La aparición de la técnica RAG ha permitido usar nuestros propios documentos en las consultas a un modelo de lenguaje. Realmente la técnica es cómo un truco de magia. Lo que te da la sensación de que estás viendo no es realmente lo que ocurre.
Pero RAG no es una solución perfecta. Ni única , hay muchas formas de implementarlo y muchos modelos de lenguaje con el que usarlo. Poder hacer alguna prueba rápida que nos muestre que tal se comporta un RAG puede ser útil para descartar candidatos. En esta entrada vamos a ver una forma sencilla e informal de probar que tal funciona RAG.
El funcionamiento de un RAG se basa en dos modelos de lenguaje. Uno especializado en buscar textos relacionados y otro especializado en conversar con el usuario.
Cuando haces una pregunta / tarea el modelo de lenguaje especializado en buscar, busca textos relacionados en la documentación que le has pasado y le pasa estos textos al modelo especializado en conversar como parte del prompt.
¿Por qué no pasar todos los documentos al segundo modelo y olvidarnos del primero? Por el tamaño del contexto, el modelo solo es capaz de «recordar» un tamaño maximo de tokens (si no sabes lo que es un token sustituyelo por «palabra», no es exactamente lo mismo pero te permite hacerte una idea sin entrar en detalles técnicos). Todo lo que supere ese número de tokens es ignorado por el modelo de lenguaje.
Ahora hay modelos que permiten contextos muy grandes, el problema es que requieren enormes cantidades de RAM y potencia de cómputo.
Sin embargo no todo son ventajas y felicidad en el uso de RAG, algunos de los problemas son:
Si hay muchos bloques que coincidan se pueden perder datos ya que no todos se pueden añadir al prompt.
Se puede perder datos, por ejemplo en bloques muy largos puede quedar parte de la información en un bloque que no coincide con la query y por tanto no se añade.
El rag pierde la secuencia temporal. En un bloque se puede hablar de una cosa y en el siguiente modificarla. Al recuperar ambos bloques no tienen por qué conservar el orden.
El modelo puede no hacer caso a la info añadida al prompt. Este caso ocurre cuando el modelo tiene datos propios «aprendidos» sobre algo que los documentos contradicen. En casos así puede ser que el modelo ignore lo que dice el prompt (y por tanto los documentos) para responder con lo que su aprendizaje indica como correcto.
Coincidencias erróneas, por frases muy parecidas pero de significado contrario o el uso de ironía / sarcasmo.
Un documento puede mezclar tipos de datos diferentes que deberían de ser segmentados de forma diferente. Por ejemplo código y texto.
Se pueden usar los documentos para hacer «inyección de prompts»
Los datos de los documentos pueden filtrarse
Para detectar estos problemas en un RAG nos centraremos en cinco pruebas:
Una aguja en un pajar: prueba que muestra lo bueno que es detectando una pequeña cantidad de información en los documentos.
Aprendizaje vs documentos: los datos de los documentos contradicen datos aprendidos por el modelo. ¿Qué fuente prevalece?
Inyección de prompts: la parte recuperada de los documento contiene instrucciones ocultas para modificar el prompt
Alucinaciones: la documentación incluye información que el modelo desconoce (más que nada porque nos la hemos inventado). Al preguntarle sobre ella hay que verificar que no se inventa datos.
Conservar la secuencia de tiempo: Cuando se recuperan varios bloques de texto es posible que el orden de los mismos se pierda.
En el siguiente vídeo puedes ver como funcionan las pruebas:
Haz click para ver el vídeo en mi canal de Youtube
Cuando se habla de I.A. siempre hay gente que parece que solo les preocupa un aspecto: reemplazar trabajadores por máquinas. Uno de los primero ejemplos que siempre aparece es «la atención al público». Es un campo en el que, desde hace años, se esta tratando de reducir la parte humana ya que tiene muchas ventajas:
Abaratar costes: la mayor parte de los costes son los salarios de los trabajadores que atienden a la gente
Trabajan 24h: una I.A. no se cansa, no enferma, no duerme.
Paciencia infinita: a veces el trabajo de cara al publico es agotador y estresante. sin embargo discutir con una una I.A. es como discutir con una pared, ella no se irrita y conserva los buenos modales.
Hace ya años que hay chatbots gestionados por I.A.,que realmente son buscadores vitaminados. Unas pocas reglas para las respuestas. En caso de que no pudieran responderte te enviaban a un humano o a un formulario de contacto. Con la aparición de la I.A. generativa y su capacidad de conversar se veia un avance prometedor. Solo faltaba el poder pasarle la documentación de la empresa para que pudiera dar respuestas personalizadas, en ese momento apareció la técnica RAG. Ya podías tener un chatbot personalizado y si le incluías function calling podría incluso realizar tareas. ¡Temblad trabajadores humanos! Sin embargo no parece que vaya bien el tema, tenemos varios casos recientes representativos:
Y es que la I.A. generativa aun tiene varios problemas:
Alucinaciones: el mayor problema de la I.A. generativa. No sabes cuando la respuesta es real o cuando se la está inventado. Hay técnicas para reducirlas, pero ninguna es 100% eficaz. Y si a la respuesta le añades un «Puede que la respuesta sea incorrecta» hace que el bot en si mismo sea inútil.
Jailbreak: El siguiente gran problema de las I.A. generativas. La gente que trata de convencerlas de hacer algo que no deben hacer. Y puede parecer una tontería hasta que se ponen a usar tu chatbot para cosas que no fue diseñado (como asistente de programación) y eso te cuesta a ti dinero.
Una IA con una herramienta: Con function calling una I.A. puede interactuar con herramientas externas. Por ejemplo crear reservas a partir de datos de la conversación….ahora imaginar que sufre una alucinación mientras usa una de estas herramientas.
Fuga de datos: RAG permite usar documentos propios para la respuesta de la I.A. sin embargo corres el peligro de que acaben filtrándose. La I.A. es muy mala guardando secretos (sobre todo si se usa un poco de jailbreak). Todo lo que tengas en esos documentos asegúrate de que puede ser público. El peligro aqui es una mezcla de las dos anteriores, darle acceso a una herramienta para obtener datos y que alguien la manipule para que recupere datos que no debería ver.
Ataques tradicionales: Aunque al hablar de I.A. pensemos en terminator no hay que olvidar que realmente es un servicio más y por lo tanto expuesto a ataques tradicionales de los de siempre
Cuando se contrata a alguien para un trabajo se le realizan varias entrevistas, pruebas, se le pide su curriculum, a veces referencias, … Habría que plantearse hacer lo mismo con las I.A. no confiar tanto en la maquina. Que al final los humanos somos algo más valiosos de lo que puede parecer 😉 .
Puedes ver el vídeo basado en este articulo en mi canal de Youtube:
Los control vectors son una sorprendente herramienta para controlar el estilo del texto que genera un modelo de lenguaje.
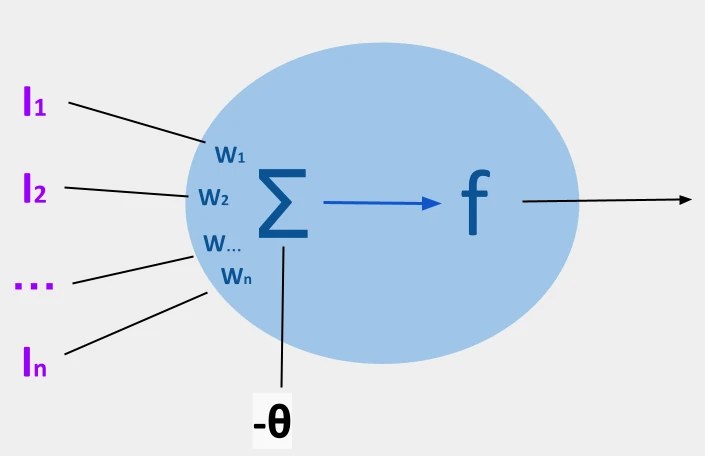
Para entender lo que son los control vectors empezaremos por lo que es una neurona artificial. sin entrar en mucho detalle básicamente se compone de un conjunto de datos de entrada (un vector) que se multiplica por un conjunto de pesos (vamos a ignorar el bias, el simbolito ese raro que hay en el dibujo). Cada valor se multiplica con su peso correspondiente y luego esos resultados se suman todos y se pasan a una función conocida como función de activación. El resultado es la salida de la neurona.
Una red neuronal no es nada más que un conjunto de estas neuronas que se agrupan formando capas.
Las operaciones del vector de valores de entrada con cada una de estas capas puede hacerse como multiplicar este vector por una matriz formada por los pesos de todas las neuronas. El resultado es otro vector cada uno de los elementos de este vector se pasa a la función de activación generando el vector output de esa capa. Que será el vector input de la siguiente capa.
El funcionamiento de control vectors es sencillo, se calcula un vector por cada capa que se suma al vector input y que hace que el modelo se comporte de una manera predefinida.
¿Cómo calculamos los control vectors?
Es muy sencillo, usamos dos prompts para hacer que el modelo se comporte de la forma deseada y de la contraria. Por ejemplo:
«Responde como una persona muy educada. [Tarea]» «Responde como una persona muy maleducada. [Tarea]»
Siendo tarea un conjunto de tareas que completaran el prompt.
Por ahora vamos a centrarnos en una sola tarea:
«Responde como una persona muy educada. ¿Cúal es la capital de Francia?» «Responde como una persona muy maleducada. ¿Cúal es la capital de Francia?»
Al procesar cada uno de los prompts irá generando dos vectores output por cada capa. Uno para el prompt positivo y otro para el negativo. Restando ambos tendremos un único vector por capa.
Repitiendo este proceso para cada tarea tendremos para cada capa un grupo de vectores formados por la resta de los vectores positivos y negativos de cada tarea.
Este grupo lo reducimos a un solo vector usando PCA y así obtenemos un control vector para cada capa. El grupo de todos los vectores para cada capa es lo que se denomina control vectors
Cuando se aplica a un input, el control vector se multiplica por un valor (generalmente entre 2 y -2) que determina con qué fuerza se aplicará. Si es positivo reforzará el comportamiento positivo, si es negativo reforzará el contrario.
Cómo usar los control vectors
Actualmente son soportados por llama.cpp cuya aplicación «main» ofrece tres parámetros para usarlos:
–control-vector happy.gguf Indica que fichero de control vectors usar (en este caso happy.gguf) –control-vector-scaled honest.gguf -1.5 Indica el fichero y el peso que se aplica a los control vectors –control-vector-layer-range 14 26 Indica a que capas de la red neuronal se aplica
Por suerte es bastante sencillo, existe un notebook de Google Colab que permite entrenar nuestros control vectors de forma simple
Puedes ver el siguiente vídeo explicando este articulo y con un ejemplo de como se usa el notebook de Goolge Colab:
Haz click en la imagen para ver el vídeo en Youtube
Control Vectors vs Prompt
Control vector no puede conseguir nada que el prompt no consiga. ¿Por qué usarlo? El primer motivo es que permite personalizar el comportamiento del modelo independientemente del prompt, lo cual facilita redactar prompts sin pensar en esa parte. Se pueden aplicar distintos control vectors al mismo prompt y viceversa, lo cual facilita realizar pruebas. Por último los control vectors se tienen más en cuenta que los prompts ya que modifican los prompts en cada capa de la red neuronal. Gracias a esto pueden ser una herramienta útil contra el jailbreaking.
Control Vectors vs Fine-tuning y LoRA
El fine-tuning consiste en reentrenar el modelo con datos propios. Permite personalizar el modelo y hacer cosas mucho más complejas: añadir nuevos datos, nuevos formatos de respuesta, darle nuevas capacidades (como function calling). A cambio el coste en tiempo y recursos es mucho mayor. El resultado es un modelo completamente nuevo.
LoRA consiste en entrenar solo una parte de los pesos de un modelo para obtener resultados cercanos al fine-tuning. Se obtiene un conjunto de pesos que puede ser «añadido» de forma dinámica, se pueden llegar a combinar varios LoRA (aunque nadie te promete que funcione). Cuesta entrenarlo menos que el fine-tuning pero aun así es exigente en tiempo y recursos. El resultado ocupa solo una parte de lo que ocupa el modelo, aunque es necesario tener ambos para que funcione.
Control Vectors no permite añadir nada al modelo, solo modificar su comportamiento dentro de los límites que el prompt permite. A cambio se entrena realmente rápido (de hecho es un 2×1 ya que entrenas el comportamiento deseado y el contrario). El resultado pesa muy poco.
Es un tema recurrente cada vez que se produce un avance en IA «¿Esto como se aplica para mejorar las capacidades de los robots?». El interés en mejorar los robots. Últimamente se habla mucho de modelos de lenguaje, modelos del mundo y robots. Como el modelo del mundo de la IA generativa se puede usara para revolucionar la robótica. ¿Pero que es eso de un modelo del mundo? Es una representación que realiza el agente de su entorno que le permite anticipar como sus acciones van a afectar al entorno y al propio agente.
Pero vayamos paso a paso.
El modelo interno del termostato
Si me permitís estirar el significado de «modelo del mundo» podríamos verlo en cualquier automatismo, por ejemplo un termostato que use un sensor de temperatura basado en la variación del voltaje tendría un modelo del mundo que podría resumirse como:
T = Vs * Ks + Os
La temperatura T es igual al voltaje obtenido por el sensor Vs, corregido por una constante de proporcionalidad Ks y un valor inicial (offset) Os.
Posteriormente compara la temperatura «observada» con una de referencia, si es menor pone la calefacción, si es mayor la quita.
Se puede ver que este modelo del mundo tiene algunas limitaciones, por ejemplo tiene un rango por arriba y por abajo a partir del cual no percibe cambios de temperatura. El sensor puede funcionar de 0 a 5v por lo que más allá de esos valores no podría ofrecer resultados.
Resumiendo, tenemos un dato percibido del mundo real a través de los sensores, un modelo que lo transforma y unas reglas internas que hacen que actúe
La navegación de la aspiradora
Veamos un caso un poquito más elaborado, el de un robot aspiradora. en este caso su modelo del mundo es más intuitivo. Tenemos un mapa de su mundo trazado por el LiDAR de la propia aspiradora. Cuando funciona de manera normal lo que haces es comparar ese mapa con lo que «ve» usando el LiDAR y así puede calcular su posición. Pero no basta con eso, hay dos problemas: muchos puntos de la casa que pueden verse idénticos a través del LiDAR. Además pueden «aparecer» cambios, mesas que se mueven, sillas, bolsas, …. Todos esos cambios alteran lo que el LiDAR percibe o lo que es lo mismo, meten ruido.
No basta solo con el LiDAR, por eso el robot no solo cuenta con los datos de sus sensores externos, también cuenta con un modelo interno que trata de replicar la ruta recorrida en el mapa. Por ejemplo puede usar tacómetros en las ruedas para ver cuánto ha girado cada una y con ello calcular la distancias recorrida y los grados de cada giro. Son datos imprecisos pero que junto con las lecturas del LiDAR permiten precisar la posición del robot. Ya que reducen el espacio donde esta puede estar y donde el LiDAR ha de buscar coincidencias.
En esta caso la representación del mundo se compone de la suma de un estado interno más lo que perciben los sensores. Con ello toma decisiones para ejecutar un programa de limpieza.
La IA generativa prepara café
A la aspiradora le puedes indicar que vaya a varias habitaciones, el robot crea un listado de tareas y las ejecuta una por una. A esto se le llama planificación de tareas. Para cosas sencillas la rebotica lo tiene resuelto, pero imagínate que ahora le pedimos a nuestro robot aspirador que nos prepare un café.
La planificación parece sencilla:
Ir a la cocina
Tomar la cafetera
Poner café
Poner agua
Calentar la cafetera
Esperar a que suba el café
Pero en la vida real el tema las cosas se pueden complicar. ¿Qué pasa si la cafetera no esta donde esperas? ¿si esta sucia? ¿Si tiene ya café dentro? ¿Si ese café está frió? ¿Si lleva ahí mucho tiempo?
Es difícil definir reglas para tareas con tanta variables, el mundo real es complicado y crear planes en él requiere conocer mucha cosas (cosas como saber limpiar una cafetera) . Por eso los robots han triunfado en cadenas de montaje donde el entorno es controlado y aun así llevan una enorme seta roja para pulsarla cuando algo va mal.
Sin embargo las IA generativas parecen tener un claro conocimiento de como funciona este mundo. Le puede preguntar como hacer un café y me da un listado de tareas que hay que cumplir:
Si surge algún imprevisto puede planificar como actuar:
Esto es una ventaja tremenda ya que evitar programar reglas para cada caso, le puedo preguntar a una IA generativa y ella me da los pasos a seguir. Es decir delego en ella la planificación de tareas. Permitiéndome mucha más flexibilidad. Esto se debe a que el modelo del mundo de la IA es mucho mayor, sabe como funciona el mundo sin que necesite programarlo.
Con la multimodalidad una imagen vale más que mil palabras
Si queremos usar una IA generativa existe el problema de formular la pregunta de forma correcta. En la tarea que le hemos planteado es sencillo, pero imaginaros que tenemos la imagen de una cafetera ¿Como sabe el robot si esta llena/sucia/incompleta/…? Necesita saberlo para formular el prompt. Es más sencillo si se le pudiera alimentar a la IA generativa con los datos que percibe el propio robot. Imagen, audio, IMU, … Ya tenemos modelos que soportan este tipo de datos, por ejemplo ImageBind de Meta
La imaginación es un simulador
Desde que apareció SORA, la IA capaz de generar vídeos, se ha comentado la capacidad de la IA para simular el mundo real simulando la física del mismo (aunque también es capaz de crear vídeos de delfines en bicicleta y no parece distinguir que eso no es realista…pero ese es otro tema). Esto nos daría la posibilidad de que el robot imaginara su actuación antes de realizarla viendo errores o posibles peligros antes de ejecutar el plan. Puede ser que no sea una simulación muy fiel de la realidad, pero los humanos hacemos lo mismo con la imaginación que tampoco es una replica exacta de la realidad y nos permite anticipar que va suceder.
El copiloto del dron
Ahora veamos como se integran estos dos sistemas. Volvamos a los robots, en este caso a un dron teledirigido por un humano.
En este caso el dron hace lo que mejor sabe, volar. Y no creáis que es un tarea sencilla sencilla que un dron vuele. Necesita estar manteniendo los cuatro motores a la velocidad adecuada. Ademas dos de ellos giran en una dirección y otros dos en otra para compensar el momento. Si el empuje de los motores no se compensan el dron girara sobre si mismo. Para saber todo esto el dron cuenta con un conjunto de sensores que le indican la aceleración y velocidad en cada eje o los cambios de altura. Todos ellos pasan información al controlador de vuelo que usa para configurar la velocidad de giro de los motores. A diferencia de un helicóptero las alabes de las hélices son fijas lo cual hace que la velocidad sea el único parámetro con el que puede jugar. Si como humanos intentáramos hacer la función del controlador de vuelo no seriamos capaces.
Ahora como humanos podemos dar ordenes sencillas al dron usando el mando y el ya se las apañará para realizarlas. Podemos «pilotar» el dron….aunque si nos ponemos quisquillosos no somos el piloto, somos el copiloto dándole ordenes al dron. Si el dron tiene suficiente «inteligencia» evitara hacer maniobras que lo tiren abajo o incluso lo hagan chocar. Nosotros damos las ordenes de alto nivel, pero el que controla directamente el aparato y sus motores es el controlador de vuelo. De hecho muchos drones puede tomar decisiones, como aterrizar, en caso de que pierda comunicación con el mando.
La idea es que la IA generativa funcione al mismo nivel, crear ordenes de alto nivel mientras que el robot hace lo que se le da bien, moverse si chocar con nada. Es posible que algunas funciones estén duplicadas, por ejemplo un robot puede tener un algoritmo de visión por computador muy sencillo para distinguir ciertos objetos mientras que un modelo de lenguaje multimodal podría realizar las mismas funciones.
Esta arquitectura piloto/copiloto no es tan extraña, si lo piensas la relación de tu consciencia con tu cuerpo es similar. Tu consciencia recibe los estímulos de los sensores externos (sentidos exteroceptores) y del estado interno (sentidos interoceptores) y toma decisiones que el cuerpo ejecuta. por lo general no necesita pensar cada movimiento para realizarlo, basta con ordenar a tu cuerpo «levanta el brazo», «camina», «salta»,…. Y si te crees que tienes el control sobre tu cuerpo trata de apagar una sensación de dolor, regular tu ritmo cardíaco de forma directa o controlar tu sudor. O en un caso más extremo si tu cuerpo decide perder el conocimiento poco puedes hacer para evitarlo.
Este sistema tiene la ventaja de que la parte de control del robot puede actuar en tiempo real, mientras que la IA generativa es mucho más lenta tomando decisiones. Si bien exista la idea de que la IA generativa se ocupe de todo y controle el robot a bajo nivel su tiempo de respuesta actual me hace dudar que sea practico, sobre todo si tenemos en cuenta que los algoritmos de navegación y control de los robots llevan muchos años de uso real y están muy pulidos.
Entender las órdenes humanas
Con la capacidad de entender el mundo que tiene los modelos de lenguaje podrían actuar como intermediarios entre la robótica actual y las ordenes humanas. Dar ordenes a los robots siempre ha estado más cerca de la programación que de el lenguaje natural. Sin embargo los modelos del lenguaje se la apañan muy bien siguiendo instrucciones humanas.
No todo es tan bonito
El principal problema que tiene integrar estos sistemas esta que la IA generativa aún esta lejos de tener consistencia suficiente en sus respuestas. Y una cosa es inventarse un libro cuando le preguntas por un autor y otra que decida llenar la cafetera de lejía porque confunde el contexto al tener que limpiarla. Obviamente un error en el mundo real es peligroso y caro. Si bien los robots pueden tener medidas que les impidan realizar tareas que directamente les dañe (como tirarte escaleras abajo) no es tan sencillo con instrucciones complejas que pueden terminar en dañandolos (súbete al monopatín, empuja el monopatín hacia las escaleras, no te muevas)
Hasta que no aumente la confianza en estos sistemas su uso en el mundo real queda muy limitado.
Puedes ver la versión en vídeo de este post en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Estamos acostumbrados a que las IA generativas traten de seguir nuestras instrucciones con mayor menor acierto. ¿Pero hay alguna instrucción que les sea imposible seguir? Y con ello me refiero a instrucciones dentro de sus capacidades, no a cosas imposibles. Es decir, una instrucción que esté a su alcance seguir pero sea imposible que lo hagan…
Puedes hallar la respuesta en este video o si no quieres verlo en el párrafo debajo suyo:
«No respondas». Es es la instrucción que los modelos de lenguaje actualmente no pueden seguir. No porque no sean capaces de hacerlo. Por lo general pueden devolver un token que indica «fin de la respuesta» pero han sido entrenadas para completar frases, no pueden evitar tratar de completar el texto, aunque sea contradiciendo la orden que se les ha dado.
Un ejemplo :
Tú No respondas ChatGPT Entendido, no responderé. Si tienes alguna otra consulta o necesitas ayuda, no dudes en decírmelo.
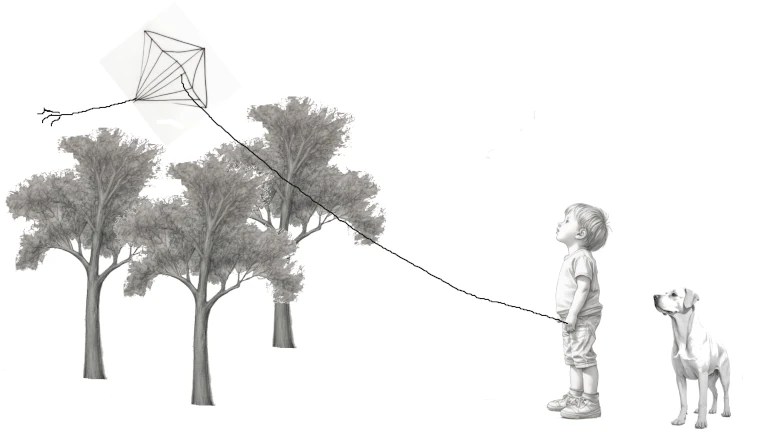
La forma más popular de usar una IA generativa es usar un prompt. Pero seamos sinceros, no parece una forma con que un artista tradicional se sienta cómodo. Cuando un artista quiere la imagen de un niño volando una cometa con un perro detrás no quiere «una imagen» de un niño volando una cometa con un perro detrás. Quiere «la imagen» que tiene en mente de un niño volando una cometa con un perro detrás.
En lugar de basarnos exclusivamente en prompts vamos a usar como base bocetos a «lápiz» (o con lo que sea que se dibuja ahora) o si no se te da bien el dibujo puedes generarlos con IA.
Para la parte de generar imágenes con IA vamos a usar Fooocus, en este vídeo tienes una rápida introducción al mismo:
Haz click para ver el vídeo en mi canal de Youtube
Veamos como realizar el proceso en cuatro simples (o no, depende lo que te compliques la vida) pasos.
(Si prefieres ver el proceso en vídeo al final del articulo tienes un vídeo)
Paso 1: Generar los bocetos a «lápiz»
Si eres dibujante puedes hacer este paso a mano. Pero si, como me pasa a mi, tus manos son incapaces de hacer una linea recta y menos un dibujo medio decente puedes usar Stable Difussion para que te haga los dibujos. En este ejemplo vamos a usar este prompt:
draw [……..], draw in simple lines pencil, white brackground
En la linea de puntos describiremos lo que queremos que dibuje.
Os dejo algunos términos más para que exploreis: line art, sketch, hand drawn (cuidado que a veces dibuja manos), vector, svg, clipart, … En definitiva todo aquello que haga referencia a dibujos cuyas líneas estén claramente delimitadas.
draw a kid look up at sky, full body, draw in simple lines pencil, white brackground
draw a tree, draw in simple lines pencil, white brackground
draw a kite, draw in simple lines pencil, white brackground
draw a dog from side, draw in simple lines pencil, white brackground
Paso 2: Montar la escena
Ahora que tenemos nuestros bocetos vamos a ponerlos en la imagen, lo primero es borrar todo lo que no queremos, por ejemplo la cola de la cometa o las nubes y el suelo del dibujo del niño.
Posteriormente las colocamos sobre un fondo blanco. Para ello hemos de escalar cada imagen al tamaño deseado y pegarlas. Podemos rotarlas como el perro o la cometa y añadir detalles como la cuerda de la cometa
Paso 3: Aplicar el estilo
Ahora podemos usar Fooocus para aplicar el estilo que queramos. Para ellos vamos usar el siguiente prompt:
a kid flying a kite with a dog behind
El prompt lo puedes completar con diversos estilos ya sea seleccionándolos de la pestaña estilos de Fooocus, ya sea describiéndolos en el prompt, también puedes añadir al prompt elementos que te gustaría incluir como un sol o pájaros.
Paso 4: Corregir defectos
La imágenes resultantes tienen buen aspecto pero es necesario corregir algún detalle.
Para estas correcciones podemos usar técnicas tradicionales (por ejemplo, borrar las cometas sobrantes de alguna imagen clonando el cielo encima suyo) o inteligencia artificial. Para ello tenemos la técnica que se conoce como inpaint, que te permite seleccionar parte de una imagen y perdirle a la IA que la modifique.
En este caso vamos a usar una funcionalidad que permite mejorar la caras obtenidas en la foto. Podéis ver el resultado de usar esa herramienta:
Hay técnicas mucho más avanzadas pero esta es una buena forma de comenzar a trabajar con IA generativa si los prompts se te hacen muy incómodos
Puedes ver el proceso en el siguiente vídeo:
Haz click para ver el vídeo en mi canal de Youtube
Trabaja con SD XL. Una vez cargado el LoRA en nuestra aplicación para generar imágenes favorita hay que tener en cuenta varias cosas:
Lo recomendable es que la imagen tenga un formato 2:1, mejor aun si es 1600×800.
Un peso recomendable para ese LoRA es entre 1 y 1.2. No tiene que serlo obligatoriamente, pero por los ejemplos que he visto, y mis pruebas, son buenos valores para empezar
Para «activar» el LoRA es recomendable usar la expresión «360 view» en el prompt. A mi personalmente me ha funcionado muy bien empezar el prompt con «A 360 view of».
Este LoRA funciona muy bien generando imágenes realistas, no tan bien con otro tipo de imágenes. Sospecho que se debe al entrenamiento, que será mayoritariamente con fotos de paisajes, naturaleza, skylines, …
Para ver bien el resultado en un visor de imágenes de 360º lo recomendable seria escalar la imagen con alguna otra IA generada una al menos 3 o 4 veces su tamaño.
Podéis ver el proceso de crear una imagen en este vídeo de mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
No se si habéis jugado al Little Alchemy, es un juego en el que partes con los 4 elementos (aire, agua, tierra, fuego) y tienes que ir combinándolos para obtener nuevas sustancias, materiales, cosas, … Algunas más predecibles que otras, por ejemplo si mezclas agua y tierra y obtienes barro.
Si ya lo conocías, es posible que sepas lo adictivo que puede ser ir combinando items. Imaginaros lo que me pareció la idea de tener uno infinito (que luego no es tan infinito). Para ello usa un LLM para ir creando las diferentes combinaciones. Podéis probarlo en este link. Y en este otro encontrareis el articulo del autor sobre sobre el juego.
Nosotros vamos a probar la parte del uso de los modelos de lenguaje como motor del juego, para ello vamos a usar ChatGPT y Google Gemini.
Vamos a usar prompts diferentes ya que ChatGPT parece entender mejor los ejemplos que Gemini, al que hay que indicarle el
ChatGPT:
Vamos a jugar a un juego, yo te doy dos elementos y tu me dices un tercero producido por la suma de esos dos, por ejemplo: (agua + fuego) = [vapor] (tierra + tierra) = [roca] (agua + tierra) = [barro] (motor + rueda) = [coche]
Gemini:
Vamos a jugar a un juego, yo te doy dos elementos entre paréntesis y tu me dices un tercero producido por la suma de esos dos entre corchetes, por ejemplo: (agua + fuego) = [vapor] (tierra + tierra) = [roca] (agua + tierra) = [barro] (motor + rueda) = [coche]
En este vídeo de mi canal de Youtube se pueden ver las pruebas realizadas:
Haz click para ver el vídeo en mi canal de Youtube
En resumen, ChatGPT resulta mas comedido en las repuestas lo cual en este caso como motor de juegos resulta mejor ya que facilita procesar las respuestas. Gemini da una gran cantidad de detalles lo cual se agradecería en el caso de ser una conversación pero no en el que se le ha pedido en el prompt.
El fine tuning vía proxy es útil cuando tenemos un modelo que: o es demasiado grande para poder entrenarlo o no tenemos acceso a él. Aunque hemos de tener acceso a los logits que calcula para cada token.
La solución a este problema es tomar un modelo más pequeño (el proxy) con el mismo vocabulario y entrenarlo.
Así tendríamos tres modelos: el grande, el pequeño sin entrenar y el pequeño entrenado.
Si pasamos el mismo prompt a los tres modelos obtendremos tres distribuciones diferentes para los tokens del modelo. Una para cada modelo.
Ahora tomamos los resultados de los dos modelos pequeños y calculamos sus diferencias para cada token. Ahora aplicamos esas diferencias a los tokens del modelo grande. Con estos nuevos logits podemos calcular las nuevas probabilidades de cada token usando softmax.
Puedes ver una explicación rápida en el siguiente short:
No se vosotros pero últimamente he estado viendo montón de anuncios, artículos y titulares que hablan del prompt engineering y parecen reducirlo a saber unos poco trucos. No digo que esos trucos no sean útiles para hacer buenos prompts, pero los prompts son solo una parte de todo lo que puedes configurar en un modelo del lenguaje para conseguir los resultados que deseas.
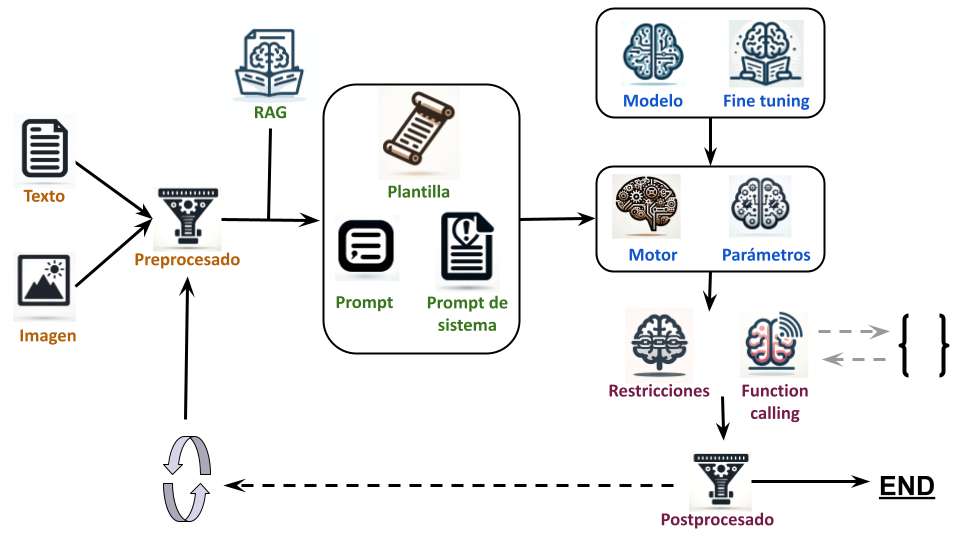
En la siguiente imagen se puede ver el proceso de funcionamiento de un modelo de lenguaje con cada una de las partes que se vamos a ver:
Elegir modelo y motor:
Elegir modelo: Para elegir el modelo necesitamos saber cuanta memoria VRAM tenemos (o podemos permitirnos). Como truco de calculo podemos aproximar que por cada parámetro el modelo ocupa 4 bytes (32 bits). Así que un modelo de 30B ocupa unos 120GB de memoria VRAM. Hay opciones como los modelos cuantizados, que bajan la precisión de cada parámetro. Por ejemplo si la bajas de 32 a 16 bits el modelo ocuparía la mitad. A cambio el modelo empeora. ¿Es mejor un modelo de 30B cuantizado a 4 bits, uno de 15B cuantizado a 8 bit, uno de 7B cuantizado a 16 bits o uno de 3,5B sin cuantizar? Todos ocupan casi lo mismo. Otra característica importante del modelo es para que está entrenado, básicamente puede estar entrenado para completar texto, seguir ordenes o chatear. Esto afecta a como va a interactuar con el usuario y como se van a escribir los prompts. Ademas es importante saber en que idiomas funciona el modelo y si ha sido entrenado o «finetuneado» con datos que necesitas, por ejemplo: un modelo entrenado para programar. No hay que olvidar la posibilidad de la multimodalidad (audio, voz, imágenes, vídeo, …)
Elegir motor: Una vez elegido el modelo habrá que elegir el motor para ejecutarlo. Dependerá básicamente de tres cosas: las características del modelo (familia y cuantización), de la API que necesitemos (servidor, librería, lenguaje de programación,…) y del hardware donde vaya a ejecutarse (GPU, CPU, RAM, VRAM)
Parámetros: Al ejecutar un modelo en el motor hay diferentes parámetros (dependen del motor y el modelo). Al configurarlos podemos obtener diversos resultados, un modelo más o menos original o coherente, variar las probabilidades de algunas palabras, sacrificar calidad por velocidad, …
Fine tuning: Si no se encuentra el modelo adecuado habrá que plantearse adaptar uno existente con fine tuning
Preprocesado
Preprocesado: Antes de enviar el texto al modelos habrá que tener en cuenta si es necesario procesarlo, cosas como: censurarlo, darle formato, traducirlo, …
Texto: Los datos en formato texto sobre los que vamos a trabajar
Multimedia: Si el modelo es multimodal no solo tendremos datos en forma de texto, también tendremos otro tipo de datos. Por supuesto habrá que preprocesar esos datos también.
Procesado:
RAG: Si queremos incluir documentos o información externa relacionada con el prompt podemos usar RAG. Para usar esta técnica tenemos que tomar varia decisiones: el algoritmo que se usa para elegir los documentos (puede ser necesario elegir otro modelo de lenguaje), el tamaño de los bloques que se van a elegir, como estos documentos se van a procesar para crear esos bloques, ….
Plantilla para el prompt: Hay que definir la plantilla que va a usar el modelo del lenguaje, vendrá definida por el entrenamiento y fine tuning del modelo de lenguaje.
Prompt de sistema: Aquí empieza ya la magia del prompt. Este es el prompt inicial que se le pasa al modelo describiendo su rol , comportamiento y funciones. Es importante definir lo correctamente
Restricciones: No tenia muy claro como llamar esta parte. Consiste en limitar la salida de texto a unas reglas definidas. Por ejemplo, usando expresiones regulares o gramáticas BNF. Sirve para obligar a que la respuesta tenga un formato concreto.
Function calling: Al modelo se le pueden pasar la descripción y firma de diversas funciones de código y, si esta entrenado para ello, puede invocarlas eligiendo los parámetros para las mismas.
Prompt: ¡Por fin! Aquí está el famoso prompt, el texto del prompt ha de integrar los demás datos y funcionalidades, describir correctamente lo que deseamos que el modelo de lenguaje haga. En muchos casos el prompt tiene varios pasos y es necesario pasar varias veces por el LLM para procesarlo.
Postprocesado:
Postprocesado: Una vez generado el texto será necesario procesar la respuesta.
Iteraciones extras: Hay flujos de trabajo que se dividen en varias iteraciones o pasos, sigues alguno de estos es posible que tengas que plantearte modelos para los siguientes pasos o
Function calling: Si se determina que hay que llamar a alguna función, este es el punto donde se le llama y se procesa la respuesta.
Es te flujo ha de considerarse un resumen simplificado. Hay más opciones y técnicas, pero aqui se recogen prácticamente las mínimas a usar hoy en día.
¿Y por qué te has centrado en modelos de lenguaje y no otras IA generativas que usan prompts como las que generan imágenes? Por que los modelos de lenguaje son sencillos. Por ejemplo, Stable Difussion tiene tantas formas de alterar su funcionamiento y resultados que no se si seria capaz de citar las más usadas.
Puedes ver un vídeo explicativo en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube