a dar un salto gigante en los próximos años. Sea cual sea la tecnología que gane, ¡Os lo cuento desde aqui!