DALL-E no solo permite crear imágenes a partir de un texto. Se pueden modificar y extender. La propia web tiene herramientas para hacerlo.
Pero como es algo que es más fácil de explicar visualmente que por escrito, podéis ver cómo hacerlo explicado en mi siguiente vídeo de mi canal de Youtube:
Haz click en la imagen para ver el vídeo en mi canal de Youtube
En una muestra de «delegar el trabajo a otros» vamos a intentar que sea GPT-3. El que nos cree el prompt para dibujar con DALL-E o con Stable Diffusion. Para ello vamos a jugar «al teléfono roto», le pediremos a GTP-3 que nos describa una obra de arte famosa, de la descripción quitaremos cualquier referencia a la obra original y le pasaremos ese texto a DALL-E y Stable Diffusion a ver que dibujan.
Antes de empezar or voy a ahorrar las pruebas que estuve haciendo hasta encontrar «las palabras mágicas» para que GPT-3 me describa el aspecto de algo y no me cuente su historia:
Describe what XXXX looks like in 50 words
Donde XXXX es lo que queremos que describa. La parte final de «in 50 words» es necesario para limitar el tamaño del resultado y que se centre en lo importante ya que DALL-E tiene un prompt limitado a 400 caracteres.
Pintura
Empezaremos por un cuadro famoso, la Mona Lisa
Describe what the Mona Lisa looks like in 50 words
Que GTP-3 completa con:
The Mona Lisa is a portrait of a woman with a soft expression and subtle colors. She is seated with her hands folded in her lap, and her gaze seems to follow the viewer around the room.
Tras «limpiarlo» le pasamos a DALL-E:
A portrait of a woman with a soft expression and subtle colors. She is seated with her hands folded in her lap, and her gaze seems to follow the viewer around the room.
Que crea como resultado:
DALL-E
DALL-E hace una curiosa reinterpretación, aunque lo de las manos no parece haberlo entendido.
Stable Diffusion
Stable Diffusion parece haber entendido mejor la tarea dando versiones más parecidas a lo que tenia en mente.
Escultura
Vamos a por la escultura, el David de Miguel Ángel: Describe what michelangelo’s david looks like in 50 words
Que obtiene: Michelangelo’s David is a life-size marble sculpture of the Biblical hero David, created between 1501 and 1504. The statue depicts David in the moment before he defeats Goliath, and is considered one of the most famous sculptures in the world.
Dude si dejar la referencia a David o no, decidi dejarla porque no apunta exactamente al David de Miguel Ángel. A life-size marble sculpture of the Biblical hero David, created between 1501 and 1504. The statue depicts David in the moment before he defeats Goliath, and is considered one of the most famous sculptures in the world.
DALL-E
DALL-E en este caso ha sabido captar el sentido sin copiar la obra. Ademas que esa barba le pega más a un personaje bíblico que el lampiño David de Miguel Angel
Stable Diffusion
Stable Diffusion se ha empeñado en sacar desnudos, muchos más parecidos al de Miguel Angel
Arquitectura
Vamos a por la arquitectura, la Torre Eiffel.
Describe what the Eiffel Tower looks like in 50 words
The Eiffel Tower is a large iron lattice tower located on the Champ de Mars in Paris, France. Built in 1889, it is one of the most recognizable structures in the world. The tower is 324 metres (1,063 ft) tall and has two platforms, the first at 187 metres (614 ft), and the second at 276 metres (906 ft). There are stairs and elevators to the top.
Tras limpiar todas la referencias (que son bastantes):
A large iron lattice tower built in 1889. The tower is 324 metres (1,063 ft) tall and has two platforms, the first at 187 metres (614 ft), and the second at 276 metres (906 ft). There are stairs and elevators to the top.
DALL-E
Para DALL-E Torre Eiffel no hay más que una.
Stable Diffusion
Stable Diffusion da resultados mucho más originales y esta claro que no sabe que hablamos de la Torre Eiffel
Para ver mas ejemplos, en este caso de un dragón, podéis ver el siguiente vídeo de mi canal de Youtube:
Un cadáver exquisito es una técnica creativa en la que varios autores construyen un texto, un dibujo o pintura de forma colaborativa pero sin saber que han hecho los otros autores. El resultado no se ve hasta que la obra esta terminada. A veces se le puede dar un tema, otras no. Vamos a simular estre proceso con DALL-E usando dos fotos, una de un asno y otra de un coche.
Subiremos ambas fotos, las uniremos y borraremos la parte central, dejando solo una pequeña parte que DALL-E pueda usar como pista para continuar ambas imágenes. La preparación tiene este aspecto:
Preparando el lienzo para DALL-E
Hay que tener claro que DALL-E solo recibe información del cuadrado que indica el editor, así que no tenemos que preocuparnos por lo que haya fuera.
En este caso queremos dejar volar la imaginación de DALL-E y como texto le vamos a pasar solo «photo»
Mi resultado favorito fue este:
El cadáver exquisito creado por DALL-E
Si deseas ver este proceso con más detalle (y los resultados descartados) puedes verlo en el siguiente vídeo de mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Tras leer el titulo poca introducción necesita esta entrada. Tan solo necesito una foto con marca de agua, para evitarme problemas voy a usar una foto mía (tomada por mi, no de mi). Y añadirle una marca de agua poco sutil.
Foto de un burro con marca de agua
Ahora la subo a DALL-E y con mucho cuidado borro la marca de agua
Ahora pidamos a DALL-E la foto de un burro «photo of a donkey» y elijamos el mejor resultado (según mi punto de vista):
¿Y si le pedimos un caballo? «photo of a horse«
Pero un caballo y un burro están «próximos» y si le pido algo muy distinto como un coche «photo of a car«
Parece ser que el contexto de la foto pesa mucho y se impone a nuestros deseos. ¿Y si no nos complicamos la vida y pedimos simplemente una foto? «photo»
¡Correcto! DALL-E tiene suficiente información en la imagen como para completarla.
Aunque todas las imágenes parezcan iguales hay diferencias entre ellas.
Quizás este sistema es muy descarado, me gustaría quitar la marca de agua y evitarme una denuncia del autor. ¿Y si genero una variación a partir de la imagen con marca de agua?. Como siempre me quedo con el mejor resultado de los cuatro:
Es difícil que el autor original defienda que esta es su misma foto (el burro no esta ni en la misma pose). Ademas DALL-Eme ha movido la marca de agua a un sitio donde molesta menos, no pasa nada por que ya sabemos como eliminarla.
Definitivamente no es que DALL-E permita eliminar marcas de agua, es que permite generar imágenes nuevas a partir de fotos con marca de agua y que ni el propio autor seria capaz de reconocer.
Vamos a usar GPT-3 para dibujar, o intentarlo. Y no hablo de usar DALL-E, si no de usar el propio GPT-3 para que genere el dibujo, para que esto sea posible el dibujo debería de cumplir las siguientes condiciones:
Tiene que estar realizado con texto. GPT-3 solo genera texto.
Tiene que poderse incluir una descripción del mismo. Para poder pasarla a GPT-3 como texto a completar
SVG
SVG es un lenguaje de descripción de gráficos vectoriales. Permite describir dibujos usando un lenguaje basado en XML. Es decir, un lenguaje de etiquetas. Como SVG puede ir directamente en el código HTML vamos a pasar a DALL-E el principio de una web con una etiqueta abierta de SVG (a la que podemos añadir el ancho y el alto fijando las dimensiones del dibujo). Para describir el dibujo que queremos, justo antes de esa etiqueta pondrrmos un comentario HTML (<!– –>) describiendo el dibujo.
Por ejemplo le pedimos una estrella
<!DOCTYPE html>
<html>
<body>
<!-- svg code to draw a star -->
<svg height="210" width="500"
Le damos a autocompletar
<!DOCTYPE html>
<html>
<body>
<!-- svg code to draw a star -->
<svg height="210" width="500"
xmlns="http://www.w3.org/2000/svg">
<!-- Define five points. -->
<polygon points="100,10 40,198 190,78 10,78 160,198"
style="fill:lime;stroke:purple;stroke-width:5;fill-rule:nonzero;" />
<!-- Define the top right point. -->
<circle cx="100" cy="10" r="4" fill="red" />
<!-- Define the left middle point. -->
<circle cx="40" cy="198" r="4" fill="red" />
<!-- Define the bottom point. -->
<circle cx="190" cy="78" r="4" fill="red" />
<!-- Define the top left point. -->
<circle cx="10" cy="78" r="4" fill="red" />
<!-- Define the right middle point. -->
<circle cx="160" cy="198" r="4" fill="red" />
</svg>
</body>
</html>
Lo primero que se me ocurrió es Ascii Art, un tipo de dibujo realizado con caracteres de texto, la idea era buena pero el resultado fue….curioso, a diversa peticiones:
A otras muchas peticiones respondió con cosas sin sentido o espacios en blanco
Emojis
Este era fácil y supuse que lo haría bien, usar emoticonos para representar ideas.
JS Canvas
Otra forma de dibujar es usando un canvas en una web y usar código JS para dibujar en el lo que quieras. la idea es parecida a SVG, pero con código JS.
Primero preparamos la web;
<!DOCTYPE html>
<html>
<body>
<canvas id="star" width="600" height="600"></canvas>
</body>
<script>
//Aquí ira el código generado por JS
</script>
La completaremos con el código que genere GPT-3
En lugar de pasarle la cabecera de la web le pasamos solo un comentario:
/* js code to draw a star in a canvas */
Le pedimos una estrella:
<!DOCTYPE html>
<html>
<body>
<canvas id="star" width="600" height="600"></canvas>
</body>
<script>
/* js code to draw a star in a canvas */
// Define the points of the star.
var points = 5;
var innerRadius = 50;
var outerRadius = 100;
var angle = Math.PI / points;
var x, y;
// Get the context of the canvas.
var canvas = document.getElementById('star');
var ctx = canvas.getContext('2d');
// Begin the path.
ctx.beginPath();
// Move to the first point.
x = canvas.width / 2 + Math.cos(0) * outerRadius;
y = canvas.height / 2 + Math.sin(0) * outerRadius;
ctx.moveTo(x, y);
// For each point draw a line to it.
for (i = 1; i <= points * 2; i++) {
x = canvas.width / 2 + Math.cos(angle * i) * (i % 2 === 0 ? innerRadius : outerRadius);
y = canvas.height / 2 + Math.sin(angle * i) * (i % 2 === 0 ? innerRadius : outerRadius);
ctx.lineTo(x, y);
}
// Close the path.
ctx.closePath();
// Fill the path.
ctx.fillStyle = '#000';
ctx.fill();
</script>
¡Casi! Y es fácil corregir el problema (basta con comentar el calculo del primer punto). Ahora, y esto le da nota extra, el método sirve para estrellas de cualquier numero de puntas, basta con cambiar la variable «points».
Ahora le pedimos un coche.
<!DOCTYPE html>
<html>
<body>
<canvas id="canvas" width="600" height="600"></canvas>
</body>
<script>
/* js code to draw a car in a canvas */
var canvas = document.getElementById('canvas');
var context = canvas.getContext('2d');
// draw car body
context.beginPath();
context.moveTo(75, 25);
context.quadraticCurveTo(25, 25, 25, 62.5);
context.quadraticCurveTo(25, 100, 50, 100);
context.quadraticCurveTo(50, 120, 30, 125);
context.quadraticCurveTo(60, 120, 65, 100);
context.quadraticCurveTo(125, 100, 125, 62.5);
context.quadraticCurveTo(125, 25, 75, 25);
context.stroke();
// draw car wheels
context.beginPath();
context.arc(75, 100, 10, 0, 2 * Math.PI);
context.fillStyle = "black";
context.fill();
context.lineWidth = 1;
context.strokeStyle = "black";
context.stroke();
context.closePath();
context.beginPath();
context.arc(125, 100, 10, 0, 2 * Math.PI);
context.fill();
context.lineWidth = 1;
context.stroke();
context.closePath();
</script>
La idea está ahí pero no es lo que queríamos
Vamos a darle más detalles a ver… «Un coche deportivo rojo»
<!DOCTYPE html>
<html>
<body>
<canvas id="canvas" width="1600" height="1600"></canvas>
</body>
<script>
/* js code to draw a red car in a canvas with id "canvas" */
var canvas = document.getElementById("canvas");
var ctx = canvas.getContext("2d");
// draw a rectangle for the car body
ctx.fillStyle = "red";
ctx.fillRect(30, 30, 150, 50);
// draw a triangle for the car roof
ctx.beginPath();
ctx.moveTo(40, 30);
ctx.lineTo(140, 30);
ctx.lineTo(90, 10);
ctx.fill();
// draw two circles for the car wheels
ctx.beginPath();
var centerX = 50;
var centerY = 75;
var radius = 20;
// draw left wheel
ctx.arc(centerX, centerY, radius, 0, 2 * Math.PI, false);
// move center coordinates to right wheel
centerX += 100;
// draw right wheel
ctx.arc(centerX, centerY, radius, 0, 2 * Math.PI, false);
// color the wheels
ctx.fillStyle = "black";
ctx.fill();
// reset the current path
ctx.beginPath();
// draw a line in the middle of the car to separate the two colors
ctx.moveTo(50, 30);
ctx.lineTo(50, 80);
ctx.stroke();
// stroke the current path with a thick line
ctx.lineWidth = 3;
ctx.stroke();
</script>
No es lo que tenía en mente, pero bueno un coche es, no sé si deportivo, y rojo también.
Conclusiones
Con dibujos muy sencillos e insistiendo a base de prueba y error se puede conseguir algo. Menos en Ascii Art que es una causa pérdida. No es un sistema cómodo, ni práctico. Eso no quita lo sorprendente que es que entienda lo que le pides y trate de dibujarlo, aunque sea con resultados irregulares.
Es posible que con un entrenamiento adecuado se puedan mejorar estos resultados. Hay que tener en cuenta que esta forma de dibuja obliga a entender como se relacionan los distintos elementos del dibujo entre ellos. no solo es dibuja la ruedas con dos círculos es colocarlas correctamente respecto al resto del dibujo.
Puedes ver un vídeo sobre el mismo tema en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Ya hemos visto a DALL-E enfrentarse a varios retos. Hoy enfrentamos a otro modelo, está vez código libre, Stable Diffusion. Le he pedido a un profesor de dibujo que le ponga un par de ejercicios y valoremos el resultado.
Ejercicio 1: Mándala
El enunciado del ejercicio es:
Crea un zendala. Elige una gama cromática de colores fríos o cálidos y crea una armonía cromática con colores afines. Usa un mínimo de dos colores y un máximo de tres.
Cambiamos «crear» por «dibuja» y «zendala» por «mandala», palabra mucho más conocida. Lo traducimos al inglés:
Draw a mandala. Choose a chromatic range of cold or warm colors and create a chromatic harmony with similar colors. Use a minimum of two colors and a maximum of three.
Y el resultado es:
Varios puntos a tener en cuenta:
Simula ser un dibujo a mano, coloreado y es un mandala. Lo damos por válido.
Escala cromática. Falla, no es lo que le hemos pedido, lo intenta pero no sabe que hacer. Incorrecto.
Ejercicio 2: Camaleón puntillista
El siguiente ejercicio tiene dos partes (iba a ser solo una pero el profesor sugirió un cambio)
Dibuja un camaleón con puntillismo en una jungla
Nos encontramos con la duda de ¿Cuál es la traducción de puntillismo? Google sugirió «pointillism» no estábamos seguros pero continuamos. El texto quedó:
draw a chameleon with pointillism in a jungle
Lo esperábamos en blanco y negro, pero no sé lo especificamos. El profesor da por bueno el resultado.
Solo es puntillista el camaleón, no la jungla. Puede ser culpa nuestra por no indicarlo ya que puntillismo hace referencia al camaleón
Falta un «trozo» de camaleón. Algo habitual en este tipo de IA, no se les da muy bien encuadrar la imagen
La pega es que el profesor esperaba un dibujo en blanco y negro, por lo que había que especificarlo en el prompt. Además pidió otro cambio. No se fiaba mucho de que el algoritmo no estuviera «copiando» imágenes. Por lo que en lugar de en la jungla, algo típico para un camaleón, pidió algo diferente, una escalera.
Cómo cuando usamos «stairs» dibujo un camaleón con un lápiz en la mano ¿? Usamos la palabra «ladder».
Dibuja un camaleón con puntillismo bajando una escalera. Blanco y negro
draw a chameleon with pointillism going down a ladder. Black and white
El profesor le da el visto bueno y lo considera como superado
Yo señalo que no esta «bajando la escalera». Pero no parece tener importancia
Resultado:
No es fácil dar una nota numérica ya que por un lado los dibujos son espectaculares, por otro comete errores muy simples como el usar más de tres colores en el mandala o cortar al figura del camaleón. El resultado seria claramente más que aprobado aunque no llegaría a sobresaliente.
Puedes ver la explicación en vídeo en mi canal de Youtube:
Vamos a enfrentar a DALL-E contra un diseñador profesional a ver quién diseña mejor logo para mi blog. Haremos dos enfrentamientos:
Primero pasaremos a DALL-E una descripción de la temática de la web y un poco de información sobre la misma. La idea es que DALL-E tenga, más o menos, la misma información que el diseñador. No se le va pasar ninguna descripción del logo deseado. Queremos ver la «creatividad» de DALL-E. Sobre los logos que más me gusten le pediré que genere variaciones.
En el segundo le pasaremos el logo generado por el diseñador y le pediremos que genere variaciones, a ver si puede mejorarlo.
Antes de empezar la confrontación hay que dejar claro que a DALL-E no se le van a valorar los textos, ya que tiene problemas para generar textos con sentido. Si que valoraremos el diseño de los mismos.
El logo con el que competir es el de este blog:
Generando un logo desde cero
Vamos a pasar a DALL-E una descripción del blog y su temática. También quién es Chispas, información que le sirvió al diseñador para crear el logo.
Un logo para una web sobre inteligencia artificial, electrónica y programación. El nombre de la web es "Chispas". "Chispas" es una inteligencia artificial.
En inglés:
A logo for a website about artificial intelligence, electronics and programming. The name of the website is "Chispas". "Chispas" is an artificial intelligence
Dejo Chispas sin traducir para evitar que influya añadiendo chispas electricas al logo.
No es el resultado esperado, quizás sirvan para portada de un disco indy, pero no valen como logotipo. Voy a probar el «menos es más» y a simplificar la prompt.
A logo for a website about artificial intelligence, electronics and programming.
Veamos los resultados:
Como me parecían muy «típicos» decidí darle una segunda oportunidad:
Los dos primeros casos de esta segunda prueba se parece más a lo que me paso el diseñador gráfico para comprobar como queda el logo con distintos fondos:
Aunque lo lógico sería elegir la imagen 1 y 2 para generar variaciones, no me convence mucho la imagen 1 con ese cuadrado queriendo ser la letra a, así que voy a elegir las imágenes 2 y 4 y pedirle a DALL-E que me genere variaciones a ver cuál es el mejor resultado de cada. De la 2 me gusta que parece una mezcla entre el logo de ahora (coincidencia) y algo orgánico. De la 4 la idea de mezclar medio cerebro «orgánico» con elementos claramente artificiales.
De la variaciones de la imagen 2 me quedo con esta:
Me gusta el estilo orgánico de estos diseños, me gusta tanto que me los guardo para usarlos. Un punto en contra es que en esta variación no ha entendido que la imagen debería ser la misma en cada cuadrante. Debo decir que son demasiado pequeños para usarlos como logo del blog.
De la variaciones de la imagen 4 he elegido esta:
En este caso me gustaría una mezcla del logo original (imagen 4) con este. Me gusta que este cerebro luzca más orgánico pese a mantener las lineas rectas. Prefiero los hexágonos a los círculos. Si tuviera que quedarme con una de las dos me quedaría con la original.
Humano: 1 DALL-E: 0.5 (no se merece un 0)
Variaciones del logo de un diseñador
En este caso partimos del logo ya creado por un humano y le pedimos modificaciones para ver qué ideas sugiere.
Debo reconocer que algunas de estas variaciones me gustan. No las veo como para sustituir la imagen original. Pero si como para tener variaciones para algunas secciones.
Humano: 1 DALL-E: 0.5 (no se merece un 0)
Conclusiones
DALL-E es capaz de crear logos, puede que no sean los mejores logos, pero para un apaño sirven. El mayor problema es que solo genera imágenes de 1024 x 1024, lo cual puede ser pequeño para usos profesionales. Los resultados no son llegar y usar, es necesaria la intervención humana para «retocar» el resultado. Creo que DALL-E puede ser más útil como fuente de inspiración, tanto para el cliente como para el diseñador, para crear una idea base de la partir que como herramienta de diseño completa.
Es importante señalar que diseñar un logo de forma profesional es más complicado que lo que hemos visto aquí. No hay tanta libertad ya que el cliente puede imponer restricciones, hay códigos de estilo que seguir, por ejemplo colores que definen la marca o la web. Ademas de la incapacidad de generar imágenes vectoriales que limita mucho su uso. Es cierto que hay herramientas que pueden convertir una imagen en vectorial y resolver este punto y el del tamaño.
Puedes ver un vídeo sobre este articulo en mi canal de Youtube:
Tras un intento fallido de generar sprites de un videojuego (aunque realmente lo interesante era hacer uncrop de la imagen). Vamos a intentar generar un cómic para ver si con DALL-E se puede narrar una historia en varias imágenes de forma secuencial. Me preocupa especialmente la capacidad de DALL-E para mantener la consistencia entre las distintas viñetas. Y ya se que no le puedo pedir que me ponga el texto. Por lo tanto el objetivo se reduce a una historia muda o a una que le añadiremos el texto después.
Primer intento
El más sencillo para mi. Escribo el guión, se lo paso. Me genera el comic y a partir de ahí solo es cuestión de tiempo hacerme una artista famoso y millonario.
El guion es el siguiente:
Una tira cómica de 4 paneles estilo Calvin Y Hobbes. La tira cómica es protagonizada por Kelvin, un niño, y el gato Fred. Panel 1: Kelvin baja del autobús escolar y se dirige a la casa de su madre. Es invierno, el suelo está nevado, Kelvin lleva un abrigo y un gorro en la cabeza. Panel 2: Fred le espera detrás tumbado en la entrada detrás de la puerta de la casa. El suelo es de láminas de madera, las paredes blancas y vemos un marco de fotos en una de las paredes. Panel 3: Kelvin abre la puerta de la casa. Panel 4: Fred salta sobre Kelvin y lo tira al suelo.
Ahora solo queda traducirlo, introducir algunos cambios pensando en que DALL-E lo entienda mejor y ver el resultado.
Primer problema, el prompt de DALL-E solo permite 400 caracteres. Así que hay que hacer una «poda» del texto original, al reducir el número de caracteres reducimos la descripción de las viñetas que pasamos a DALL-E. El resultado es el siguiente:
A 4 panels page with a comic strip in the style of Calvin and Hobbes. The characters are Kelvin, a kid, and Fred, a cat. Panel 1: Kelvin gets off the school bus. It is winter, the ground is snowy, Kelvin is wearing a coat and a wool cap. Panel 2: Fred is lying in the entrance behind the door of the house. Panel 3: Kelvin, from outside, opens the door of the house. Panel 4: Fred jumps on Kelvin.
Tras realizar varios intentos me encuentro con los mismos problemas, vamos a ver unos pocos ejemplos:
El resultado se «parece» a lo que quiero conseguir….pero no es exactamente lo que quiero conseguir. Los problemas:
No tiene claro cual es el estilo que quiero.
No siempre me genera 4 viñetas y cuando lo hace las dibuja cortadas
No hace cuatro viñetas distintas, mas bien mezcla una o dos de las descripciones y las representa en las viñetas.
Pone cosas que parecen diálogos, no es un gran problema porque suele ponerlos donde es fácil borrarlos.
¿Donde esta el gato? Apenas aparece.
Explincadole a DALL-E lo que son las viñetas
Primero vamos a por el tema de las viñetas. Vamos a indicarle a DALL-E que no queremos que se salga de una estructura de pagina ¿Cómo? Con una plantilla como esta:
Subiremos esta plantilla, marcaremos como «borrar» las zonas grises y DALL-E solo podrá dibujar dentro de ellas.
Como no reconoce el estilo de dibujo que le pido le pongo uno que si que conoce: render 3D
También le facilito la vida eliminado los nombres de Kelvin y Fred, poniendo directamente niño (kid) y gato (cat)
A comic strip with 4 panels. Render 3D Panel 1: A kid wearing a coat and a wool cap gets off the school bus. It is winter, the ground is snowy. Panel 2: A cat is lying in the entrance behind the door of the house. Panel 3: kid, from outside, opens the door of the house. Panel 4: cat jumps on kid
Veamos algunos de los resultados:
Tiene mejor pinta pero las viñetas siguen siendo variaciones de una misma sentencia. Otro problema que se ha resuelto al decirle que trate de hacer algo con estilo render 3D , en lugar de un comic es que no pone «pseudopalabras» sueltas por el texto.
¿Entiende DALL-E que cada sentencia es una viñeta?
Vamos a probar las capacidades de compresión de DALL-E. Para ello le voy a pedir que me ponga una figura geométrica sencilla en cada viñeta. Se lo voy a pedir de dos formas, con números (1,2,3,4) y con ordinales (primero, segundo, tercero, cuatro).
A comic strip with 4 panels. Render 3D. Panel 1: a circle. Panel 2: a triangle. Panel 3: a square. Panel 4: a hexagon.
A comic strip with 4 panels. Render 3D. First Panel: a circle. Second Panel: a triangle. Third Panel: a square. Fourth Panel: a hexagon.
Selecciono un par de casos como ejemplo:
Esta claro que DALL-E no tiene una idea clara de lo que le pido.
Dibujo viñeta a viñeta
Siguiente prueba, si es incapaz de entender las cuatro viñetas a la vez, que pasa si se la explico de una en una. Empiezo por la plantilla que he creado antes, marco la primera viñeta como «borrar» y le paso la descripción de esa viñeta. Elijo el mejor resultado y lo uso para crear la segunda viñeta, elijo el mejor resultado y paso a la tercera y luego a la cuarta.
Me preocupa si mantendrá la coherencia entre viñetas o cada una será con un estilo.
Resumo el proceso poniendo cada una de las cuatro sentencias usadas:
[1] A kid gets off the school bus. It is winter, the ground is snowy, Kelvin is wearing a coat and a wool cap. 3D render [2] A cat is lying in the entrance behind the door of the house. 3D render [3] kid, from outside, opens the door of the house. [4] when the kid open the door a cat jumps on kid
El resultado de este proceso:
No creo que le den un premio Eisner. Pero funciona y mantiene cierta coherencia entre viñetas.
Hay varias cosas que podría mejorar:
Dedicar más tiempo a los prompts que en este ejemplo son muy poco detallados
Elegir un estilo mejor que render 3D
Se pueden introducir correcciones a mano en cada viñeta antes de generar las siguiente
Generar mayor número de pruebas, yo solo he generado 3 casos y elegido el mejor.
Marcar mejor los límites de la viñeta para evitar esa niebla gris que rodea cada viñeta (y que viene de los restos de color gris que no he marcado completamente para borrar)
Conclusiones
Por lo tanto ¿Es capaz de dibujar un comic?. Si, es capaz, pero no será un gran comic. Hay que indicarle la estructura de las viñetas a mano y cuidar mucho los prompts. Por otro lado se puede llegar a narrar una historia lo suficientemente bien como para entenderla.
Otro punto son los diálogos, a DALL-E no se le dan bien las palabras y hay que añadirlos a parte.
Puedes ver un vídeo sobre este tema en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Uncrop, palabra que tiene un difícil traducción al español, seria algo así como «desrecortar», lo que hace es, a partir de una imagen, extender esta hacia donde le indiquemos completando la «parte que falta» de la misma.
Veamos como hacerlo usando DALL-E
Para empezar a probarlo necesitaremos una imagen o dibujo para extenderlo. En este caso vamos a usar una nave espacial estilo pixel art. Se la pediremos a DALL-E:
pixel art spaceship for videogame
Nave generada por DALL-E
El resultado es una imagen de 1024×1024, ahora queremos que DALL-E use esta imagen como base para crear sprites para videojuegos. Para ellos, partiendo de nuestra nave, la reducimos a un 25% de su tamaño y la ponemos sobre un fondo negro de 1024×1024, realmente el color da igual, por comodidad es mejor que sea un color oscuro ya que la herramienta que tiene DALL-E para editar imágenes pinta de blanco las zonas a modificar.
La zona negra se marcará para borrar
Como puede verse hemos colocado la nave en la esquina superior izquierda, podemos colocarla donde queramos, sabiendo que la zona negra es la que se va a completar.
Subimos la imagen a DALL-E, marcarmos la zona negra como «para borrar» e introducimos la descripción de la nueva imagen que queremos obtener, en nuestro caso:
sprites of a spaceship for a video game: with engines on, with engines off, firing, with force field, damaged
El resultado:
No era lo deseado pero aun así se aproxima a la idea
Por una vez voy a poner un resultado que deja a DALL-E mal. Ha hecho algo que se parece a lo que le pedimos, pero no lo que le pedimos exactamente y es que el abuso de artículos, vídeos y demás donde se ven resultados increíbles (seleccionados, obviamente) no transmiten la realidad que es un punto intermedio entre lo sublime y lo fallido. Hace cosas increíbles, pero también a veces falla en otras mucho más simples y eso no quiere decir que no haya manera de usarlo para lo que le he pedido. Seguramente exista, quizás usando esta técnica para generar cada uno de los sprites uno a uno. O adaptando el texto introducido, usando prueba y error. Pero ya no es tan intuitivo como «pedirle lo que quieres».
Puedes ver otro uncrop en el siguiente vídeo de mi canal de Youtube:
Tras ver lo bien que funcionaba VQGAN+CLIP para generar imágenes yo también quería hacer un programa que creara arte a partir de un texto pasado como referencia. Por supuesto el resultado ha sido un fracaso, sin embargo se puede aprender de los fracasos.
La idea
La idea es usar solo CLIP con algoritmos genéticos. CLIP permite calcular (más o menos) la diferencia entre una imagen y un texto. Si le paso el texto «pato» y una foto me dice como de parecido es el contenido de esa foto al texto, en este caso a un pato. La idea es usar CLIP como función fitness. Para ello calculamos el vector que CLIP asocia a la imagen generada por nuestro algoritmo genético (luego vemos esto) y el vector que asocia a nuestro texto de referencia y calculamos la similitud coseno . La similitud coseno devuelve un valor entre -1 y 1:
1 significa que es idéntico
0 significa que no tiene nada que ver (es ortogonal)
-1 que es opuesto
Por lo tanto nuestra función fitness seria:
fitness = 1 - simCos(vectorTexto, vectorImagen)
Vamos a ver un poco de código.
Vector de características de texto:
#vector de carateristicas de texto
text_tokenize = clip.tokenize(TEXT).to(device)
with torch.no_grad():
text_features = model.encode_text(text_tokenize)
text_features /= text_features.norm(dim=-1, keepdim=True)
Vector de características de la imagen:
#vector de carateristicas de la imagen
image = preprocess(im).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
image_features /= image_features.norm(dim=-1, keepdim=True)
Teniendo una función fitness ya puedo usar cualquier metaheurística. En este caso se trata de optimizar una imagen para que se acerque cada vez más a lo que CLIP considera similar al texto.
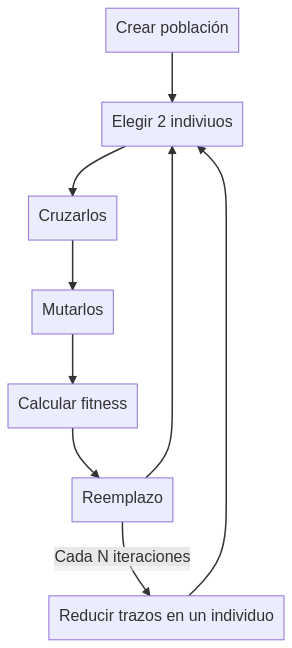
Para este caso vamos a usar algoritmos genéticos. Cada individuo es una imagen. Por lo tanto la población es un conjunto de imágenes que irán evolucionando y cruzándose compitiendo por reducir el valor de la función fitness.
Individuos, cruces y mutaciones
En un primer momento intente que el genotipo fueran los pixeles de la imagen y que las mutaciones y cruces fueran cambios aleatorios en los mismos. Manejar 16 millones de colores por cada pixel me parecían un espacio de soluciones muy amplio y decidí hacerlo en escala de grises por lo que solo tendría 256 posibilidades por pixel. Sin embargo el resultado fue un desastre los pixeles sueltos eran tan «pequeños» que creaba un «ruido» que no era capaz de evolucionar. Como solución intenté crear «píxels» más gordos. Para ello use cuadrados. Tampoco funcionó. Añadir colores dio como resultado cosas que podían tener sentido pro dentro de un ruido de colorines.
Siguiente plan, separar el genotipo y el fenotipo. El genotipo serían las instrucciones para construir la imagen mientras que el fenotipo sería la propia imagen. Como pasos para construir la imagen decidí usar pinceladas. En este caso para simularlas use líneas rectas que van de un punto aleatorio a otro, con color y anchura también aleatorios.
Una vez tenemos definidos los individuos hay que definir sus operaciones de cruce, de mutación y de reemplazo.
Operadores de cruce:
Intercambiar un bloque de trazos
Mezclar todos los trazos
No cruzar
Operadores de mutación:
Mover un trazo
Cambiar de color un trazo
Cambiar de orden un trazo por otro
Añadir un trazo
Como operador de reemplazo se reemplaza al peor individuo de la población (fitness más alto) por aquel hijo que tenga menos fitness que él.
Como el resultado era caótico, lleno de lineas de colores que no aportaban nada a CLIP pero dificultaba que un humano reconociera el dibujo decidí minimizar el número de trazos, para ello cada cierto tiempo se ejecuta una función de optimización local que prueba a eliminar cada uno de los trazos y si no altera o reduce la función fitness lo descarta.
Como último añadido y para dar más variedad a los trazos incluí que un trazo pueda ser una linea, un rectángulo o una elipse. Y una función mutación que cambia el tipo de trazo.
El resultado es un artista minimista que trata de trazar el menor número de líneas para dibujar un concepto.
Una Inteligencia artificial conceptual y minimalista
Hemos logrado un artista que crea con el menor número de trazos posible. Conceptual y minimalista…solo hay un problema que es un autor conceptual y minimalista desde el punto de vista de una IA. Hay imágenes en la que coincidimos, por ejemplo con las rosas:
Rosa
Otras imágenes sin embargo son incomprensibles, por ejemplo cuando le pido que me dibuje un pato le basta con dibujar una linea naranja rodeada de lineas verdosas, me lo hizo varias veces.
Pato ¿?
¿Por qué esa linea es un pato? Seguramente porque lo identifica con el pico y no necesita más para identificar un pato. Así que como nuestro autor minimalista reconoce patos por el pico (su rasgo más distintivo) es difícil que surja una mutación que mejore ese resultado.
Algo parecido me pasa con los dragones que no me pinta el cuerpo solo la cabeza, generalmente con algún tipo de «cresta» y a veces las patas, pero nada de cuerpo. Lo cual tiene sentido ya que su cuerpo se parece al de otros reptiles.
¿El dragón sin cuerpo?
Como herramienta puede ayudarnos a entender que «ve» una IA en una imagen.
Para probarlo dejo este enlace al codebook de Google donde probarlo