En este post, vamos a explorar una fascinante técnica para mejorar el rendimiento de los modelos de lenguaje llamada speculative decoding. Esta estrategia se basa en la idea de «adivinar» las respuestas antes de tiempo, tal como lo haría un oráculo.
Vamos a sumergirnos en los detalles para comprender cómo funciona esta técnica y cómo nos permite acelerar los tiempos de procesamiento.
Puedes ver la versión en vídeo en YouTube (https://youtu.be/qV0deLwEOhk):

¿Cómo Funciona Speculative Decoding?
La técnica de speculative decoding se basa en un proceso que busca acelerar la generación de texto de los modelos de lenguaje mediante predicciones previas. Esto se logra a través de la combinación de un modelo principal y un oráculo, el cual tiene la tarea de anticipar las respuestas posibles para reducir el tiempo de procesamiento.
Para entender mejor cómo funciona, imaginemos un ejemplo: supongamos que queremos completar la frase «El perro ladra». Antes de que el modelo principal comience a generar una respuesta, le pedimos al oráculo que intente predecir lo que va a decir. Supongamos que el oráculo predice: «El perro ladra a la luna llena».
Con esta predicción inicial, tenemos tanto la frase original como la posible continuación del oráculo. Aquí es donde entra el verdadero potencial de speculative decoding: los modelos de lenguaje pueden procesar varios «prompts» en paralelo. Es decir, en lugar de esperar a que el modelo genere cada token uno por uno, se reutilizan cálculos previos y se aceleran los resultados generando varios tokens a la vez.
Usamos estos prompts en paralelo para evaluar la predicción del oráculo añadiendo un token en cada prompt:

Al evaluar los prompts se genera el siguiente token:
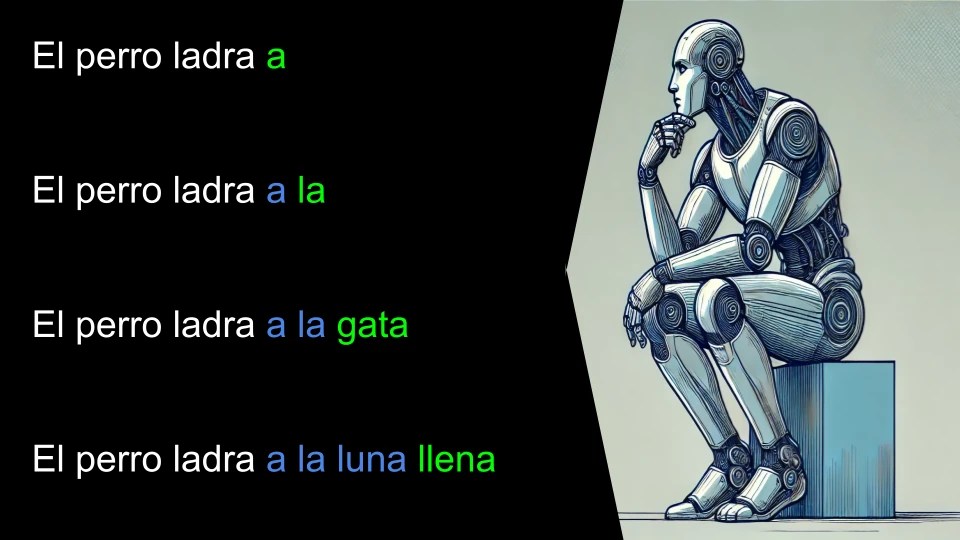
Ahora evaluamos en que caso el token sugerido por el oráculo y el predicho coincide:
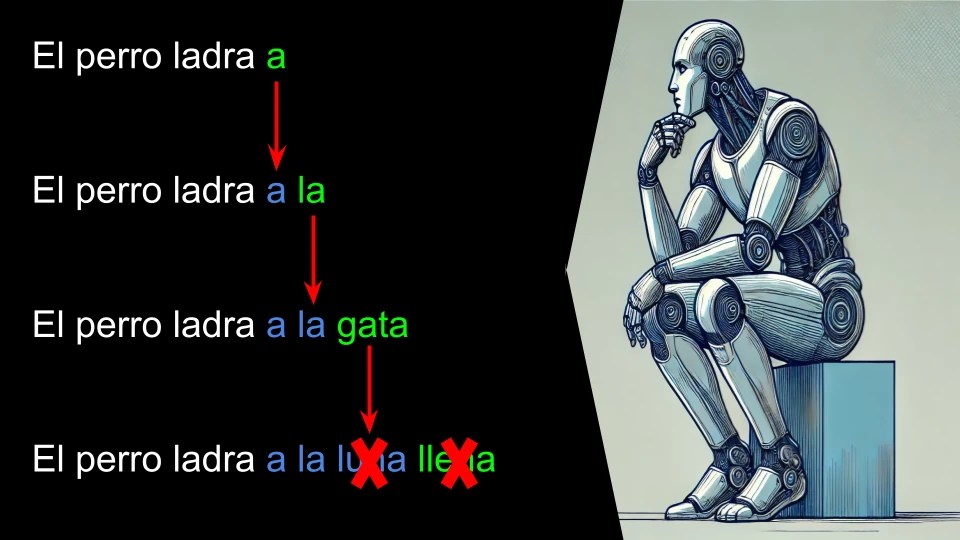
Cada token acertado lo damos como predicho correctamente por el oraculo.
En nuestro ejemplo con una sola iteración el sistema ha predicho 3 tokens: «a la gata«
En este caso cada iteración es más costosa que calcular un solo token sin speculative decoding, ya que hay que sumar el tiempo de ejecutar los múltiples prompts en paralelo (hay que recordar que se reaprovechan muchos cálculos) y de generar la predicción oráculo.
Si el oráculo acierta, se puede ahorrar una cantidad significativa de tiempo generando varios tokens de una sola vez. Este proceso tiene, sin embargo, ciertos riesgos y limitaciones. Cuando el oráculo se equivoca, se produce una penalización en términos de eficiencia, ya que se pierde el beneficio del procesamiento paralelo. Por ello, el rendimiento de speculative decoding está directamente relacionado con la precisión del oráculo.
¿Qué es el Oráculo?
El «oráculo» no es más que una manera de generar predicciones preliminares para acelerar el proceso de decodificación. A continuación, se presentan algunas de las diferentes alternativas que existen para un oráculo:
- Modelo más pequeño y rápido: Utiliza un modelo de lenguaje más pequeño para generar una versión preliminar de la respuesta.
- N-gramas: Consiste en el uso de patrones comunes de palabras que se encuentran en documentos similares. Esta técnica es efectiva cuando se trabaja con temas específicos, ya que aprovecha asociaciones típicas de palabras.
- Reglas heurísticas: Estas reglas permiten predecir cuál es la siguiente palabra basándose en patrones lógicos. Se han usado durante décadas en los entornos de desarrollo como sistemas de sugerencias.
- Uso del prompt: En tareas de resumen, es común que conceptos presentes en el prompt aparezcan también en la respuesta. Esta técnica aprovecha dicha redundancia para hacer predicciones más acertadas.
- Modelos Multi-Head: Estos modelos utilizan múltiples cabezas para predecir varios tokens a la vez, lo cual permite generar varias alternativas de predicción simultáneamente. Esto puede aumentar la eficiencia en comparación con modelos que predicen un solo token por vez.
Ventajas y Desafíos
La mayor ventaja de speculative decoding es la velocidad. Cuando el oráculo acierta, podemos generar varios tokens en el tiempo que normalmente tomaría generar uno. Sin embargo, esto está condicionado por la calidad de las predicciones del oráculo. Si falla con frecuencia, los beneficios desaparecen.
Para evaluar si merece la pena usar speculative decoding, podemos comparar el tiempo que toma generar un token con el método convencional frente al tiempo y la penalización que introduce el oráculo. Si la velocidad total resulta mejor, entonces vale la pena implementarlo.
¡Prueba Speculative Decoding!
Si estás interesado en probar esta técnica, puedes echar un vistazo al proyecto Llama.cpp, que incluye varios ejemplos y diferentes implementaciones de speculative decoding. En el directorio «examples/speculative», «examples/lookahead» y «examples/lookup» encontrarás las implementaciones que puedes usar para experimentar y explorar distintas opciones de speculative decoding.