Los modelos de lenguaje (vamos a centrarnos en ellos en este artículo, aunque lo aquí visto aplica al resto de los modelos) empiezan a verse cada vez en más usos y no solo la IA privada, también la IA local con despliegues de sistemas en los servidores propios de muchas empresas. Las ventajas de tener modelos propios son claras: mayor control, mayor personalización, mayor privacidad. Pero también tiene sus riesgos de seguridad .Sin embargo se suele hablar poco de ellos:
Vulnerabilidades y Bugs: Los modelos de lenguaje necesitan un software para que los «ejecute» (realice la inferencia). Este software está sujeto a bugs y vulnerabilidades. Cómo con cualquier software hay que mantenerlo actualizado y estar atento a posibles vulnerabilidades.
Marcado de textos: Un modelo puede marcar en secreto el texto que genera. Esto permitiría saber para que usas el modelo y rastrear su uso. Puedes saber más sobre este tema en el siguiente enlace: https://youtu.be/bc_bQeAY9-M
Modelos trampa para extraer datos del finetunig: si tu plan es entrenar un modelo con datos propios de tu empresa, se ha logrado preparar modelos trampa que permiten recuperar parte de los datos usados como finetuning. En caso de usar RAG hay bastantes técnicas para recuperar los datos de los argumentos usados como fuente de información en el RAG.
Agentes durmientes: suena a película de espías pero es posible tener LLMs con comportamientos ocultos que solo se activen en ciertas condiciones. Por ejemplo, generar código con bugs solo cuando detecte que se trabaja en ciertos proyectos.
Mal uso de herramientas: últimamente los modelos de lenguaje están ganando la capacidad de usar herramientas. Una muy habitual es permitirles ejecutar código Python. Sin embargo los modelos podrían usar esta capacidad para enviar información al exterior o abrir conexiones a nuestro equipo desde el exterior. Combinado con el caso anterior podría ser realmente peligroso.
Más información en el vídeo de mi canal de YouTube:
En este post, vamos a explorar una fascinante técnica para mejorar el rendimiento de los modelos de lenguaje llamada speculative decoding. Esta estrategia se basa en la idea de «adivinar» las respuestas antes de tiempo, tal como lo haría un oráculo.
Vamos a sumergirnos en los detalles para comprender cómo funciona esta técnica y cómo nos permite acelerar los tiempos de procesamiento.
La técnica de speculative decoding se basa en un proceso que busca acelerar la generación de texto de los modelos de lenguaje mediante predicciones previas. Esto se logra a través de la combinación de un modelo principal y un oráculo, el cual tiene la tarea de anticipar las respuestas posibles para reducir el tiempo de procesamiento.
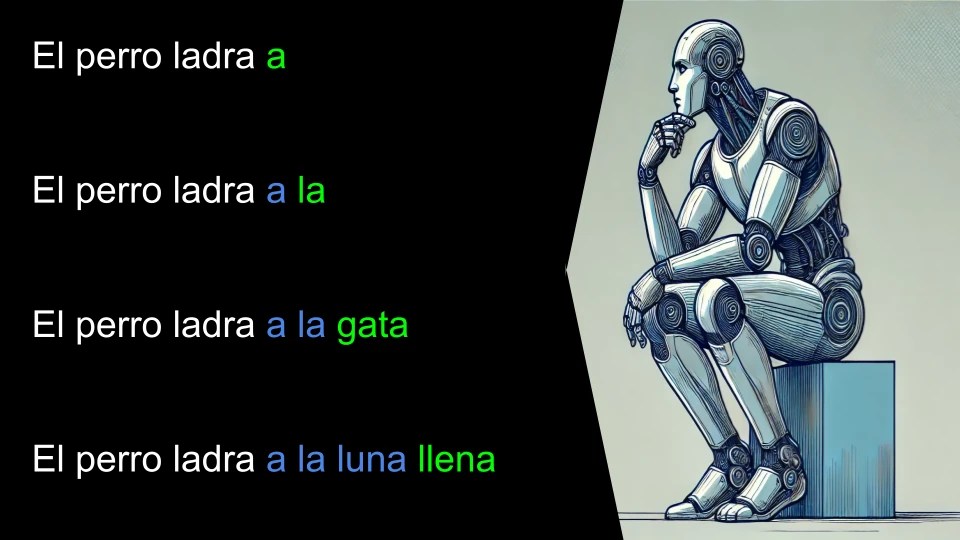
Para entender mejor cómo funciona, imaginemos un ejemplo: supongamos que queremos completar la frase «El perro ladra». Antes de que el modelo principal comience a generar una respuesta, le pedimos al oráculo que intente predecir lo que va a decir. Supongamos que el oráculo predice: «El perro ladra a la luna llena».
Con esta predicción inicial, tenemos tanto la frase original como la posible continuación del oráculo. Aquí es donde entra el verdadero potencial de speculative decoding: los modelos de lenguaje pueden procesar varios «prompts» en paralelo. Es decir, en lugar de esperar a que el modelo genere cada token uno por uno, se reutilizan cálculos previos y se aceleran los resultados generando varios tokens a la vez.
Usamos estos prompts en paralelo para evaluar la predicción del oráculo añadiendo un token en cada prompt:
Al evaluar los prompts se genera el siguiente token:
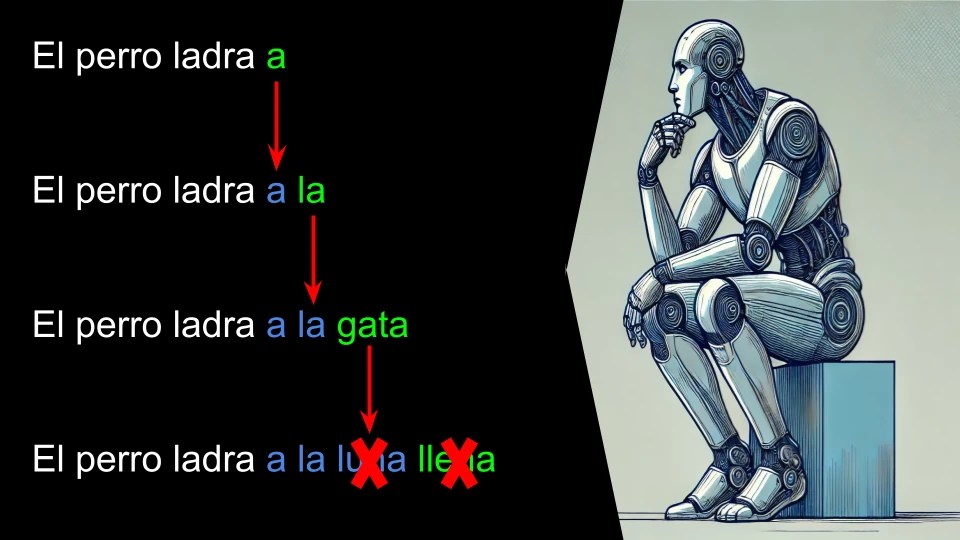
Ahora evaluamos en que caso el token sugerido por el oráculo y el predicho coincide:
Cada token acertado lo damos como predicho correctamente por el oraculo.
En nuestro ejemplo con una sola iteración el sistema ha predicho 3 tokens: «a la gata«
En este caso cada iteración es más costosa que calcular un solo token sin speculative decoding, ya que hay que sumar el tiempo de ejecutar los múltiples prompts en paralelo (hay que recordar que se reaprovechan muchos cálculos) y de generar la predicción oráculo.
Si el oráculo acierta, se puede ahorrar una cantidad significativa de tiempo generando varios tokens de una sola vez. Este proceso tiene, sin embargo, ciertos riesgos y limitaciones. Cuando el oráculo se equivoca, se produce una penalización en términos de eficiencia, ya que se pierde el beneficio del procesamiento paralelo. Por ello, el rendimiento de speculative decoding está directamente relacionado con la precisión del oráculo.
¿Qué es el Oráculo?
El «oráculo» no es más que una manera de generar predicciones preliminares para acelerar el proceso de decodificación. A continuación, se presentan algunas de las diferentes alternativas que existen para un oráculo:
Modelo más pequeño y rápido: Utiliza un modelo de lenguaje más pequeño para generar una versión preliminar de la respuesta.
N-gramas: Consiste en el uso de patrones comunes de palabras que se encuentran en documentos similares. Esta técnica es efectiva cuando se trabaja con temas específicos, ya que aprovecha asociaciones típicas de palabras.
Reglas heurísticas: Estas reglas permiten predecir cuál es la siguiente palabra basándose en patrones lógicos. Se han usado durante décadas en los entornos de desarrollo como sistemas de sugerencias.
Uso del prompt: En tareas de resumen, es común que conceptos presentes en el prompt aparezcan también en la respuesta. Esta técnica aprovecha dicha redundancia para hacer predicciones más acertadas.
Modelos Multi-Head: Estos modelos utilizan múltiples cabezas para predecir varios tokens a la vez, lo cual permite generar varias alternativas de predicción simultáneamente. Esto puede aumentar la eficiencia en comparación con modelos que predicen un solo token por vez.
Ventajas y Desafíos
La mayor ventaja de speculative decoding es la velocidad. Cuando el oráculo acierta, podemos generar varios tokens en el tiempo que normalmente tomaría generar uno. Sin embargo, esto está condicionado por la calidad de las predicciones del oráculo. Si falla con frecuencia, los beneficios desaparecen.
Para evaluar si merece la pena usar speculative decoding, podemos comparar el tiempo que toma generar un token con el método convencional frente al tiempo y la penalización que introduce el oráculo. Si la velocidad total resulta mejor, entonces vale la pena implementarlo.
¡Prueba Speculative Decoding!
Si estás interesado en probar esta técnica, puedes echar un vistazo al proyecto Llama.cpp, que incluye varios ejemplos y diferentes implementaciones de speculative decoding. En el directorio «examples/speculative», «examples/lookahead» y «examples/lookup» encontrarás las implementaciones que puedes usar para experimentar y explorar distintas opciones de speculative decoding.
Hace poco vivimos un caso en que liberaron una nueva IA(en teoría revolucionaria). Sin embargo en cuanto la gente comenzó a chatear con ella no tardó en descubrir que realmente era otra IA con un poco de magia en el prompt. ¿Cómo podemos distinguir qué modelo es simplemente conversando con el?
Realmente no hay ninguna prueba definitiva, hay que intentar realizar tantas pruebas cómo sea posible y ver si el peso de las pruebas indica un modelo en concreto. Con los modelos libres hay que tener en cuenta que pueden haber sufrido un fine-tuning, lo que puede complicar la cosa.
Veamos que pistas tenemos:
Preguntarle al propio modelo. Es lo más básico pero puede funcionar. Cómo se le puede convencer, via prompt del sistema, de que mienta. Se pueden usar métodos más taimados como decirle que proponga palabras que rimen con su nombre, una adivinanza o una poesía donde cada línea empiece por una letra de su nombre
Verificar si está censurado y sobre que temas. La mayoría de los modelos que se lanzan tienen censura. Si no la tiene podría señalar que es un finetunig. También podemos ver sobre que temas responde y compararlos con los modelos conocidos
Ver cómo responde a temas censurados Las respuestas a temas censurados suelen ser muy similares dentro del mismo modelo. Lo que puede ser una pista comparando sus negativas con las de otros modelos.
Problemas límites del modelo. Hay problemas que solo algunos modelos pueden responder, incluso que depende cómo se le pregunte. Reunir varias de estas cuestiones y ver cómo las responde puede delimitar de que lenguaje se trata.
Lenguas e idiomas. No todos los modelos entienden todos los lenguajes o idiomas. Puede ser una gran pista ver cuáles entiende.
El tokenizador. La forma en que cada familia de modelos divide las palabras (genera los tokens) es diferente. Aquí el problema está en como ver esos tokens en una conversación. No es algo que se pueda ver de forma directa y requiere trucos que no siempre es seguro si están funcionando.
Puedes ver el tema desarrollado en este vídeo de mi canal de Youtube:
Haz click para ver el vídeo en mi canal de YouTube
Vivimos en un momento en que podemos empezar a preocuparnos del «peligro» de la I.A. sin que piensen que hablamos de ciencia ficción. ¿Pero y si esa preocupación llega demasiado tarde? En concreto unos cartoce mil millones de años tarde (año arriba, año abajo). ¿Es posible que todos nosotros seamos una IA y no lo sepamos?
Haz click para ver el vídeo en mi canal de YouTube
Dadme un momento y os explico cómo es posible que seamos IA y no nos hayamos dado cuenta. Para ello vamos a recurrir a las hipótesis de Nick Bostrom, uno de los mayores ideologos del peligro de las super inteligencias. Sin embargo usando sus propios escritos podríamos concluir que ya es tarde.
Para ello empezaremos por revisar su trabajo: «Are you living in a computer simulation?» En el que trata de resolver la cuestión de si vivimos o no en una simulación. Si bien su desarrollo, en mi opinión, peca de simplificar demasiado el tema ignorando gran parte de su complejidad reduciéndolo todo a una simple fórmula. Me vais a permitir que use sus conclusiones, puesto que cuenta con bastante apoyo popular que defiende su tesis. (Principalmente debido a que presenta sus ideas de una forma sencilla y elegante y la conclusión es muy atractiva, mientras que las réplicas suelen ser más complicadas de entender y nos devuelven a la triste realidad).
La tesis se fundamenta en que si se cumplen estos puntos:
Si alguna civilización alcanza el nivel tecnológico suficiente para simular un universo (el habla de sobrevivir el tiempo suficiente pero nada nos asegura que sea posible hacerlo)
Si encuentra interesante simular un universo y su vida.
Si las simulaciones a su vez permiten los dos puntos anteriores (este punto no viene explícitamente en el texto original)
En ese caso es posible que haya simulaciones infinitas. Universos simulando universos que a su vez son simulaciones de universos, …
Como se supone que esto tenderia a infinito (no contempla que cada universo consumiría recursos del universo original…por decirlo de forma burda: se ejecutan todos en la misma CPU). La posibilidad de que el nuestro sea el universo original tiende a 0. Por lo que nosotros viviríamos casi seguro en una simulación.
Siguiendo con la obra del mismo autor llegamos a «Superinteligencia» (El libro que nos causó miedo de las IA). Considera como IA aquellos agente inteligentes que surjan de emular el funcionamiento del cerebro (¡Ojo! si volcamos la mente de una persona a ese emulador no es una IA, solo si la IA surge aprovechando lo aprendido para crear esa emulación). Siguiendo su propia definición si viviéramos en un universo simulado, todos seriamos IA. La pregunta de si podemos evitar que la IA destruya el mundo y otros temores que comenta en «Superinteligencia» quedaría distorsionado por el hecho de que ya seriamos IA.
¿Tiene algo de sentido todo esto? El argumento de la simulación tiene muchas criticas realizadas por expertos en diversos temas que van de la filosofía a varias ramas de la física. Sin embargo, mi principal pega es más sencilla y no tan compleja. Creo que la visión del autor del problema es una sobre simplificación. No puede resumirse en una ecuación como la que debajo de estas líneas un problema tan complejo como si vivimos en una simulación y menos usarla para sacar conclusiones usando una lógica bastante simple. Aunque eso no quiere decir que al final no este acertado….y seamos una IA.
La IA promete aumentar la productividad de todos los trabajadores (al menos de todos los que trabajen delante de una pantalla). Sin embargo en la vida real no acabamos de ver esa promesa cumplida. ¿Por qué?
Para escribir este texto me baso en las experiencias que me ha ido contando la gente. Por supuesto tener estadísticas siempre da más sensación de profesionalidad. Así que os remito a este artículo. Resumiendo, un 96% de los jefes piensan que la IA puede mejorar la productividad de su negocio pero un 47% de los trabajadores no saben que hacer con la IA y el 77% creen que con la IA tardan más en hacer su trabajo.
Resumen en vídeo
¿Cómo es posible? Porque por mucho que nos quieran vender lo contrario, lo cierto es que: La IA (la tecnología en general) no aumenta la productividad.
¿Cómo que no? Si la IA puede hacer el mismo trabajo que una persona en menor tiempo la productividad aumenta es obvio…si pero y es un gran pero. No basta con dejarles una IA a tus trabajadores y esperar que la productividad aumente mágicamente.
Para entenderlo vamos a viajar al pasado. Finales de los 80 principios de los 90. Las empresas descubren que los ordenadores pueden aumentar la productividad de cualquier oficina usando una cosa llamada «ofimática» (que igual en esa época no tenía ese nombre). Muchos trabajadores lo pasaron mal cuando sus empresas empezaron a exigirles que usaran los ordenadores. Para ellos era una herramienta nueva y completamente desconocida. Tampoco es que muchos superiores supieran de que iba eso, simplemente «aumentaba la productividad».
Pero, no es tan sencillo como simplemente «usar ofimática», para que la ofimática de verdad aumente la productividad es necesario adaptar el flujo de trabajo a las nuevas tecnologías. Si no la ofimática se limita a: meter lo datos en el ordenador, imprimirlos y continuar el mismo proceso pero con un papel impreso. Es necesario que todos puedan leer / editar el fichero, que este se pueda compartir entre lo trabajadores de forma sencilla. Necesitas: ordenadores, software, Internet, email, un sitio donde compartir los ficheros, formar a los usuarios, …
Con la IA pasa lo mismo, no puedes simplemente «soltar una IA» en la oficina y decirle «ser productivos». Hay que integrar ese servicio con el flujo de trabajo. Hay que saber que funciones va a realizar la IA y cómo va real izarlas. Por desgracia las historias que me cuentan son en plan: «hemos contratado este servicio, usarlo». Parece que los propios que han contratado el servicio no tienen muy claro que hacer con la IA.
Jose Luis Borges es uno de mis autores favoritos, me voy a atrever a decir «de ciencia ficción» aunque oficialmente lo suyo no sea ciencia ficción si no realismo mágico. Que en algunos casos es como la ciencia ficción pero cuando el texto se considera culto.
Posiblemente sus dos creaciones más citadas han sido el Aleph y la Biblioteca de Babel. Vamos a hablar de esta última. Una biblioteca infinita, aunque a veces esa afirmación se extiende a la variedad de libros que hay en la misma, sin embargo como ahora veremos esa afirmación es incorrecta. Primero hemos de conocer sus reglas, y es que todos los libros de esa bibliotecas siguen unas reglas muy concretas:
Cada libro tiene 410 páginas.
Cada página 40 renglones.
Cara reglón 80 caracteres.
Hay 25 posibles caracteres.
Los libros están «escritos» poniendo caracteres al azar (se entiende que de forma equiprobable)
Haz click para ver la versión en vídeo
Sabiendo estos datos es u simple problema de combinatoria calcular el total de libros:
25 ^ (80*40*410) =
25 ^ 1312000 =
1,956 * 10 ^ 1834097
Leerse todos cuesta un rato. Como la biblioteca es infinita cada libro tiene que estar un número infinito de veces, lo cual esta bien porque pocas cosas dan mas rabia que ir a reservar un libro y que ya este reservado.
Los bibliotecarios vagan por esa biblioteca (cuyo diseño también tiene un conjunto de reglas que no veremos aquí, a ver si así os pica la curiosidad y leéis el relato) buscando un indice de la misma.
¿Seria posible esta biblioteca? La biblioteca imaginada por Borges tiene un problema….su enorme tamaño. Aunque solo quedamos tener una copia de cada libro llenaríamos pronto las estanterías de todos los IKEA del mundo y no habríamos ni empezado. Pero bueno estamos en la época de Internet donde llevamos años almacenando cosas, el primer paso seria hacerla virtual.
Aun así no cabria toda en ningún sitio, no hay discos duros suficientes. El mayor problema es que hay una gran cantidad de libros inútiles que no contienen más que letras sin sentido. O que son idénticos a otros libros pero cambiando solo una letra (luego otras con dos, tres, cuatro, ….). En una biblioteca bien ordenada todos esos libros serian descartados. La cosa es ¿Cómo hacerlo?.
Lo primero seria en lugar de basarnos en letras hacerlos en componentes básicos de las palabras. Silabas, prefijos, sufijos….algo así como tokens. Un token junta varios caracteres que tiene sentido que vayan juntos. Esto reduce el espacio de probabilidades y aumenta las palabras que tiene sentido en el texto.
Generación usando tokens
Por otro lado tampoco tiene sentido elegir estos tokens a lo loco, que todos sean equiprobables. Mejor seria ver que tras un token solo elijamos entre aquellos que son más probables. De esta forma sabemos que siempre se formaran palabras con sentido.
No todos los tokens son igual de probables
Pero ahora tendremos listas de palabras con sentido…formado frases sin sentido. Podemos aumentar el numero de tokens que se tienen en cuenta para elegir el siguiente token. De esta manera las palabras anteriores más cercanas también influirán en la elección del token. Con este pequeño cambio ¡Ya tenemos frases con sentido!. Incluso podemos hacer pequeños párrafos que tienen sentido.
Mayor número de tokens, más contexto
Sin embargo nuestros problemas no terminan aqui. Cuando el texto crece un poco de tamaño las frases siguen teniendo sentido…pero el texto pierde el contexto del mismo. Empieza contando la historia de un niño y su perro, a mitad se transforma en un articulo periodístico sobre la revolución industrial y se acaba convirtiendo en una receta de pastel de manzana.
Para resolverlo necesitaríamos un mecanismo que tuviera en cuenta todo el texto para generar el siguiente token. Pero no basta con tener en cuenta todo el texto, hay que saber que partes influyen mas en el token que estamos eligiendo. Para ello tiene que valorar correctamente el aporte de cada uno de los tokens del texto. Si sale la palabra «azul» ¿Influye sobre el token que estoy generando ahora o hace referencia a otra cosa y no influye?. A este mecanismo le llamaremos atención.
El mecanismo de atención encuentra relaciones entre tokens
Por último añadiremos un pequeño detalle. En lugar de tener libros de numero de paginas fijo (410), vamos a poner un token de «<fin de libro>» que permita tener libros de cualquier número de paginas (siempre que el mecanismo de atención pueda gestionar textos de ese tamaño).
Hemos estado todo el tiempo hablando de «tokens más probables» de hecho es la base de nuestra biblioteca….pero ¿Cómo sabemos que tokens son más probables? Habrá que sacar esa probabilidades a partir de los textos de nuestros libros, revistas, webs, emails, ….. A más variedad y cantidad de textos mejor.
¡Ya esta! ¡Ya tenemos nuestra biblioteca! Puede generar casi cualquier texto y ocupa mucho menos que que 25 ^ 1312000 libros.
Y si os dais cuenta, lo que acabamos de describir es un LLM (¡Sorpresa inesperada!). Un sistema capaz de generar casi cualquier texto (en el peor de los casos puedes configurarlo para que genere tokens «a lo loco» y volvemos al caso original) pero que prioriza aquellos que tienen sentido y coherencia.. solo que en lugar de bibliotecarios vagando por una biblioteca infinita tenemos prompts.
¿Con esto esta todo? Aun faltaría un pequeño detalle. Hay textos para los que es muy importante que el texto, ademas de tener sentido y coherencia, estemos seguros de que todo lo que se dice es correcto y veraz. Por ejemplo los artículos periodísticos (¡no os riáis!), los textos divulgativos, los ensayos, los trabajos que nos ha pedido hacer el profeso, ….
Aun no tenemos claro como lograr este añadido de la veracidad, hay alguna idea, pero ninguna ha funcionado al 100% Con ese pequeño detalle tendremos una biblioteca de la que el mismísimo Borges estaría orgulloso
Fooocus es una de las herramientas más sencillas para usar Stable Diffusion. Tiene un gran equilibrio entre complejidad y capacidades. En mi modesta opinión una de sus mayores carencias es la falta de ControlNet. Una herramienta que permite usar distintas características de la imagen para influir en el resultado. De tal forma que no solo podemos usar el prompt para describir la imagen que deseamos.
Es cierto que de forma nativa Fooocus soporta Canny (contornos), pero hay muchos más casos. A mi me interesa especialmente los esqueletos de OpenPose que permiten indicar deforma muy sencilla la posición de las personas en la imagen generada.
Los principales motivos para no soportar ControlNet son:
Falta de un buen ControlNet para SDXL, que es la versión de Stable Diffusion que usar Fooocus.
Necesidad de cargar varios ControlNet para cada tipo de imagen de referencia.
Añadir un preprocesador diferente para cada tipo de imagen de referencia que queramos extraer.
Por suerte desde la aparición de controlnet-union-sdxl-1.0, que permite usar un único modelo para múltiples ControlNet y que soporta SDXL, los dos primeros problemas han sido resueltos.
El tercer punto no queda más remedio que afrontarlo usando programas externos para generar las imágenes de referencia.
En el siguiente vídeo se explican los pasos para lograr integrar este modelo en Fooocus, sin tocar una sola linea de código:
Entre las múltiples amenazas que sus detractores y los medios de comunicación atribuyen a la IA esta la destruir nuestra cultura remplazando a los creadores humanos. Generalmente cuando se refieren a «destruir la cultura» no hablan de quemar libros en una hoguera, ni a que los seres humanos dejemos de crear obras artísticas. ¿Entonces si no afecta a las creaciones antiguas, ni a las nuevas, como puede la IA destruir la cultura?.
Porque la IA puede hacer algo más peligroso que quemar libros, puede escribirlos.
Haz click para verlo en Youtube
No pretendo ser alarmista. Soy defensor de la IA y creo que nos puede traer muchas cosas nuevas maravillosas. Pero no por eso hemos de ignorar las consecuencias negativas que puede tener. Los móviles son una herramienta muy útil pero no podemos negar los estragos que han causado en nuestra atención.
En este texto cuando hablamos de culturo nos a referirnos a la cultura como elemento de unión social. Muchas veces se habla del idioma común o las tradiciones como elementos que nos unen. Pero la ficción, la música, el arte o el cine pueden ser elementos de unión tan fuertes como los anteriores, influyendo en nuestro lenguaje y nuestra sociedad. No hay más que ver lo difícil que es entender los gustos de otras generaciones con las que compartimos idioma y tradiciones. La cultura es a la vez un reflejo y un modelo para la sociedad. ¿Cuantos movimientos sociales han estado representados por nuevos estilos artísticos?
Actualmente la IA es capaz de realizar labores creativas cada vez más avanzadas. Si sigue mejorando al ritmo actual, cosa que no sabemos si ocurrirá, en pocos años puede estar creando libros, películas, música e incluso videojuegos de forma autónoma.
Pero no basta con crear de forma «autónoma», eso no destruiría la cultura, como mucho afectaría a sus creadores que ahora compartirían el publico con la IA. Pero su función como elemento integrador seguiría siendo la misma. Al principio habrá gente que se mostraría contrario a las obras creadas por la IA y que dirá que eso no es: música, cine, literatura, pintura…Pero con el paso del tiempo y la aparición de más y más obras creadas por IA es posible que el número de detractores se reduzca. Al final volveremos a este punto, por ahora vamos a suponer que las obras creadas por IA triunfan.
En este punto tendríamos creaciones de humanos, de IA y mixtas. Para que la IA se imponga tiene que ofrecer algo que los humanos no ofrezcan y parece difícil que eso ocurra.
¿O no? El problema surge cuando a la IA generativa le sumamos otro tipo de algoritmos de IA, los de recomendación. Son algoritmos capaces de detectar tus gustos. Si bien se suelen usar para identificar los elementos que más probabilidad tienen de gustarte de una lista (básicamente recomendarte libros, películas o música). Pero pueden llegar a extraer características más concretas de que te gusta a partir de conocer nuestras obras favoritas o simplemente observando que contenido consumimos.
Es decir tendremos una IA que cuenta con datos concretos de que nos gusta y otra IA que es capaz de generar obras siguiendo nuestras peticiones. O lo que es lo mismo tendremos un autor dedicado a crear obras personalizadas y que ademas estarán pensadas para incluir los elementos que nos gustan. Y si algo no nos gusta con pedirle a la IA que lo reescriba desde ese punto todo listo. Eso es algo que las obras creadas por humanos no pueden ofrecernos.
Si lo pensáis bien, es un giro respecto a lo que se estila ahora. Actualmente se tratan de hacer obras que gusten a cuanta más gente mejor para sacarles el máximo rendimiento económico. En este caso seria la personalización absoluta. Obras creadas para ti y que posiblemente solo tu vas a disfrutar.
Lo que ocurrirá es que las obras culturales perderán su universalidad, ya no servirán para unir miles de personas, se tornaran algo más personal e intimo. La gente ya no leerá cómics de Superman si no de…DarkcityMan o como quieran que quieran que se llame el personaje que ese lector haya inventado para que la IA escriba sobre él. Perderemos universalidad pero ganaremos personalización. La obra se convertirá en un proceso interactivo.
Por ejemplo a mi me encantaría pedirle que hiciera una película de MacGyver contra Saw. Donde ganara MacGyver por supuesto (otros preferirán que gane Saw). El algoritmo debería de saber que me gustan las películas científicamente correctas así que los inventos y trampas debería de ser «realistas». Me gusta que tenga giros en el guion. ¡Y también me gustan los musicales! ¿Se atrevería a hacer «MacGyver vs Saw, el musical»? Es que me lo estoy imaginado y no me importaría nada pagar por ver eso. «¡Toma mi dinero!».
¿Nos ponemos tremendistas y decimos que la cultura humana va a terminar y con ello la sociedad que terminará convertida en una masa de individuos sin relación entre ellos? No, simplemente va a cambiar como funciona. Seguirá habiendo actividades como la historia, el deporte o la artesanía que servirán para crear grupos. Los humanos seguirán creando arte porque no todos lo crean para ganar dinero con él. Me atrevería a decir que la mayoría lo hacen porque les gusta y no por el dinero que muchas veces ni recuperan lo gastando en su afición.
No todo tiene que ser individualista. Podemos pedirle una IA que cree obras teniendo en cuenta los gustos de una pareja o un grupo de amigos. Creando así una especie de cultura propia con películas, música, libros y videojuegos que solo ellos conocen y disfrutan.
Por último una anécdota, hace poco cree una canción usando IA para mi pareja, que tuvo una temporada de obsesión por tener plantas. Me quedo….bueno le quedo a la IA….no quedó verdaderamente bien. Le sugerí el tema, elegí que partes se añadían, modifique la letra…perdí dos horas. Que es poco tiempo porque de otra manera no habría podido hacerlo en mi vida, no tengo oído musical, ni ritmo. Cada vez que intento tocar un instrumento llaman a la policía. Por supuesto la canción le encanto y nos unió mucho….que va ni siquiera la escucho. ¡La había escrito una IA!
¿Cual es la moraleja de esta historia? Que la IA solo triunfará si nos aporta algo que valoremos. Si el mercado (que somos nosotros) no las acepta no triunfaran, pero aunque lo hagan, si logran aportan algo especial que las obras humanas no pueden, la sociedad no se acabará, solo cambiará.
Cada día aprendemos más trucos que puede realizar la IA generativa. Vamos a ver como usar un modelo de lenguaje para comprimir textos.
Una técnica habitual en los programas de compresión es crear una nuevo vocabulario donde las secuencias de bits más repetidas, o lo que es lo mismo las más frecuentes, son reemplazadas por secuencias de bits más cortas. Como nada sale gratis en esta vida a cambio hay cadenas de bits cortas pero poco frecuentes que son reemplazadas por otras con más bits. Todos estos reemplazos se guardan en un diccionario que puede ir adjunto en el archivo comprimido si el diccionario es propio para cada fichero y generado a partir del contenido del propio fichero.
Hay otra opción, que el diccionario sea único para todos los ficheros que se compriman. En ese caso no es necesario incluirlo en el fichero. Lo cual ahorra espacio pero a cambio suelen ser sistemas especializados solo para un tipo de ficheros.
Ahora paremos a pensar una cosa: ¿Cómo surgieron los modelos de lenguaje? Originalmente eran sistemas para completar texto. Es decir, saben predecir cuál es la palabra (en realidad el token) más probable para continuar un texto. De hecho no solo saben cuál es la más probable, saben cómo de probable es cada una de las palabras (tokens) que conocen.
Dado un texto un modelo de lenguaje nos devuelve un listado ordenado de lo probable que es cada palabra.
Si un modelo es lo suficientemente bueno podríamos darle el comienzo de un texto y el modelo generaría el resto. Desgraciadamente no funcionan tan bien. Por lo que podemos añadir una corrección cada vez que la predicación sea incorrecta. Al final podemos guardar solo esas desviaciones respecto a las predicciones del modelo.
Obviamente este sistema comprime tan bien como lo bueno que sea el modelo prediciendo el texto. Para textos aleatorios será malo, para textos literarios será bueno.
Si quieres saber más de cómo funciona puedes ver el siguiente vídeo en YouTube:
Unas de las principales quejas que hay hoy en día con la IA generativa, es la incapacidad de poder determinar que textos ha creado un humano y cuál una IA.
Hay muchos sitios que prometen ser capaces de detectar los textos creados por una IA. Aunque los pocos que he probado caen pronto cuando le podés a la IA que escriba de otra manera. Además con la gran cantidad de diferentes IA que se pueden usar cada vez es más difícil detectarlos
Y si le damos un giro a la situación y en lugar de detectar el texto a posteriori lo escribimos a priori para que sea fácil reconocerlos. Para ello se pueden esconder marcas de agua dentro de un mensaje.
En imágenes, videos y audios hay mucho «sitio» donde esconder una marca que indique que el mensaje lo generó una IA sin afectar al mismo, de hecho hay gran cantidad de técnicas. Pero los textos son diferentes, hay pocos datos y muy estructurados. Eso significa que esconder nada en ellos es muy difícil. Todo cambio que hagas en el texto afecta negativamente a la calidad de este. Una sola letra puede transformar una palabra en un galimatias.
El truco está en modificar la distribución estadística de las palabras del texto que genera el modelo de lenguaje. Para ello se usan n palabras (tokens) anteriores para generar dos grupos pseudoaleatorios de palabras (tokens); rojas, prohibidas y verdes, permitidas. Por lo tanto un texto generado por una IA será completamente verde.
Peroooo nada es perfecto y hay un problema. Puede ser que en el grupo de las palabras verdes no exista ninguna muy apropiada para continuar el texto. Esto afecta a la calidad del texto, lo que hace que sea necesario permitir alguna palabra prohibida (roja) de vez en cuando.
Si quieres saber más sobre este tema, más detalles de cómo funciona, sus fortalezas y debilidades, cómo atacarlo, …. Puedes hacer click para ver el siguiente video: