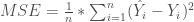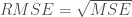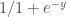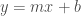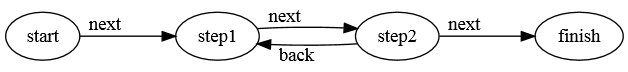El error cuadrático y el R cuadrado se usan como medidas para evaluar el desempeño de un estimador. Es decir cual es el error que comete al estimar un valor. Un ejemplo de estimador seria, por ejemplo, una regresión, ahora si no interesa saber lo bien que estima esa función podemos hacerlo a partir de direrente estimadores.
Para calcularlos se usan dos valores, el valor real y el valor devuelto por nuestro estimador (representado por la Y con «sombrerito»). El error para cada caso es el valor absoluto de la resta de ambos valores:
Se puede entender intuitivamente de forma muy simple, es la diferencia entre el valor que obtenido del estimador y el valor real. Se usa el valor absoluto para que cuando se sumen varios errores no se «cancelen». Si al estimar un valor se equivoca en 3 y al estimar otro en -3 el error total es 6 no 0.
Su calculo en Arduino seria:
double error = abs(y - ey);
Error medio absoluto
No podemos valorar un estimador solo por el error en una estimación, habrá que usar varias y calcular la media del error a lo que se le llama «error medio absoluto«, la suma del error de cada medida partido por el número de muestras:
Para implementarlo en Arduino vamos a usar el mismo «truco» que usamos para calcular diferentes estadisticos en Arduino. Usando la versión acumulada del calculo de la media para no tener que guardar todos los valores:
meanError = meanError + ((error - meanError)/n);
Error cuadrático medio
Otro valor usado es la media del error al cuadrado:
Para implmentarla en Arduino vamos a usar el mismo «truco» que antes para el error medio:
El problema de elevar los valores al cuadrado es que cuantificar su diferencia resulta poco intuitivo. Para hacer el valor más entendible se puede usar la raiz cuadrada del error cuadrático medio:
En código para Arduino:
sqrt(meanError2);
Todo esto lo puedes ver implementado en los ficheros error.h y error.cpp de SimpleStatisticsArduino
La regresión lineal se usa como clasificador binario entre dos conjuntos. En el caso ideal de regresion logística para cualqueir valor de x devuelve un valor de y que es 0 o 1 dependiendo de a que clase pertenezca. Pero en la vida real rara vez suele ser un «caso ideal» y hay valores para los que devolverá un valor comprendido entre 0 y 1. Este resultado puede interpretarse como la probabilidad de que sea del grupo representado por el valor 1 o cuadno esto carezca de sentido simplemente tomar cualqueir valor mayor de 0,5 como del grupo del 1 y cualquie valor por debajo como del grupo del 0.
La función sigmoide se define como:
El valor de y lo podemos sacar de la regresión lineal:
Juntandolo todo:
Veamos las diferencias entre ambas fórmulas:
Regresión lineal (verde) comparada con regresión logística (naranja)
Regresión Lineal:
Su fórmula define una linea
No está acotada, no tiene un valor máximo ni mínimo
Se usa para estimar valores.
Devuelve un valor numérico
Regresión logística:
Su fórmula define una "S"
Esta acotada entre 1 y 0
Se usa para clasificar un valor en uno de dos grupos. Clasificador binario.
El resultado que devuelve se puede interpretar de dos maneras: como probabilidad de pertenecer a un grupo si se toma el valor directamente o como pertenencia absoluta a un grupo u otro si se considera que cuando el valor obtenido este por encima de 0,5 se pertenece a uno y por debajo al otro.
Forma de implementarlo
La forma de implementar esto en un Arduino es aprovechar la librería que ya tenemos de regresión lineal y que nos soluciona los problemas de memoria y tiempo de cálculo que tienen los cálculos estadísticos en Arduino. Simplemente una vez que nuestro sistema aprenda el modelo lineal basta con transformar el resultado que devuelve este modelo para convertir su respuesta a la de una regresión logística.
La implementación del código se puede encontrar en la librería Regressino
Utilidad
¿Tiene sentido transformar una regresión lineal en un modelo de regresión logística?. Aunque esta conversión se puede realizar para cualquier regresión lineal no tiene sentido hacerlo. Solo tiene sentido usarlos cuando se quiera entrenar un clasificador binario y haya dos grupos de elementos claramente diferenciables. Entonces se puede calcular la recta de regresión y convertirla en una regresión logística que funcione como clasificador.
Tampoco va servir para calsificar cualquier grupo de elementos, han de ser linealmente separables. dicho de forma más intuitiva, tienen que poder separarse trazando una linea recta entre ellos.
En definitiva, sin ser una opción ideal, es suficiente buena y útil como para plantearse su uso.
Como ya vimos en el post sobre regresión lineal en Arduino, el principal problema que plantea Arduino para realizar cálculos estadísticos es la escasa capacidad de memoria y cálculo que tiene. Para ello en lugar de guardar todos los datos vamos a usar formulas que permiten aproximar los valores estadísticos que vamos a utilizar sin gastar casi recursos, la idea es guardar solo una aproximación.
En el siguiente enlace puedes encontrar la librería SimpleStatisticsArduino de Arduino que implenta lo explicado en este texto.
Para la varianza y la media usaremos las siguientes formulas que tratan de aproximar
Ahora con estos dos valores podemos calcular el valor central, que no es lo mismo que la media:
centro = (maximo – minimo) / 2;
Con esta estrategia solo necesitamos 6 variables para almacenar los datos sobre los que se calcula la estadística.
Estadística con dos variables en Arduino
Tenemos dos variables X e Y, partiendo de los cálculos del apartado anterior para cada una ahora podemos calcular los valores conjuntos, para ello debemos de almacenar dos variables más necesarias para calcular la covarianza:
Lo que vamos a ver en este texto tiene bastante de truco matemático, pero funciona lo suficientemente bien para que merezca la pena hacerlos.
Ya en otro post vimos como implementar la regresión lineal en Arduino, aprovechando ese mismo código se puede calcular la regresión para otras funciones que se pueden adaptar mejor a los datos que la lineal.
Cómo de aquí en adelante nos hará falta vamos a recordar que la fórmula de la regresión lineal es:
y = a + b*x
El algoritmo de la regresión lineal lo que hace es a partir de ejemplos de valores de x e y calcular los valores de a y b
Ahora intentemos explicar el truco que usamos. Primero tomamos la función que queremos ajustar a los datos, por ejemplo:
y = a * e^(b*x)
Buscamos una transformación lineal que deje la fórmula de la misma forma que la de la regresión lineal. En nuestro ejemplo calcular el ln de ambos lados de la igualdad:
ln(y) = ln(a) + b*x
Este truco solo funciona cuando sea posible encontrar una transformación de este tipo, que no siempre se puede.
Realizamos cambios de variables para transformar la formula:
x -> x y -> ln(y) a -> ln(a) b -> b
Ahora podemos usar el mismo algoritmo que en la regresión lineal solo que con un par de cambios de variables:
En la fase de aprendizaje, cuando tengamos la pareja de valores (x,y) le pasaremos al algoritmo de regresión lineal (x,ln(y))
Una vez calculados los parámetros no tendremos (a, b) si no (ln(a), b) por lo que para obtener a tendremos que elevar e al valor obtenido a = e ^ln(a)
Ahora que tenemos los parámetros (a,b) para estimar un valor en lugar de usar la ecuación de la recta (regresión lineal) usaremos y = a * e^(b*x)
Regresión exponencial
La fórmula de esta regresión es:
y = a*e^(b*x)
La transformación lineal que vamos a usar es:
ln(y) = ln(a) + b*x
Como ya hemos visto los cambios de variable son:
x -> x y -> ln(y) a -> ln(a) b -> b
En pseudocódigo:
regExp::learn(x,y){
regLineal.learn(x,ln(y));
}
regExp::calculate(x){
a = e ^ regLineal.a;
b = regLineal.b;
y = a*e^(b*x);
return y;
}
Regresión logarítmica
La fórmula de esta regresión es:
y = a*ln(x)+b
La transformación lineal que vamos a usar es:
y = a*ln(x)+b
Efectivamente es la misma puesto que ya tiene la forma deseada.
Los cambios de variable son:
x -> ln(x) y -> y a -> a b -> b
En pseudocódigo:
regLog::learn(x,y){
regLineal.learn(ln(x),y);
}
regLog::calculate(x){
a = regLineal.a;
b = regLineal.b;
y = a*ln(x)+b;
return y;
}
Regresión potencial
La fórmula de esta regresión es:
y = b*x^a
La transformación lineal que vamos a usar es:
ln(y) = a*ln(x)+10^b
Los cambios de variable son:
x -> ln(x) y -> ln(y) a -> a b -> 10^b
En pseudocódigo:
regPot::learn(x,y){
regLineal.learn(ln(x),ln(y));
}
regPot::calculate(x){
a = regLineal.a;
b = 10^regLineal.b;
y = b*x^a
return y;
}
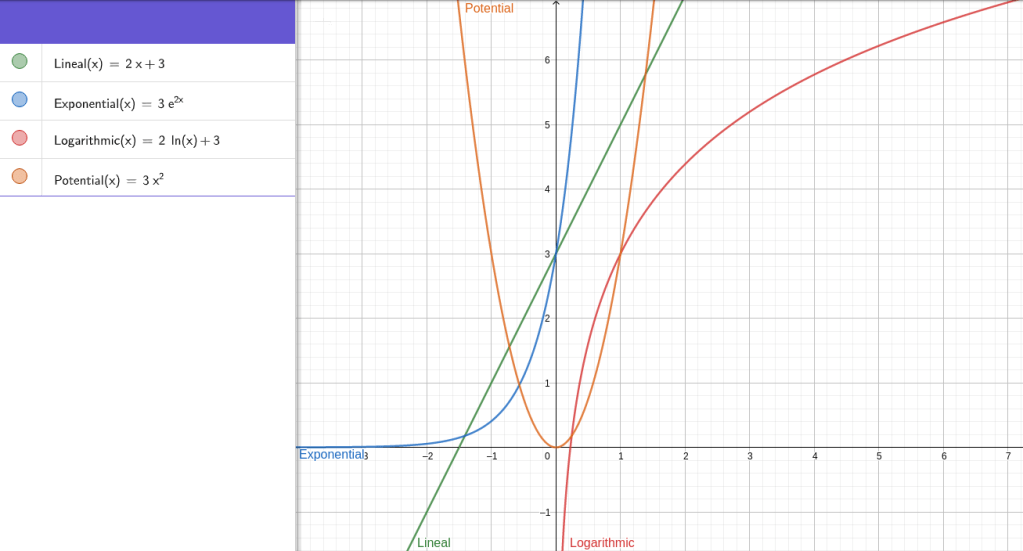
Ejemplo gráfico
Para ver bien las diferencias entre las cuatro regresiones dejo esta imagen donde se pueden ver todas para los valores a= 1 y b = 3
Comparativa entre las cuatro regresiones con a= 2 y b = 3
La librería
Todo lo aquí explicado se puede encontrar en la librería Regressino que implementa estas cuatro regresiones con ejemplos de como usarlas
¿Sabéis esas películas en las que hay que lanzar una cabeza nuclear y dos personas han de meter su código, ya sea a mano o con una llave, para autorizarlo?. Eso es el secreto compartido. Una contraseña que está «dividida» en partes que tienen que juntarse para poder usarse. Hay esquemas de secreto compartido que permiten configuraciones mucho más flexibles, pero también son más exigentes en cuanto a recursos. Para el caso más simple de una contraseña y dos partes este sistema es suficiente.
Veamos cómo es el sistema. Tenemos una contraseña K que lanza los misiles. Está contraseña es dividida en dos contraseña K1 y K2. Al juntarlas se obtiene la contraseña K. Para que el sistema sea seguro ambas han de ser igual de difíciles de adivinar que K y cualquiera de ellas por separado no ha de aportar información que reduzca la dificultad de adivinar K.
Lo primeros que pensaréis será: «Tomamos la contraseña (K) de un tamaño de N bits y la dividimos en otras dos (K1,K2) de tamaño N/2 y listo». Es cierto que funciona, pero tiene varios problemas, el principal es que estás desvelando información sobre K a quien posea una de estas partes.
Veamos otra aproximación. Generamos una contraseña K1 aleatoria de N bits. Está claro que K1 no aporta ninguna información sobre K, aunque por ahora tampoco nos sirve de nada. Será K2 quién los relacione. Para ello realizamos una operación xor entre K1 y K bit a bit.
Los poseedores de K1 no tienen ninguna pista que les ayude a calcular K o K2. Y lo mismo para quién posea K2.
Veamos un ejemplo:
K = 00110100 K1 = rand() = 10011011 K2 = K xor K1 = 10101111
K1 xor K2 = 00110100 = K
Una de las ventajas de este sistema es que puedes crear tantas parejas de claves como quieras.
Es poco probable que tengas armamento nuclear en casa. Pero esta idea es aplicable sobre cualquier sistema que use contraseñas.
Si estás buscando un algoritmo «mágico» que clasifique colores en esta entrada no lo vas a encontrar, más bien vas a descubrir lo complicado que es un tema que de primeras parece muy simple y posibles alternativas para clasificar colores.
La primera pregunta que tenemos que hacernos es ¿Cuántos colores hay?. Lo más probable es que los que están acostumbrados a trabajar con colores en el ordenador digan «unos dieciséis millones» y es cierto. Pero sería duro ponerle un nombre a cada uno así que seamos un poquito menos quisquillosos y pensemos como agruparlos. Cómo vamos a usar el sistema RGB podemos empezar por los colores que no sean mezcla de ningún otro: rojo, verde y azul. Luego los que son mezcla de otros dos colores: amarillo, cían, magenta. Por último los que son mezcla de los tres: blanco, gris y negro.
Pero no basta con esos colores, claramente hay más: ocre, marrón, turquesa, naranja, morado, lila, malva, rosa…No hay una definición exacta de cuántos colores hay, ni siquiera de que significa cada nombre, algunos colores se solapan. Tanto que directamente a los colores entre los dos algunos les llaman cosas como verde-amarillos, rojo-naranjas,….
Pero aunque nos parezca que los colores son algo bastante universal no es así. Hay influencias culturales que hacen que algunos colores caigan a un lado u otro de la frontera, colores que son verdes o azules dependiendo de la cultura de donde sea el que los ve.
También hay factores fisiológicos que hacen que veamos los colores de forma diferente. No hay más que recordar alguna discusión en internet sobre de qué color es algo que aparece en una foto.
Y por último nuestra percepción de un color puede cambiar por influencia de los colores que lo rodean. Tomas un verde-amarillo lo pones junto a los verdes y lo ves amarillo, lo juntas con estos y lo ves verde. Tan sorprendente como frustrante.
Conociendo todas estas pegas y sabiendo que acertar al 100% es difícil por lo que no hay una solución ideal vamos a ver algunas soluciones.
Usar colores de referencia
Lo primero que se nos ocurre cuando hablamos de clasificar colores es tomar unos colores representativos como referencia. Cuando queramos clasificar un color medimos la distancia a cada uno de estos colores de referencia y elegimos el más cercano. Básicamente es un algoritmo del vecino más cercano. Ya hemos visto como calcular la diferencia entre dos colores, solo nos queda elegir los colores de referencia.
El problema es que no hay un espacio de color con una frontera clara y definida por lo que hace falta una gran cantidad de puntos de referencia. Generar ese listado de puntos es costoso, tiene que ser generado por humanos y resolver las diferencias de opinión entre ellos. Cómo creo que no tenemos recursos para hacer eso y tenemos que trabajar con tamaños de muestra muy pequeños el funcionamiento no es el ideal.
Espacio HSL
Una ventaja del espacio HSL (matiz, saturación, luminosidad) es que es relativamente fácil de saber el color. Basta con fijarse el valor del componente H o matiz, que viene expresado en grados o radianes. Con él ya puedes distinguir entre varios colores. Los más habituales son:
0 rojo
30 naranja
60 amarillo
120 verde
180 cian
240 azul
300 magenta
330 rosa
360 rojo
La componente L el indica «la luminosidad» del color. Viene expresada en %. El 50% es el tono puro del color. Por encima los colores son cada vez más claros y por debajo más oscuros. Si es muy bajo esta cerca de color negro y si es muy claro lo está del blanco. Cómo referencia podemos usar estos valores:
0, 2 negro
3, 8 casi negro
9, 39 oscuro
40, 60 [nada]
61, 91 claro
92, 97 casi blanco98,
100 blanco
El componente S indica la saturación del color, está expresado en %. Un valor muy bajo indica que está cercano al gris:
0-2 gris
3-10 casi gris
10-25 grisáceo
25-50 pálido
Aún así hay colores problemáticos como el marrón que surge de algunos rojos o narajas (o rojo-naranjas) muy oscuros. O los tono pastel que la mayoria surgen cuando la saturación y la luminosidad estan entre el 70% y el 85%.
Lista de colores
Hay otra opción, usar un listado de colores y sus nombres, buscar el más cercano y usarlo como respuesta. Aunque usar términos como «verde menta», «amarillo eléctrico», «rosa pastel» nos parezca menos exacto que los métodos anteriores, para los seres humanos resulta más fácil de entenderlos y muy intuitivos.
El principal problema es que no hay un estándar de que es el color «verde menta» puedes encontrar montones de listados y en cada uno puede un valor distinto o el mismo color llamarse de otra manera.
Las listas de colores se pueden conseguir de catálogos de pinturas, de la Wikipedia o de estándares como por ejemplo los colores web.
¿Por cual optar?
Si necesitar clasificar el color dentro de una lista cerrada de los mismos lo mejor es el primer método.
Si necesitas clasificar cualquier color dentro del espacio de colores sin tener colores de referencia.
La tercera resulta útil para mostrar resultado a los humanos.
Seguro que todos los que tenemos cierta edad tenemos programas desarrollados para MS-DOS que siempre hemos querido recuperar pero nunca hemos tenido tiempo de volver a programarlos en algo más moderno. En mi caso eran varios videojuegos que había desarrollado cuando era adolescente.
Para ello vamos a usar dos herramientas: DOSBox, JS-DOS (en este caso la versión 6.22).
Preparando la aplicación
Lo primero de todo es montarse DOSBox en tu ordenador e instalar la aplicación que queramos usar en la web. Vamos a llamarla programa.exe. Una vez instalada la iniciamos y la configuramos tal y como queramos que se ejecute desde la web. Si necesitamos incluir algún fichero para que lo abra la aplicación ahora es el momento.
Una vez terminado el paso necesitamos comprimir todos los ficheros necesarios para que funcione la aplicación en un fichero zip. Lo ideal sería que el ejecutable programa.exe quede directamente en la raíz del zip para que al descomprimirlo no quede dentro de ninguna carpeta.
Todo este proceso no es necesario que lo hagamos desde DOSBox, para instalar la aplicación hay que «montar’ una carpeta del ordenador como si fuera una unidad de disco de DOSBox, puedes comprimir allí los ficheros.
Ejecutandola en una web
Vamos a suponer que el fichero se llama programa.zip. Ahora vamos a preparar la web.
Necesitaremos un canvas en el que se ejecutará el emulador de MS-DOS, para referenciarlo vamos a usar el id «jsdos». Para fijar de el tamaño del canvas usaremos CSS.
Su funcionamiento es sencillo y se puede entender sin demasiadas explicaciones, algunos puntos que se necesitan aclarar:
fs.extract(«programa.zip») descomprime el fichero zip en el directorio raiz C:
main([«-c», «programa.exe»]) el primer comando va a C: y el segundo ejecuta programa.exe
window.ci = ci; Permite acceder a la API de DosCommandInterface desde cualquier parte de la web.
autolock: true Sirve para capturar el ratón automáticamente cuando se hace click sobre el canvas. Si tu aplicación no usa el ratón para nada puedes prescindir de ponerlo.
Algunas funciones interesantes
Entra y salir de modo pantalla completa ci.fullscreen(), ci.exitFullscreen()
Realiza una captura de pantalla ci.screenshot()
Simular pulsacioenes de teclas ci.simulateKeyPress(keyCode), ci.simulateKeyEvent(keyCode, pressed)
Ejecutar comandos ci.shell([cmd1, cmd2, …])
Problemas
Aquí recopilo un listado de cosas que me han dado problemas:
Resoluciones raras de pantalla. Forzar la aplicación en formatos que distorsionan mucho el formato 4:3 habitual de los monitores de esa época
El sonido no siempre va tan bien como sería deseable
El ratón, muchas aplicaciones de MS-DOS usan falsos ratones, imágenes que superponen donde debería estar el ratón. Algunos dan problemas.
El uso desde el móvil no está resuelto, aunque no es algo fácil de solucionar. El punto bueno es que te dan la herramientas básicas para que trates de resolverlo.
Ideas interesantes
Algunas ideas interesantes que se me ocurrieron pero no he tenido oportunidad o tiempo de intentaras.
Aunque JS-DOS ofrece alguna formas de ejecutar múltiples comandos hay soluciones como los ficheros de procesamiento por lotes .bat
Se pueden asociar comandos de MS-DOS, pulsaciones de teclas o del ratón a acciones en la web esto puede dar lugar a interesantes formas de interactuar con la aplicación (incluso de hacerla más accesible)
Un gamepad virtual sobre el canvas donde se ejecuta la aplicación. Para usar juegos desde el móvil es imprescindible
Usando Apache Cordoba o PhoneGap se podría convertir la web en una aplicación móvil. Aunque no sé si tiene utilidad más allá de entretenerse un rato probando
Lo mismo que el punto anterior pero en el escritorio con electron
Decidir si dos colores se parecen puede parecer sencillo, basta con medir la distancia entre ambos. En formato RGB la distancia entre dos colores es:
SQRT((R1-R2)^2 + (G1-G2)^2 + (B1-B2)^2)
Desgraciadamente no funciona demasiado bien en el espacio de color RGB, que es el que se usa habitualmente en los ordenadores , por lo que tenemos que usar otro espacio. Tenemos varias alternativas las más prometedoras son:
Vamos a apostar por el último que suele ser el que mejor funciona. Esta ideado para representar el espacio de color de forma próxima a como el ojo humano los percibe.
El primer problema es que no hay una conversión directa RGB a Lab. La solución es pasar de RGB a XYZ y luego de XYZ a Lab. En esas conversiones se pierde algo de precisión pero el resultado es lo suficientemente exacto.
Debajo está el código en JavaScript para realizar la conversión de RGB a LAB
function RGBtoLAB(r,g,b){
//RGBtoXYZ
var x = RGBtoXYZ_RtoX[r] + RGBtoXYZ_GtoX[g] + RGBtoXYZ_BtoX[b];
var y = RGBtoXYZ_RtoY[r] + RGBtoXYZ_GtoY[g] + RGBtoXYZ_BtoY[b];
var z = RGBtoXYZ_RtoZ[r] + RGBtoXYZ_GtoZ[g] + RGBtoXYZ_BtoZ[b];
if (x > 0.008856)
x = Math.cbrt(x);
else
x = (7.787 * x) + 0.13793103448275862;
if (y > 0.008856)
y = Math.cbrt(y);
else
y = (7.787 * y) + 0.13793103448275862;
if (z > 0.008856)
z = Math.cbrt(z);
else
z = (7.787 * z) + 0.13793103448275862;
L = (116 * y) - 16;
a = 500 * (x - y);
b = 200 * (y - z);
return [L,a,b];
}
RGBtoXYZ_RtoX = [];
RGBtoXYZ_GtoX = [];
RGBtoXYZ_BtoX = [];
RGBtoXYZ_RtoY = [];
RGBtoXYZ_GtoY = [];
RGBtoXYZ_BtoY = [];
RGBtoXYZ_RtoZ = [];
RGBtoXYZ_GtoZ = [];
RGBtoXYZ_BtoZ = [];
for(var i = 0; i < 256; i++){ //i from 0 to 255
r = parseFloat(i/255) ; //r from 0 to 1
if (r > 0.04045 )
r = Math.pow((r+0.055)/1.055 , 2.4);
else
r = r/12.92;
r = r * 100
var ref_X = 95.047;
var ref_Y = 100.000;
var ref_Z = 108.883;
RGBtoXYZ_RtoX[i] = r * 0.4124/ref_X;
RGBtoXYZ_GtoX[i] = r * 0.3576/ref_X;
RGBtoXYZ_BtoX[i] = r * 0.1805/ref_X;
RGBtoXYZ_RtoY[i] = r * 0.2126/ref_Y;
RGBtoXYZ_GtoY[i] = r * 0.7152/ref_Y;
RGBtoXYZ_BtoY[i] = r * 0.0722/ref_Y;
RGBtoXYZ_RtoZ[i] = r * 0.0193/ref_Z;
RGBtoXYZ_GtoZ[i] = r * 0.1192/ref_Z;
RGBtoXYZ_BtoZ[i] = r * 0.9505/ref_Z;
}
En el código se usan algunas optimizaciones como usar tablas de consulta para acelerar los cálculos (RGBtoXYX_*).
Los nuevos valores obtenidos ya se pueden comparar usando la distancia euclídea.
SQRT((L1-L2)^2 + (a1-a2)^2 + (b1-b2)^2)
El resultado indica la proximidad entre dos colores, lo parecidos que son. Como referencia un resultado menor de 4 quiere decir que la diferencia entre colores apenas es perceptible a simple vista. Eso no quiere decir que este valor solo se pueda usar para saber si dos colores son iguales, también para agrupar colores similares, encontrar un color en una imagen pese a variaciones de la iluminación (buscando el color más parecido) ,…
Veamos un ejemplo, unos de los puntos débiles más fáciles de ver del espacio de color RGB son los grises. Comparamos el gris medio (128,128,128) con otros dos colores: gris oscuro (28,28,28) y dorado oscuro (128,128,0). Veamos cual de los dos sistemas es más exacto.
RGB
Lab
Gris oscuro
173,20
43,31
Dorado Oscuro
128
58,16
Distancias según el espacio de color que se use
Usando RGB el dorado oscuro está más cerca del gris medio que el gris oscuro, mientras que Lab da el resultado correcto.
Hablar de la privacidad de los datos como algo completamente seguro y cierto es una pequeña mentira que suelen hacer las empresas que viven de ellos. Si un dato está guardado su privacidad puede ser puesta en duda.
Envío de los datos
El primer problema es que hay que mandar los datos. Un dispositivo genera/captura el dato y debe de enviarlo a través de una red de comunicaciones hasta un dispositivo destinatario que lo almacenará. Vamos por partes:
El dispositivo origen es el primer punto débil de la cadena. Si es inseguro o está mal configurado puede filtrar los datos a un tercero y por mucho que te esfuerces en mantener seguro tu móvil o tu ordenador no basta. Muchas veces el dispositivo que envía los datos sobre ti es otro. Una estación de telefonía que envía que tu móvil está conectado a ella, un dispositivo domótico, un electrodoméstico inteligente o un caja de supermercado.
El segundo punto de ataque es el canal de comunicaciones. Todos estamos advertidos de lo inseguro que es conectarse a redes públicas, pero también las privadas pueden estar vulneradas. El router de tu casa quizás tenga una vulnerabilidad sin parchear que algún gusano en Internet ha aprovechado para infectarlo.
Lo mismo pasa con el destino. No sólo hay que fiarse de que el receptor hace un uso correcto de los datos. Sino que seguramente ha subcontratado parte de su infraestructura (bases de datos, servidores, conversión de voz a texto, reconocimiento de imágenes, estadísticas,….) a otras empresas en las que también tienes que confiar. Y no solo es que ellos no «roben» tus datos es que sean seguros y no permitan que un tercero roben esos datos.
El gobierno siempre puede pedir tus datos
Ahora bien aunque no haya ningún problema y los datos lleguen seguros y sean almacenados de forma segura. Si el gobierno los pide las empresas están obligadas a dárselos. Y no basta con el típico: «no hagas nada para que el gobierno no te investigue». Los gobiernos piden los datos basándose en sospechas. Quizás mañana un algoritmo diga que eres sospechoso y pidan tus datos para verificarlo. ¿Qué ocurre luego con esos datos? ¿Se quedan guardados mientras pasa el tiempo y los gobiernos? Los gobiernos a su vez subcontratan las herramientas e infraestructuras a otras empresas y otra vez dependemos la cadena de confianza. ¿Esas empresas respetan la privacidad de nuestros datos? ¿Son seguras?.
Leyes y empresas que cambian
Ahora mismo muchas empresas prometen privacidad. Pero quién sabe si seguirán prometiendola dentro de 20 años. Puede que hayan sido comprada por otra empresa con menos escrúpulos. Que las leyes hayan cambiado. Incluso que el procesado de datos haya alcanzado niveles tales que puedan extraer información de esos datos que no quieres que sepan.
Datos cifrados
Que los datos estén cifrados ofrece cierta protección contra el robo de estos por terceros, pero no para evitar la explotación fraudulenta de los mismos por el receptor.
Al final los datos cifrados no sirven de nada y cuando se procesan tienen que estar descifrados. Durante todo ese procesado son vulnerables.
Por ejemplo si la aplicación de domótica de mi móvil permite controlar con voz las luces de casa pero ellos no han construido una librería de conversión de voz a texto ni una de procesamiento de lenguaje natural, son servicios que contratan a otras dos empresas que a su vez se guardan los datos para mejorar su sistema o para sacar estadísticas. El intercambio entre empresas es cifrado pero una de ellas no guarda los datos cifrados o lo hace pero no ha contratado a un experto y comete errores que permite su descifrado a un tercero que ha burlado sus sistemas y ha robado sus datos.
Cruzar y desanonimizar datos
Una medida muy importante es que los datos estén anonimizados. Es decir que se hayan eliminado los datos que puedan identificar a la persona que generó esos datos. El problema es que según crece la cantidad de datos más difícil es que sigan siendo anónimos.
También cabe la posibilidad de que cruzando datos anonimizados de diferentes fuentes se puedan desanonimizar. Quizas una empresa compra otras dos lo que le permite cruzar sus datos. O se filtren datos de distintas fuentes que cruzando los permita desanonimizarlos.
Exigir el borrado de datos
Gracias a leyes como la nueva normativa europea de protección de datos el usuario puede exigir que eliminen los datos que una empresa tenga de él.
Para empezar no se borran todos los datos ya que muchos se tienen que mantener por ley al menos un tiempo. Por ejemplo los datos de pagos.
Segundo en algunas arquitecturas, en las que los datos se distribuyen en varias copias en diferentes sistemas y servicios, es difícil borrar un dato. Es fácil marcar que ese dato está borrado pero su eliminación física puede ser complicada.
Tercero hay muchos procesos internos que generan copias de los datos. Por ejemplo las copias de seguridad. Es difícil que tus datos sean borrados de todas las copias de seguridad. Si bien lo habitual es sobreescribirlas cada cierto tiempo.
Por último esto solo sirve con empresas que cumplen la ley y es fácil parecer que la cumples sin cumplirla. Tampoco es que sirva con quienes roban los datos.
Metadatos
Si estás preocupado por la privacidad no sólo son importantes los propios dato también los metadatos. Los metadatos son datos sobre los datos que son necesarios generar para que muchos procesos automáticos funcionen. Por ejemplo cuando entras a una web no solo estás enviando la dirección web, también tu IP, tu navegador, tu sistema operativo y alguna cosa más. Con estos datos se pueden deducir a su vez más cosas. Por ejemplo con la IP se puede aproximar tu localización geográfica.
No solo hay metadatos en las conexiones a Internet. Hay metadatos en todas partes. En los ficheros, fotografía, música, antenas de telefonía móvil para tener cobertura….
El problema es que ni siquiera somos conscientes de estos metadatos. Si nos conectamos a una web en Internet se generan gran cantidad de metadatos para que los paquetes lleguen de nuestro PC al servidor de la web. Y carecemos de control sobre ellos.
Los datos son para toda la vida
Los datos pueden ser almacenados durante décadas. Sobrevivir a cambios de servidores, soportes físicos, tecnologías, empresas, gobiernos y leyes. Tus datos pueden sobrevivirte. Y pocas veces pensamos en que será de nuestros datos a largo plazo. Vamos a ver algunas posibilidades.
Basta con que en alguno momento un fallo de seguridad o un error conprometa la privacidad de tus datos para que pierdas el control de ellos para siempre. No sabrás cuántas copias hay ni quién tiene una.
Con el paso de los años los avances en big data pueden permitir que los datos que cedistes hace años revelen aspectos tuyos que prefieras que no se supieran.
Las leyes pueden exigir que se tomen ciertas medidas que los datos anteriores a esas leyes no cumplen. Lo cual te dejará expuesto ante quien tenga esos datos tuyos.
Un caso de ejemplo
En 2018 se filtraron los datos de una famosa empresa de pulseras deportivas. No estoy seguro si esos datos se enviaban al servidor cifrados y completamente anonimizados pero para el caso vamos a suponer que sí. Los datos filtrados eran las posiciones GPS de las distintas pulseras a lo largo del día.
Al contar con semejante cantidad de datos varios expertos en seguridad los usaron para ver que eran capaz de sacar de ellos. Uno de los casos más espectaculares fue que lograron encontrar varias bases militares secretas.
Obviamente no sabían cuales de esos datos eran de militares estadounidenses. Pero si ves una concentración de pulseras deportivas en un punto del desierto donde no debería haber nada no es difícil llegar a la conclusión de que ahí hay algo. Es más como los daos incluían la posición GPS se puede «dibujar» una nube de puntos que muestra la forma de la base con bastante exactitud. Estoy seguro de que de esos datos se pueden concluir más cosas: una extimación de cuantos hombres hay, teniendo en cuenta la hora saber donde están los comedores o los dormitorios, turnos, descansos,…
Es un ejemplo de como con datos enviados de forma segura y anonimizados se puede poner en peligro algo más que la privacidad de una persona. Y no es que la empresa tuviera malas intenciones, pero cometió un error de seguridad y los datos se filtraron. Al final todo dato almacenado corre el riesgo de volverse en tu contra.
Vamos a ver cómo crear una máquina de estados finitos muy sencilla para Arduino o Node MCU. Debido a las limitaciones de ambas plataformas vamos a ver una idea muy sencilla.
Empezaremos por aclarar los conceptos básicos:
Estados: son los distintos valores que puede tomar la máquina de estados finitos.
Eventos: producen el cambio de un estado a otro.
Transiciones: definen como los eventos cambian los estados. Cada transición constan de tres elementos, un evento, un estado origen y un estado destino. Indica que cuando se produzca el evento si el estado actual es el estado origen este cambiará por el estado destino.
Una mef (máquina de estados finitos) está siempre en un único estado y hay eventos que producen el cambio de estado siguiendo unas reglas (las transiciones). Aunque con esto ya tenemos una mef, para que sea realmente útil tiene que facilitar la ejecución de funciones asociada a los distintos estados y eventos.
Para facilitar todo esto podemos usar la librería easy finite state machine que simplifica la programación usando macros del preprocesador.
Estados y eventos
Vamos a empezar por los eventos y estados, para ello podemos usar enum de C que nos permite escribir código de forma muy intuitiva.
STATES {start, step1, step2, finish};
EVENTS {next, back};
También habrá que definir una variable que guarde el estado actual e inicializarla con el estado inicial.
enum States efsmState = start
Con la librería:
INIT(start)
Cambiar el valor del estado es muy sencillo, basta con hacer:
efsmState = start
O con las macros:
changeState(start)
Así como comparar el valor del estado:
isState(start)
Transiciones:
De todas formas lo habitual no es realizar los cambios de estados directamente sino a través de eventos. Los eventos vamos a gestionarlos con la función efsmEvent(event) que los aglutina todos. Esta función recibe el evento como parámetro y contiene las transiciones. Básicamente son un montón de «if». Usando la librería se usa la macro TRANSITION
Su significado es: Si se lanza el evento y el estado es el estadoOrigen se pasa al estadoDestino y se llama a función. No es necesario poner una función asociada, se puede dejar en blanco.
Las transiciones se definen entre las macros:
START_TRANSITIONS y END_TRANSITIONS
Las transicione son una gran ayuda, aunque su funcionamiento se puede sustituir con isState(state) y changeState(state).
Cuando se ejecuta efsmExecute() verifica y llama a la función asociada a cada estados. Es decir, cuando se llama a esta función se verifica en qué estado está la máquina y llama a la función asociada a ese estado. Con la forma que tiene Arduino de funcionar usando una función loop que está en bucle constante la idea es colocar efsmExecute() en la función loop() para que se llame en cada iteración.
EXECUTION(executionState,function())
Si no se asocia ninguna función a un estado no se ejecutará nada.
Se definen entre las macros:
START_EXECUTIONS y END_EXECUTIONS
No es obligatorio definirlas. Por ejemlo cuando la mef solo tenga que lanzar funciones en los cambios de estado (transiciones).
Disparadores:
Los disparadores generan eventos asociados a distintos sucesos. Su idea es facilitar la programación de acciones habituales que lanzan eventos. Se ejecutan cuando se llama a la función efsmTriggers().
Para que un disparador se lance, el estado de la mef ha de ser el mismo que el que se le pasa como primer parámetro. Hay de tres tipos de disparadores:
Un condicional lanza un evento si el condicional especificado se cumple:
CONDITIONAL(state, condition, event)
Un contador lanza un evento después de haber llamado un número determinado de veces a la función efsmTriggers() tras al último evento válido.
COUNTER(state, number, event)
Un temporizador lanza un evento cuando ha pasado un determinado tiempo (en milisegundos) desde que se lanzó el último evento válido.
TIMER(state, number, event)
«Tras el último evento válido’ significa que cada vez que se lanza un evento y este produce una transición los contadores se reinician. Si se quisieran reiniciar a mano se pueden usar: resetTimer() y resetCounter()
Los disparadores se definen entre las macros:
START_TRIGGERS y END_TRIGGERS
No es necesario definir disparadores , si se quiere lanzar algún evento manualmente se puede hacer llamando directamente a efsmEvent(event).
En resumen:
Se definen estados y eventos.
Se establece el estado inicial.
Se crean transiciones que indican que cambios entre estados se producen con cada evento asi como la función que se lanzara cuando se produzca esa transición.
Se escriben la ejecuciones indicando que función se lanzará cuando la máquina este en cada estado.
Se declaran los disparadores que lanzaran eventos (o se programa el lanzamiento a mano).
Se añade a la función loop efsmExecute() y efsmTriggers()
Un ejemplo:
Para ver todo un poco más claro vamos a ver un ejemplo basado en el que incluye la librería. En el se modela la máquina de estados finitos representada en el siguiente diagrama:
Máquina de estados finitos del ejemplo
El código es el siguiente:
#include <efsm.h>
STATES {start, step1, step2, finish};
EVENTS {next, back};
INIT(start)
START_TRANSITIONS
TRANSITION(next,start,step1,Serial.println("next")) //next start -> step1
TRANSITION(next,step1,step2,Serial.println("next")) //next step1 -> step2
TRANSITION(next,step2,finish,Serial.println("next")) //next step2 -> finish
TRANSITION(back,step2,step1,Serial.println("back")) //back step2 -> step1
TRANSITION(ANY_EVENT,ANY_STATE,ANY_STATE,Serial.println("FAIL!!!")) //in any other case
END_TRANSITIONS
START_EXECUTIONS
EXECUTION(start,Serial.println("start")) //state is start
EXECUTION(step1,Serial.println("step1")) //state is step1
EXECUTION(step2,Serial.println("step2")) //state is step2
EXECUTION(finish,Serial.println("finish")) //state is finish
END_EXECUTIONS
START_TRIGGERS
COUNTER(start,5,next); //State start wait 5 iterations and launch event next
TIMER(step1,2000,next); //State step1 wait 2 sg and launch event next
END_TRIGGERS
void setup() {
Serial.begin(9600);
resetTimer();
resetCounter();
}
void loop() {
efsmExecute();
if(isState(step2)){
efsmEvent(next);
}
efsmTriggers();
delay(1000);
}
Este texto mejorado y ampliado forma parte de mi libro sobre como mejorar tus programas en Arduino. Puedes echarle un vistazo aquí.
Puedes ver un vídeo sobre el tema en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube