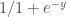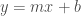Uno de los problemas de los test automáticos para probar aplicaciones es que no se guían por el aspecto visual de la aplicación. Puedes tener un botón torcido, un texto que no se lee o un color que no corresponde y los test serán correctos, sin embargo para el usuario es importante que el botón que tiene que pulsar sea visible o que pueda leer ese texto ilegible.
Es una tarea difícil de automatizar. Programar código para comprobar la correcta disposición de todos los elementos es algo muy costoso. Y tener una IA que detecte posible elementos erróneos puede sonar muy interesante pero es aun más costoso y complicado. Así que vamos a optar por una solución más sencilla, comparar una imagen que sabemos que esta bien con una captura de pantalla de la aplicación durante las pruebas. Luego calcularemos las diferencias entre ambas imágenes.
Hay múltiples librerías para realizar la comparación de la imagen como pixelmatch o Resemble.js. Aunque estas librerías tienen bastante funciones el algoritmo básico de comparación es muy sencillo. Se comparan uno a uno los pixel de la imagen de referencia con los de la imagen capturada, se fija un valor de umbral. Si la diferencia entre ambos pixel es mayor que el valor umbral se considera que ese pixel es distinto y se marca.
Para que funcione bien la imagen que se usa como modelo ha de ser idéntica a la que se obtiene de la captura de pantalla. Podéis estar pensando que siempre se puede reescalar una de la dos imágenes pero generalmente eso mete «ruido» en los bordes de los elementos de la imagen que el algoritmo de comparación detecta como diferencias.
Los pasos a segir son los siguientes:
- Captura de pantalla
- Cargar imagen modelo correspondiente
- Crear una tercera imagen comparando los pixeles de las dos anteriores. Cada pixel cuya diferencia supere cierto valor fijado se marcara como «diferente», por ejemplo poniéndolo en rojo.
- Buscar si existe alguna diferencia en la imagen resultado de la comparación
- Si existe alguna diferencia se deja la imagen con el resultado de la comparación y se avisa al usuario para que la revise.
El principal problemas son los datos que cambian cada vez que se realiza el test. Por ejemplo: ids de elementos, fechas, horas, elementos generados en parte o completamente por procesos (pseudo)aleatorios. Estos elementos dejan «una mancha» en el resultado de la comparación. Una solución para evitar estas manchas es «taparlas» para ello vamos a usar plantillas con una zona de un color especial que cuando el algoritmo las lee ignora.
Otra técnica para ignorar «pequeñas cantidades de error» es dividir la imagen en cuadrados, por ejemplo de 16×16. En cada cuadrado hay un total de 256 pixeles, solo lanzaremos una advertencia si la cantidad de pixeles marcados como diferentes supera cierto número. Por ejemplo el 20%, o lo que es lo mismo 51 pixeles. Con esto logramos que solo diferencias «notables» se consideren.
Este es un sistema realmente simple para ayudar a resolver el problema de comprobar el aspecto visual de la aplicación o la web durante los test. Si bien no resuelve todo el problema y sigue siendo necesario un humano para verificar las imágenes marcadas como errores. Agiliza mucho el proceso de comprobar el correcto aspecto visual de la aplicación o web.

![\sqrt[n]{\prod_{} x}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bn%5D%7B%5Cprod_%7B%7D+x%7D&bg=ffffff&fg=404040&s=0&c=20201002)