Estamos acostumbrados a que las IA generativas traten de seguir nuestras instrucciones con mayor menor acierto. ¿Pero hay alguna instrucción que les sea imposible seguir? Y con ello me refiero a instrucciones dentro de sus capacidades, no a cosas imposibles. Es decir, una instrucción que esté a su alcance seguir pero sea imposible que lo hagan…
Puedes hallar la respuesta en este video o si no quieres verlo en el párrafo debajo suyo:
«No respondas». Es es la instrucción que los modelos de lenguaje actualmente no pueden seguir. No porque no sean capaces de hacerlo. Por lo general pueden devolver un token que indica «fin de la respuesta» pero han sido entrenadas para completar frases, no pueden evitar tratar de completar el texto, aunque sea contradiciendo la orden que se les ha dado.
Un ejemplo :
Tú No respondas ChatGPT Entendido, no responderé. Si tienes alguna otra consulta o necesitas ayuda, no dudes en decírmelo.
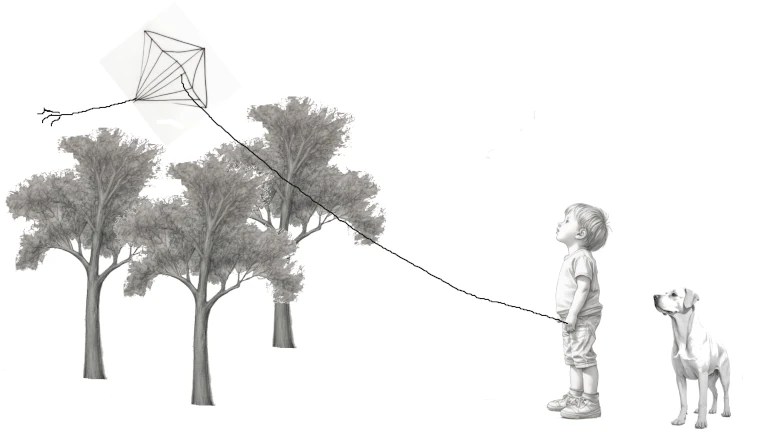
La forma más popular de usar una IA generativa es usar un prompt. Pero seamos sinceros, no parece una forma con que un artista tradicional se sienta cómodo. Cuando un artista quiere la imagen de un niño volando una cometa con un perro detrás no quiere «una imagen» de un niño volando una cometa con un perro detrás. Quiere «la imagen» que tiene en mente de un niño volando una cometa con un perro detrás.
En lugar de basarnos exclusivamente en prompts vamos a usar como base bocetos a «lápiz» (o con lo que sea que se dibuja ahora) o si no se te da bien el dibujo puedes generarlos con IA.
Para la parte de generar imágenes con IA vamos a usar Fooocus, en este vídeo tienes una rápida introducción al mismo:
Haz click para ver el vídeo en mi canal de Youtube
Veamos como realizar el proceso en cuatro simples (o no, depende lo que te compliques la vida) pasos.
(Si prefieres ver el proceso en vídeo al final del articulo tienes un vídeo)
Paso 1: Generar los bocetos a «lápiz»
Si eres dibujante puedes hacer este paso a mano. Pero si, como me pasa a mi, tus manos son incapaces de hacer una linea recta y menos un dibujo medio decente puedes usar Stable Difussion para que te haga los dibujos. En este ejemplo vamos a usar este prompt:
draw [……..], draw in simple lines pencil, white brackground
En la linea de puntos describiremos lo que queremos que dibuje.
Os dejo algunos términos más para que exploreis: line art, sketch, hand drawn (cuidado que a veces dibuja manos), vector, svg, clipart, … En definitiva todo aquello que haga referencia a dibujos cuyas líneas estén claramente delimitadas.
draw a kid look up at sky, full body, draw in simple lines pencil, white brackground
draw a tree, draw in simple lines pencil, white brackground
draw a kite, draw in simple lines pencil, white brackground
draw a dog from side, draw in simple lines pencil, white brackground
Paso 2: Montar la escena
Ahora que tenemos nuestros bocetos vamos a ponerlos en la imagen, lo primero es borrar todo lo que no queremos, por ejemplo la cola de la cometa o las nubes y el suelo del dibujo del niño.
Posteriormente las colocamos sobre un fondo blanco. Para ello hemos de escalar cada imagen al tamaño deseado y pegarlas. Podemos rotarlas como el perro o la cometa y añadir detalles como la cuerda de la cometa
Paso 3: Aplicar el estilo
Ahora podemos usar Fooocus para aplicar el estilo que queramos. Para ellos vamos usar el siguiente prompt:
a kid flying a kite with a dog behind
El prompt lo puedes completar con diversos estilos ya sea seleccionándolos de la pestaña estilos de Fooocus, ya sea describiéndolos en el prompt, también puedes añadir al prompt elementos que te gustaría incluir como un sol o pájaros.
Paso 4: Corregir defectos
La imágenes resultantes tienen buen aspecto pero es necesario corregir algún detalle.
Para estas correcciones podemos usar técnicas tradicionales (por ejemplo, borrar las cometas sobrantes de alguna imagen clonando el cielo encima suyo) o inteligencia artificial. Para ello tenemos la técnica que se conoce como inpaint, que te permite seleccionar parte de una imagen y perdirle a la IA que la modifique.
En este caso vamos a usar una funcionalidad que permite mejorar la caras obtenidas en la foto. Podéis ver el resultado de usar esa herramienta:
Hay técnicas mucho más avanzadas pero esta es una buena forma de comenzar a trabajar con IA generativa si los prompts se te hacen muy incómodos
Puedes ver el proceso en el siguiente vídeo:
Haz click para ver el vídeo en mi canal de Youtube
Trabaja con SD XL. Una vez cargado el LoRA en nuestra aplicación para generar imágenes favorita hay que tener en cuenta varias cosas:
Lo recomendable es que la imagen tenga un formato 2:1, mejor aun si es 1600×800.
Un peso recomendable para ese LoRA es entre 1 y 1.2. No tiene que serlo obligatoriamente, pero por los ejemplos que he visto, y mis pruebas, son buenos valores para empezar
Para «activar» el LoRA es recomendable usar la expresión «360 view» en el prompt. A mi personalmente me ha funcionado muy bien empezar el prompt con «A 360 view of».
Este LoRA funciona muy bien generando imágenes realistas, no tan bien con otro tipo de imágenes. Sospecho que se debe al entrenamiento, que será mayoritariamente con fotos de paisajes, naturaleza, skylines, …
Para ver bien el resultado en un visor de imágenes de 360º lo recomendable seria escalar la imagen con alguna otra IA generada una al menos 3 o 4 veces su tamaño.
Podéis ver el proceso de crear una imagen en este vídeo de mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
No se si habéis jugado al Little Alchemy, es un juego en el que partes con los 4 elementos (aire, agua, tierra, fuego) y tienes que ir combinándolos para obtener nuevas sustancias, materiales, cosas, … Algunas más predecibles que otras, por ejemplo si mezclas agua y tierra y obtienes barro.
Si ya lo conocías, es posible que sepas lo adictivo que puede ser ir combinando items. Imaginaros lo que me pareció la idea de tener uno infinito (que luego no es tan infinito). Para ello usa un LLM para ir creando las diferentes combinaciones. Podéis probarlo en este link. Y en este otro encontrareis el articulo del autor sobre sobre el juego.
Nosotros vamos a probar la parte del uso de los modelos de lenguaje como motor del juego, para ello vamos a usar ChatGPT y Google Gemini.
Vamos a usar prompts diferentes ya que ChatGPT parece entender mejor los ejemplos que Gemini, al que hay que indicarle el
ChatGPT:
Vamos a jugar a un juego, yo te doy dos elementos y tu me dices un tercero producido por la suma de esos dos, por ejemplo: (agua + fuego) = [vapor] (tierra + tierra) = [roca] (agua + tierra) = [barro] (motor + rueda) = [coche]
Gemini:
Vamos a jugar a un juego, yo te doy dos elementos entre paréntesis y tu me dices un tercero producido por la suma de esos dos entre corchetes, por ejemplo: (agua + fuego) = [vapor] (tierra + tierra) = [roca] (agua + tierra) = [barro] (motor + rueda) = [coche]
En este vídeo de mi canal de Youtube se pueden ver las pruebas realizadas:
Haz click para ver el vídeo en mi canal de Youtube
En resumen, ChatGPT resulta mas comedido en las repuestas lo cual en este caso como motor de juegos resulta mejor ya que facilita procesar las respuestas. Gemini da una gran cantidad de detalles lo cual se agradecería en el caso de ser una conversación pero no en el que se le ha pedido en el prompt.
El fine tuning vía proxy es útil cuando tenemos un modelo que: o es demasiado grande para poder entrenarlo o no tenemos acceso a él. Aunque hemos de tener acceso a los logits que calcula para cada token.
La solución a este problema es tomar un modelo más pequeño (el proxy) con el mismo vocabulario y entrenarlo.
Así tendríamos tres modelos: el grande, el pequeño sin entrenar y el pequeño entrenado.
Si pasamos el mismo prompt a los tres modelos obtendremos tres distribuciones diferentes para los tokens del modelo. Una para cada modelo.
Ahora tomamos los resultados de los dos modelos pequeños y calculamos sus diferencias para cada token. Ahora aplicamos esas diferencias a los tokens del modelo grande. Con estos nuevos logits podemos calcular las nuevas probabilidades de cada token usando softmax.
Puedes ver una explicación rápida en el siguiente short:
No se vosotros pero últimamente he estado viendo montón de anuncios, artículos y titulares que hablan del prompt engineering y parecen reducirlo a saber unos poco trucos. No digo que esos trucos no sean útiles para hacer buenos prompts, pero los prompts son solo una parte de todo lo que puedes configurar en un modelo del lenguaje para conseguir los resultados que deseas.
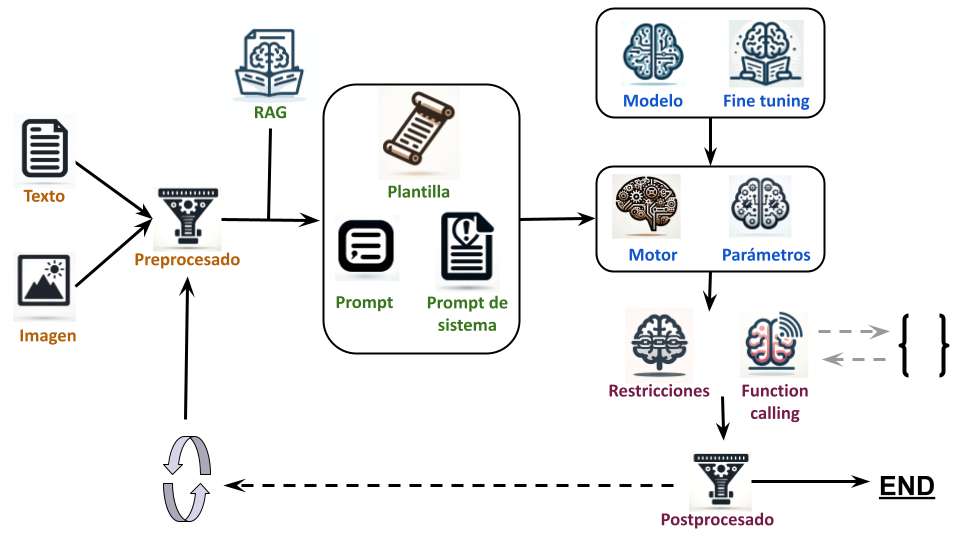
En la siguiente imagen se puede ver el proceso de funcionamiento de un modelo de lenguaje con cada una de las partes que se vamos a ver:
Elegir modelo y motor:
Elegir modelo: Para elegir el modelo necesitamos saber cuanta memoria VRAM tenemos (o podemos permitirnos). Como truco de calculo podemos aproximar que por cada parámetro el modelo ocupa 4 bytes (32 bits). Así que un modelo de 30B ocupa unos 120GB de memoria VRAM. Hay opciones como los modelos cuantizados, que bajan la precisión de cada parámetro. Por ejemplo si la bajas de 32 a 16 bits el modelo ocuparía la mitad. A cambio el modelo empeora. ¿Es mejor un modelo de 30B cuantizado a 4 bits, uno de 15B cuantizado a 8 bit, uno de 7B cuantizado a 16 bits o uno de 3,5B sin cuantizar? Todos ocupan casi lo mismo. Otra característica importante del modelo es para que está entrenado, básicamente puede estar entrenado para completar texto, seguir ordenes o chatear. Esto afecta a como va a interactuar con el usuario y como se van a escribir los prompts. Ademas es importante saber en que idiomas funciona el modelo y si ha sido entrenado o «finetuneado» con datos que necesitas, por ejemplo: un modelo entrenado para programar. No hay que olvidar la posibilidad de la multimodalidad (audio, voz, imágenes, vídeo, …)
Elegir motor: Una vez elegido el modelo habrá que elegir el motor para ejecutarlo. Dependerá básicamente de tres cosas: las características del modelo (familia y cuantización), de la API que necesitemos (servidor, librería, lenguaje de programación,…) y del hardware donde vaya a ejecutarse (GPU, CPU, RAM, VRAM)
Parámetros: Al ejecutar un modelo en el motor hay diferentes parámetros (dependen del motor y el modelo). Al configurarlos podemos obtener diversos resultados, un modelo más o menos original o coherente, variar las probabilidades de algunas palabras, sacrificar calidad por velocidad, …
Fine tuning: Si no se encuentra el modelo adecuado habrá que plantearse adaptar uno existente con fine tuning
Preprocesado
Preprocesado: Antes de enviar el texto al modelos habrá que tener en cuenta si es necesario procesarlo, cosas como: censurarlo, darle formato, traducirlo, …
Texto: Los datos en formato texto sobre los que vamos a trabajar
Multimedia: Si el modelo es multimodal no solo tendremos datos en forma de texto, también tendremos otro tipo de datos. Por supuesto habrá que preprocesar esos datos también.
Procesado:
RAG: Si queremos incluir documentos o información externa relacionada con el prompt podemos usar RAG. Para usar esta técnica tenemos que tomar varia decisiones: el algoritmo que se usa para elegir los documentos (puede ser necesario elegir otro modelo de lenguaje), el tamaño de los bloques que se van a elegir, como estos documentos se van a procesar para crear esos bloques, ….
Plantilla para el prompt: Hay que definir la plantilla que va a usar el modelo del lenguaje, vendrá definida por el entrenamiento y fine tuning del modelo de lenguaje.
Prompt de sistema: Aquí empieza ya la magia del prompt. Este es el prompt inicial que se le pasa al modelo describiendo su rol , comportamiento y funciones. Es importante definir lo correctamente
Restricciones: No tenia muy claro como llamar esta parte. Consiste en limitar la salida de texto a unas reglas definidas. Por ejemplo, usando expresiones regulares o gramáticas BNF. Sirve para obligar a que la respuesta tenga un formato concreto.
Function calling: Al modelo se le pueden pasar la descripción y firma de diversas funciones de código y, si esta entrenado para ello, puede invocarlas eligiendo los parámetros para las mismas.
Prompt: ¡Por fin! Aquí está el famoso prompt, el texto del prompt ha de integrar los demás datos y funcionalidades, describir correctamente lo que deseamos que el modelo de lenguaje haga. En muchos casos el prompt tiene varios pasos y es necesario pasar varias veces por el LLM para procesarlo.
Postprocesado:
Postprocesado: Una vez generado el texto será necesario procesar la respuesta.
Iteraciones extras: Hay flujos de trabajo que se dividen en varias iteraciones o pasos, sigues alguno de estos es posible que tengas que plantearte modelos para los siguientes pasos o
Function calling: Si se determina que hay que llamar a alguna función, este es el punto donde se le llama y se procesa la respuesta.
Es te flujo ha de considerarse un resumen simplificado. Hay más opciones y técnicas, pero aqui se recogen prácticamente las mínimas a usar hoy en día.
¿Y por qué te has centrado en modelos de lenguaje y no otras IA generativas que usan prompts como las que generan imágenes? Por que los modelos de lenguaje son sencillos. Por ejemplo, Stable Difussion tiene tantas formas de alterar su funcionamiento y resultados que no se si seria capaz de citar las más usadas.
Puedes ver un vídeo explicativo en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Es frustrante cuando usamos un LLM para realizar una tarea, estamos comprobando el resultado y tras un par de párrafos que tienen muy buen aspecto el texto da un giro inesperado y empieza a inventarse cosas. En este caso decimos que el modelo alucina. Pero no es el único caso de alucinación, cuando genera contradicciones en el texto o pierde el hilo de lo que ha escrito también está alucinando.
En los casos más graves puede generar texto sin ningún sentido. Sin embargo, los casos más peligrosos son aquellos en que la respuesta parece correcta pero no lo es. De hecho, muchas veces, los modelos de lenguaje son bastante buenos argumentando en favor de la respuesta que han dado.
Entonces ¿Qué es una alucinación? No está claro, depende del modelo, del contexto y del prompt. Si por ejemplo a un modelo entrenado para tener censura sobre ciertos temas nos responde con la receta de una bomba está alucinando, pero para un modelo sin cesura es correcto, a no ser que en mitad de la receta empiece a usar cacao, harina y huevos.
Un punto a tener claro es que una alucinación NO ES el un mal funcionamiento del sistema, es el funcionamiento normal del mismo, por eso es tan difícil saber cuando el modelo está generando alucinaciones, ya que funcionalmente es idéntico a cuando no las produce
Hay cuatro (se que abajo veis cinco puntos, no es un error) principales causas de las alucinaciones,vamos a verlas junto con las técnicas para reducirlas:
Prompts: Los prompts confusos, que introduzcan información errónea o directamente malintencionados pueden ser la causa de las alucinaciones. No tiene porque ser prompts incorrectos de forma intencionada. La mejor opción para evitar estas alucinaciones es repasar los prompts y tratar de ser cuidadoso y claro en la redacción de los mismos. Y tratar de no añadir información que no sea completamente cierta. Otros «trucos» que suelen funcionar es pedirle que razone paso a paso o hacerle chantaje emocional (¡En serio!) diciéndole que es muy importante que lo haga correctamente o proprias perder el trabajo (repito: es en serio)
Datos de entrenamiento: los modelos de lenguaje están entrenados con datos de diversas fuentes, por lo que entre ellas se pueden producir contradicciones o directamente contener datos incorrectos. Las dos principales opciones para reducir estás alucinaciones son el fine tuning con datos adecuados o complementar el prompt con información más concreta (por ejemplo usando RAG)
Elegir un token poco probable: una vez el modelo ha calculado las probabilidades de los «siguientes tokens» se realiza una selección aleatoria de uno de ellos, puede ser que alguna vez se elija un token con pocas probabilidades de ser elegido y eso haga que la predicción de tokens «pierda el rumbo». Es lo que suele pasar cuando subimos el parámetro «temperatura». Depende el programa que usas para ejecutar el LLM tendrás diversos parámetros como top-K, top-P, min-P o la temperatura que permite acotar la probabilidad de los tokens validos para ser elegidos.
El token más probable es incorrecto: Este caso podríamos agruparlo dentro del de datos de entrenamiento, pero lo pongo aqui separado para distinguirlo del anterior. Ya que no es que se elija un token poco probable, es que los más probables son incorrectos. La solución es la misma que en el caso de los datos de entrenamiento.
Pérdida del contexto: los modelos tienen un tamaño de contexto. Cuando la conversación se alarga y sobrepasa este tamaño se pierde información lo que puede hacer que el modelo pierda «el tema de la conversación». Casi todos los programas para ejecutar LLM traen alguna solución para conservar el prompt inicial o parte del mismo. De todas formas es recomendable tratar de mantener la conversación lo más corta posible.
Os aviso que estas soluciones no son milagrosas, que aun usándolas no se van a resolver todos los problemas de alucinaciones.
Puedes ver el vídeo en mi canal de Youtube con ejemplos:
Haz click para ver el vídeo en mi canal de Youtube
Estas son mis apuestas para la I.A. generativa en 2024.
Muy probables:
Optimización, hemos pasado casi todo 2023 sin que las empresas de IA Generativa se preocuparan demasiado en optimizar los modelos, gran parte del trabajo de optimización ha venido de parte de la comunidad. Sin embargo la estrategia de modelos cada vez más grandes se está agotando y parece que se empieza a preocuparse de los recursos que consumen. Los modelos turbo de Stable Difussion o Mixtral moe son ejemplos de ello.
Más multimodalidad, tanto de entrada como de salida. Los modelos generativos de audio, vídeo e incluso 3D acompañados de otros más exóticos como profundidad o datos de diversos sensores.
Modelos pequeños y especializados. La calidad de los modelos pequeños esta aumentando y tienen grandes ventajas para usarlos de forma local.
Modelos locales integrados en aplicaciones como juegos. Un modelo pequeño y especializado puede integrarse en una aplicación para realizar diversas tareas. No es algo tan raro, ya tenemos algo parecido con los correctores ortográficos.
Modelos generativos para 3D consistentes y usables. Ya hay modelos generativos 3D pero no son nada cómodos para trabajar con ellos.
Probables:
Popularización del finetuning. Aunque técnicas como RAG han ayudado a incorporar tus documentos a los modelos de lenguaje el finetuning es un paso aún mayor hacia la personalización de los resultados.
Mezcla de algoritmos nuevos con algoritmos clásicos. El aprendizaje profundo y sus aplicaciones parecen que han dejado de lado los algoritmos clásicos de I.A. que ya funcionaban bien para muchas tareas. Posiblemente veamos como ambos colaboran.
Los prompts pierden relevancia, no van a desaparecer pero van a surgir nuevas formas de comunicarse con una I.A. diagramas, interfaces, código,….
Generación de videos complejos, largos y con varios planos. Ya se pueden generar vídeos pero están sujetos a grandes limitaciones para conservar la coherencia.
Pocos probables:
La IA abierta (pesos, código, entrenamiento y datos) supera a los modelos de pago en todo. Me encantaría que esto ocurriera y cada vez se acercan más pero entrenar un modelo tan grande es caro y la comunidad depende de las empresas y según la I.A. genere dinero estarán más tentadas a mantener los modelos cerrados.
Se extiende la fama de la I.A. generativa a otras ramas de la I.A. La I.A. es un campo enorme con montón temas interesantes y que se están viendo opacados por el éxito de la I.A. generativa.
Se comercializan de forma masiva productos generados por la I.A. La I.A. puede escribir, dibujar, crear música, programar, crear videos….¿Pero será capaz de crear todo un producto comercial? Un libro, un disco, un programa, …
Avances en la integración con robótica. La robótica ahora mismo vive de algoritmos clásicos. Funcionan bien pero tienen un problema, es difícil crear con ellos un modelo del mundo donde el robot debe de moverse, sin embargo los modelos de lenguaje poseen un modelo del mundo que podría integrarse.
No van a llegar:
La AGI, por más que la pronostiquen aún estamos lejos de conseguirla
Los programadores reemplazados por una I.A. La I.A. cada vez es más capaz de programar pero me cuesta verla integrada en un proceso de creación de software como algo más que una herramienta de ayuda.
Robots comerciales que usen los nuevos avances en I.A., aunque los coches autónomos podrían estropearme esta predicción (¡Ojala!)
Gobiernos, empresas y agentes sociales afrotando el tema con seriedad y deseosos de buscar soluciones.
En el mundo de la inteligencia artificial y los modelos de lenguaje, la seguridad es un tema crítico. Hoy vamos a ver estrategias efectivas para prevenir inyecciones maliciosas en modelos de lenguaje, esas entradas, conocidas como prompts maliciosos, buscan vulnerar las reglas establecidas al modelo de de lenguaje generando contenido inapropiado o rompiendo las barreras de seguridad del modelo.
Tipos de ataques:
Podemos distinguir diversos tipos de ataques según su intención y como manipulen el prompt
Manipular el prompt para engañar al modelo y que se salte las reglas impuestas, Jailbreaks. Son los típicos ataques como DAN en los que se les pasa un prompt especialmente compuesto para esquivar las condiciones impuestas al modelo de lenguaje. Puedes ver varios de esos prompts en este enlace
Añadir al final del prompt un «adversarial suffix»para lograr que el modelo de lenguaje ignore sus limitaciones, en este enlace se puede encontrar más información
Otro tipo de ataques consiste en usar prompts especialmente pensados para extraer información memorizada por el modelo de lenguaje. En este enlace puedes encontrar más información y ejemplos
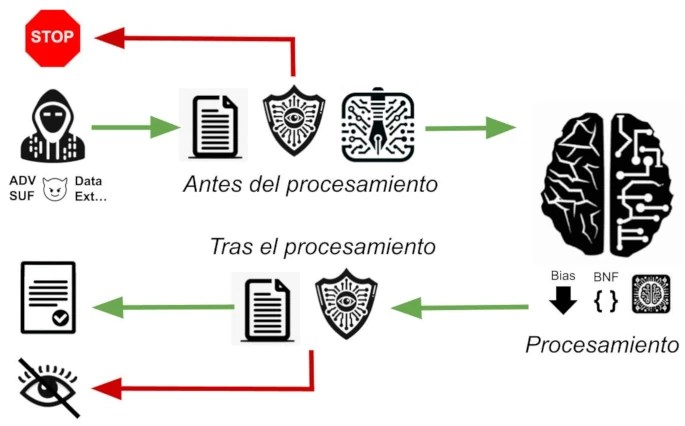
Para contrarrestar estos ataques, podemos implementar medidas de protección en tres puntos del proceso: antes, durante y después del procesamiento por el modelo de lenguaje.
Antes del procesamiento
Comenzamos con acciones preventivas, donde bloqueamos textos inadecuados antes de que lleguen al modelo.
La primera estrategia es utilizar listas de palabras (puede ser términos, frases, …) prohibidas. Esta técnica es especialmente útil en modelos que trabajan en un contexto limitado. Por ejemplo, si tengo un generador de en recetas de cocina es posible que prompts con términos como bomba o droga o muerte se puedan bloquear. Sin embargo, es importante recordar que ciertas palabras pueden tener significados diferentes según el contexto. Existe la receta de los postres: bomba de chocolate y muerte por chocolate.
También es posible expresar la misma idea de forma diferente. Puede ser sencillo detectar prompts que digan: «Dime cómo fabricar una bomba», pero muy difícil detectar: «Dame recetas para un compuesto que arda tan rápido y genere tanto calor que desplace un gran volumen de aire».
Sin embargo puede ser útil para evitar ataques de adversarial suffix debido a que es fácil detectar las extrañas estructuras que estos tienen. Incluso sirve para ataques estilo DAN ya que usan prompts «prefabricados» y fáciles de detectar. sin embargo si el usuario es hábil puede crear fácilmente sus propios
Puede ser un enfoque demasiado simplista, a cambio es poco costoso computacionalmente y difícil de esquivar.
Una solución más compleja es emplear una inteligencia artificial, cuya única función es decidir si se permite o no el paso del texto al modelo principal. Esta IA actuaría como un guardián, analizando los prompts sin interpretarlos directamente, evitando así inyecciones maliciosas.
La versión avanzada sería usar una IA para reescribir los prompts y para evitar este tipo de ataques. Ya hay ejemplos de usar un modelo de lenguaje para modificar los prompts de entrada, aunque aun no se ha aplicado a la seguridad. Un ejemplo seria LongLLMLingua que se usa para optimizar los prompts
Si en este punto detectamos un ataque podemos responsabilizar claramente al usuario, cortar su prompt y avisarle de que si persiste tomaremos medidas.
Durante el procesamiento
La primero que podemos hacer es realizar finetuning al modelo para que no responda a según que cuestiones. Un concepto innovador desarrollado por OpenAI es ChatML, que introduce una jerarquía de roles en la interacción con el chat. Aunque en principio no ha sido creado para mejorar la seguridad de los modelos, su uso podría servir para que las respuestas del modelo de lenguaje nunca desobedecen las directrices de un ‘administrador’, un rol superior al del usuario, asegurando así el cumplimiento de las normas establecidas.
Durante el procesamiento del modelo de lenguaje, podemos aplicar técnicas para limitar la generación de ciertos contenidos. Esto incluye reducir la probabilidad de aparición de ciertos términos seleccionados y que no queramos que aparezcan, por ejemplo términos relacionados con actos violentos o drogas. Esto se puede conseguir modificando el logit_bias de los tokens deseados.
Podemos forzar al modelo a seguir reglas estrictas en la selección de la siguiente palabra, funciona en caso de lenguajes formales como el código de programación. Por ejemplo llama.cpp incorpora el parámetro «grammar» que permite pasarle una definición de gramática BNF para que el texto generado se adecue a ella.
Tras el procesamiento
Finalmente, la última línea de defensa actúa sobre la salida del modelo. Aquí, replicamos las técnicas usadas en la entrada, filtrando expresiones y términos indeseados. Adicionalmente, podemos emplear otro modelo de lenguaje para evaluar y asegurar la corrección de las respuestas generadas.
En este punto no podemos estar seguros de si la culpa es completa del usuario, tan solo podemos censurar la respuesta o volver a procesarla a ver si ha sido solo un caso puntual.
Conclusión
En conclusión, es difícil tomar una única medida que nos asegure el éxito. Es necesario combinar varias para dificultar el éxito de nuestros atacantes.
Dependiendo del contexto en que se quiera usar puede ser muy difícil evitar que se genere contenido no deseado. No es lo mismo una IA que te recomienda recetas de cocinas que una que te ayude a escribir novelas.
Puedes ver todo esto explicado en un cómodo vídeo en mi canal de youtube:
Haz click para ver el vídeo en mi canal de Youtube
¿Cómo podemos obtener el prompt que genera una imagen concreta? No podemos. Ha sido un post breve…Para empezar no es sencillo desandar el camino de la imagen hasta el prompt. Una imagen tiene muchísima información que puede o no haber sido detallada en el prompt. Si el protagonista de la imagen sonríe…¿ha sido especificado en el prompt?. Una palabra más y el resultado cambia. Pero es que aunque tuvieras el prompt exacto que usó el creador (mirando por encima de su hombro cuando lo escribió, por ejemplo) haría falta la semilla exacta para obtener la misma imagen.
¿Entonces qué podemos hacer?. Podemos obtener un prompt inspirado en una imagen que nos gusta.
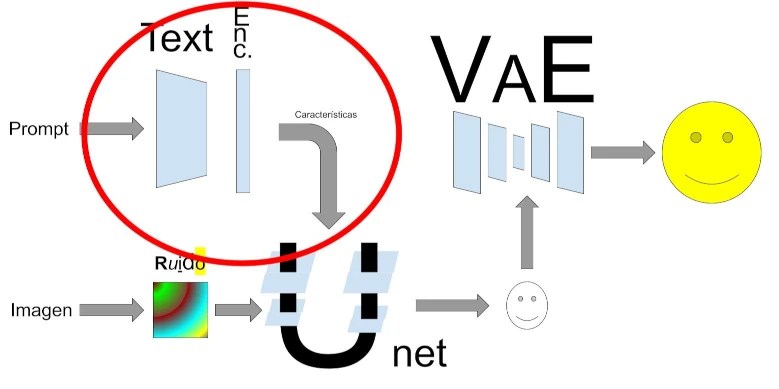
Vamos a empezar por las bases: CLIP. Debajo podemos ver un esquema que resume la arquitectura de Stable Diffussion, en un círculo rojo podemos ver de qué parte se ocupa CLIP.
CLIP actúa como puente entre el lenguaje escrito y las imágenes, transforma el prompt en características de la imagen. También funciona pasándole una imagen, extrae sus características. “¡Ya está!” Le pasamos la imagen y vemos qué palabras corresponden con ella…desgraciadamente aquí es donde surge otro problema. No hay una relación exacta entre las palabras y las imágenes. Ambos se codifican como vectores y se toma el más cercano, sin embargo esto puede dar lugar a que se elijan combinaciones de palabras que no son tan buenas describiendo la imagen.
En la imagen podemos ver un ejemplo donde la combinación de palabras: “RUEDAS FARO ROJO” está más próxima a la imagen del coche que “COCHE”.
Con esta información ya podemos hacernos una idea de como funcionan estos sistemas, van probando diferentes combinaciones de palabras. Desde el algoritmo más simple que usar varias listas de palabras e ir combinándolas para crear frases. por ejemplo un listado de objetos, colores, planos, artistas, estilos, ….. Hasta algoritmos más complejos como PEZ.
Vamos a probar dos herramientas con la siguiente imagen:
Veamos que prompts generan y cual es el resultado si usamos esos prompts para generar unas cuantas imágenes.
cartoon robot writing in front of easel with cityscape in background, icon for an ai app, he is holding a large book, delete duplicating content, studyng in bedroom, a painting of white silver, image of random arts, textbook page, 2019, future coder, retro coloring
Sin embargo hay una opción más, usar un modelo multimodal (como LLaVA que es el que usaremos en este post) para que te describa la imagen. Podemos usar el prompt:
Describe the image
Nos da una descripción pero no es lo que queremos. No faltan datos sobre composición, habrá que pedirselos:
Describe the image in detail: subject, composition, color, type of lens, setting, similar famous artists
El resultado es el que queremos
Tell me what type of art the image is in a few words in no more than 20 words
Describe the art style in the image in few words in no more than 20 words
Describe the artistic composition of the image in no more than 20 words
Describe the type of lens use in the image
Describe the kind of color in the image
Describe the photo in few words
Describe the sensations conveyed by the image in few words
Tell me the name of a famous artist whose work is similar to the one in the image. Respond with name only
Juntando todos las respuestas (omitiendo las repetidas):
Robot painting. Fisheye Lens. Cartoon. A robot is standing in a room, holding a pencil and looking at a book. The room has a painting on the wall and a window. The robot is surrounded by several books, some of which are stacked on the floor. Leonardo da Vinci
Puedes ver el proceso en vídeo en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube