La familia de modelos SenseNova U1 ha llegado con una arquitectura cargada de novedades y soluciones interesantes. Se tratan de modelos que versátiles capaces de entender texto e imágenes cómo entrada, mientras que
¿Qué hace a SenseNova U1 tan especial? Aquí te resumimos sus pilares fundamentales:
Adiós a los Encoders Tradicionales: Procesamiento a Nivel de Píxel
A diferencia de la mayoría de los modelos que convierten imágenes en parches complejos dentro de un «espacio latente», SenseNova U1 utiliza un sistema de codificación ultraligera. Mediante redes convolucionales de dos capas que procesa la imagen en bloques de pixels. Esto permite conservar los detalles finos de la imagen que otros modelos suelen perder, logrando una fidelidad visual impresionante.
«Mixture of Transformers»: Lo mejor de dos mundos
El corazón de SenseNova U1 es una mezcla de transformers. El modelo es, a la vez, autorregresivo y de difusión.
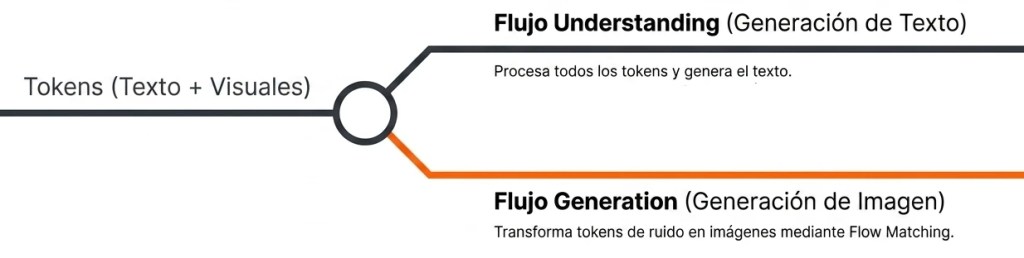
Ambos comparten el mismo contexto y mecanismo de atención, pero se bifurcan en diferentes flujos según el tipo de tokens que tenga que generar:
- Autorregresivo: El flujo llamado «Understanding» (comprensión) para entender el texto y las imágenes además de generar texto.
- Difusión: El flujo llamado «Generation» basado en flow matching se emplea para para generar imágenes.
Atención Híbrida: Causal y Bidireccional
Comparte el mecanismo de atención entre transformers, lo cual le obliga a combinar atención causal con atención bidireccional.

Para el texto, aplica una atención causal (donde cada token solo influye en la atención de los que viene detrás). Para las imágenes, cambia a una atención bidireccional, permitiendo que cada token interactúe con todos los demás de la imagen independientemente de su orden.
Eficiencia con Mixture of Experts (MoE)
Aunque el sistema completo cuenta con unos 17.000 millones de parámetros, su variante MoE es increíblemente ágil, funcionando con solo 3.000 millones de parámetros activos. Esto lo hace potente pero manejable, compitiendo en capacidades con modelos mucho más pesados.
Razonamiento Visual y Modelado del Mundo
Más allá de generar imágenes y textos, SenseNova U1 demuestra capacidades de razonamiento espectaculares. Es capaz de editar imágenes entendiendo conceptos abstractos o temporales. Por ejemplo, si le pides que dibuje qué pasará con un vaso de té después de una hora, el modelo es capaz de oscurecer el agua entendiendo el proceso de infusión. Esta capacidad lo posiciona no solo como un generador, sino como un posible «modelo del mundo» con potencial en robótica (VLA).

