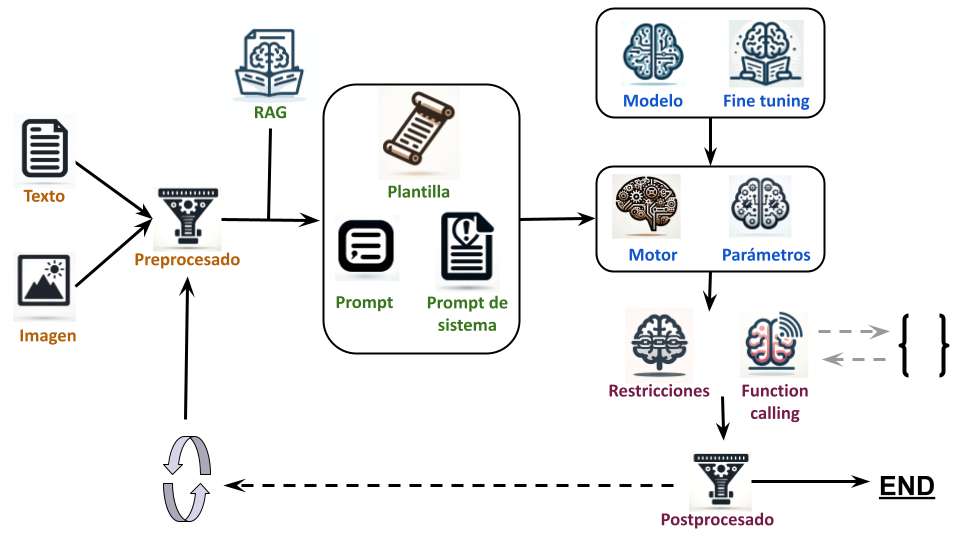
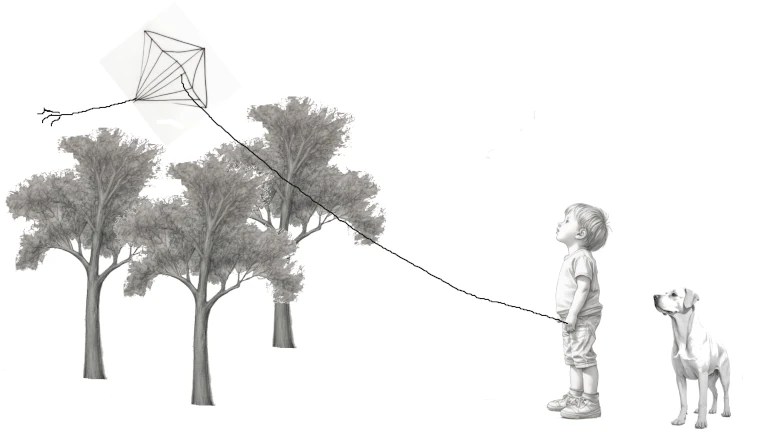
La forma más popular de usar una IA generativa es usar un prompt. Pero seamos sinceros, no parece una forma con que un artista tradicional se sienta cómodo. Cuando un artista quiere la imagen de un niño volando una cometa con un perro detrás no quiere «una imagen» de un niño volando una cometa con un perro detrás. Quiere «la imagen» que tiene en mente de un niño volando una cometa con un perro detrás.
En lugar de basarnos exclusivamente en prompts vamos a usar como base bocetos a «lápiz» (o con lo que sea que se dibuja ahora) o si no se te da bien el dibujo puedes generarlos con IA.
Para la parte de generar imágenes con IA vamos a usar Fooocus, en este vídeo tienes una rápida introducción al mismo:

Veamos como realizar el proceso en cuatro simples (o no, depende lo que te compliques la vida) pasos.
(Si prefieres ver el proceso en vídeo al final del articulo tienes un vídeo)
Paso 1: Generar los bocetos a «lápiz»
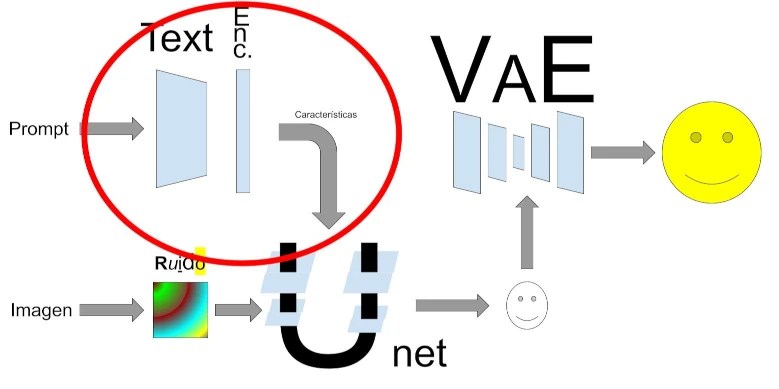
Si eres dibujante puedes hacer este paso a mano. Pero si, como me pasa a mi, tus manos son incapaces de hacer una linea recta y menos un dibujo medio decente puedes usar Stable Difussion para que te haga los dibujos. En este ejemplo vamos a usar este prompt:
draw [……..], draw in simple lines pencil, white brackground
En la linea de puntos describiremos lo que queremos que dibuje.
Os dejo algunos términos más para que exploreis: line art, sketch, hand drawn (cuidado que a veces dibuja manos), vector, svg, clipart, … En definitiva todo aquello que haga referencia a dibujos cuyas líneas estén claramente delimitadas.
draw a kid look up at sky, full body, draw in simple lines pencil, white brackground

draw a tree, draw in simple lines pencil, white brackground

draw a kite, draw in simple lines pencil, white brackground

draw a dog from side, draw in simple lines pencil, white brackground

Paso 2: Montar la escena
Ahora que tenemos nuestros bocetos vamos a ponerlos en la imagen, lo primero es borrar todo lo que no queremos, por ejemplo la cola de la cometa o las nubes y el suelo del dibujo del niño.
Posteriormente las colocamos sobre un fondo blanco. Para ello hemos de escalar cada imagen al tamaño deseado y pegarlas. Podemos rotarlas como el perro o la cometa y añadir detalles como la cuerda de la cometa
Paso 3: Aplicar el estilo
Ahora podemos usar Fooocus para aplicar el estilo que queramos. Para ellos vamos usar el siguiente prompt:
a kid flying a kite with a dog behind
El prompt lo puedes completar con diversos estilos ya sea seleccionándolos de la pestaña estilos de Fooocus, ya sea describiéndolos en el prompt, también puedes añadir al prompt elementos que te gustaría incluir como un sol o pájaros.

Paso 4: Corregir defectos
La imágenes resultantes tienen buen aspecto pero es necesario corregir algún detalle.
Para estas correcciones podemos usar técnicas tradicionales (por ejemplo, borrar las cometas sobrantes de alguna imagen clonando el cielo encima suyo) o inteligencia artificial. Para ello tenemos la técnica que se conoce como inpaint, que te permite seleccionar parte de una imagen y perdirle a la IA que la modifique.
En este caso vamos a usar una funcionalidad que permite mejorar la caras obtenidas en la foto. Podéis ver el resultado de usar esa herramienta:

Hay técnicas mucho más avanzadas pero esta es una buena forma de comenzar a trabajar con IA generativa si los prompts se te hacen muy incómodos
Puedes ver el proceso en el siguiente vídeo: