El templado o cocido o temple o recocido simulado es una metaheurística inspirada en el templado (o cocido o temple…) de metales (en algunos sitios hablan de espadas samuráis para hacerlo parecer más interesante. Como si una metaheurística necesitara algo más para parecer interesante…mejor no respondáis). La idea es que durante el templado los átomos van colocándose en las posiciones de menor energía aunque a veces pueden moverse a una de mayor energía. Este caso depende de la temperatura a la que esté en el material y a mayor temperatura más probable es que ocurra. Tampoco todos los saltos son igual de probables, a mayor diferencia de energía también es menos probable que ocurra.
Sonará ridículo, pero uno de los problemas que he encontrado con este algoritmo es que se suelen usar términos químicos para describirlo lo cual resulta confuso para los pobres programadores que no estamos acostumbrados a ellos. Así que dejando de lado el modelo real en que se inspira, el algoritmo es similar a la búsqueda aleatoria con el añadido de que tiene cierta probabilidad de aceptar una solución cuyo valor sea peor que la actual. Es decir, que las soluciones peores que la actual no se descartan siempre, se deja al azar si se conserva la actual (la mayoría de las veces) o se remplaza por la nueva solución. Esto le permite escapar de óptimos locales explorando zonas que de otra forma no visitaría. Eso sí, para evitar ir saltando de un lado a otro a lo loco y lograr converger en un máximo la diferencia entre los valores de la función fitness no puede superar un límite que se reduce con cada iteración con lo que es menos probable que se elija una solución peor que la actual. La formula que se aplica es que una solución de fitness f’ peor que f se acepta siempre y cuando:
e ^ (f-f’/ Ti ) > rnd(0,1)
Podemos ver que se usa e ^ x para calcular la posibilidad de que se elija esa solución. Para ello calculamos la diferencia entre ambas soluciones y la dividimos entre la temperatura actual. Hay que tener en cuente que este caso solo sirve cuando busquemos el mínimo (f’ es peor si f’ > f) pero si buscamos el máximo debería de ser f’-f ( f’ es peor si f’ < f). con esto debería de darnos siempre un resultado negativo ya que si f’ es mejor que f se elegiría directamente y no llegaríamos a este punto.
if(newFitness Math.random()){
this.cords = newCords;
this.fitness = newFitness;
}
Si nos fijamos en la gráfica de la función e ^ x entre -5 y 0 vemos que su valor decrece según aumenta la diferencia entre ambos valores. También podemos ver, que al estar dividida por la temperatura, cuanto mayor sea la misma más «tolerante» es con la diferencia. Como según se itera el algoritmo la temperatura se reduce cada vez es menos probable elegir una solución peor que la actual. Según disminuye la temperatura y el comportamiento del algoritmo se asemeja más a una búsqueda aleatoria.
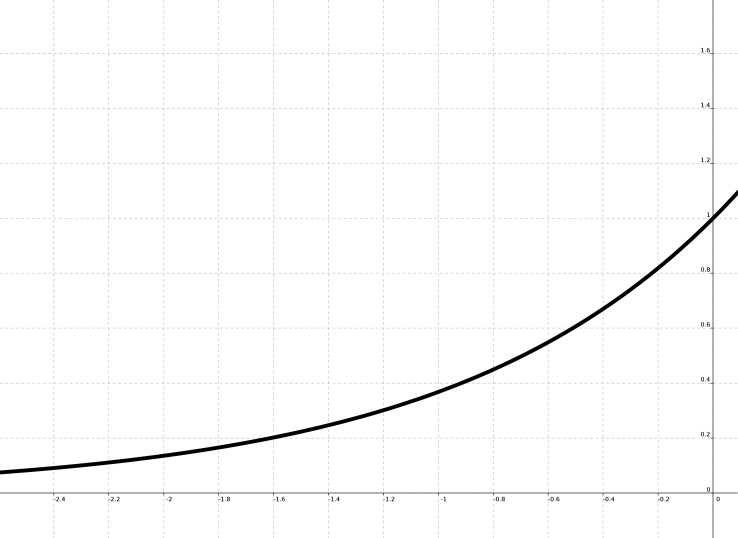
Gráfica de e^x para x < 0
Función de enfriamiento
La función de enfriamiento es la operación que se ocupa de reducir el valor de la temperatura cada iteración. Es más importante de lo que parece ya que es la temperatura la que permite saltar a soluciones peores y explorar el espacio de soluciones. Las dos más habituales son:
Restar un valor que sea muy pequeño «casi cero»
Ti = To – k * i = Ti = Ti-1 – k
Tiene la ventaja de que se puede calcular muy rápidamente. El problema es que es demasiado lineal y no suele dar tan buen resultado.
Multiplicar por un valor menor que uno pero cercano a él. O sea que sea «casi 1».
Ti = T0 * k ^ i = Ti = Ti-1 * k
Es rápida de calcular y da buen resultado. Variando el valor de k variamos «el comportamiento» alargando o acortando el rápido descenso inicial o lo «exploradora» que sea la metaheurística.
Algunas más complejas:
Ti = T0*k*i
Ti = (To/imax) * i
Ti = To/(1+k*ln(1+i))
La temperatura controla el umbral de aceptación de una variable. Si es alta es más fácil que una solución peor «pase el filtro». Así que lo ideal sería poder adaptarla según lo necesite el algoritmo. Acelerar su descenso, retrasarlo e incluso invertirlo. Para que el algoritmo converja en una solución es necesario que la tendencia general de la temperatura sea descender pero puede sufrir momentos puntuales de aumento. En concreto lo ideal sería que la temperatura aumente cuando esté intentando «escapar» de un óptimo local. ¿Como sabemos cuándo es eso? Sencillo, ocurre cada vez que se elige una solución peor que la actual. Nos podemos imaginar que la solución
Siendo
fbest la solución seleccionada hasta ese momento
f el valor de fitness para la solución elegida
Ti la temperatura calculada para la iteración i por alguno de los métodos anteriores
T’ = (1+(f-fbest/f))*Ti
Como f solo puede ser igual o mayor (es peor) a fbest. La formula actúa compensando la disminución de la temperatura cuando la solución empeora. De tal forma que combina ciclos de descenso con otros de ascenso aunque en teoría tendencia general es que la temperatura disminuya. ¡Ojo! Que es en teoría. Puesto que al subir la temperatura aumenta la probabilidad de que seleccione soluciones peores y cada vez que selecciona una soluciones peor aumenta la temperatura puede llegar realimentarse hasta que el aumento de temperatura se dispara.
Al final yo he optado por:
T’ = (1+(f-fbest/f))*Kinc + Ti
Al ser una suma se frena el aumento de temperatura y el parámetro Kinc permite controlar esta variación.
Aunque con los parámetros iniciales adecuados puede encontrar una correcta aproximación al óptimo global su desempeño en espacios de búsqueda muy grandes o con muchas dimensiones no suele ser muy bueno. También se usa como optimizador local.
Puedes encontrar el código aquí.


{kind=link}