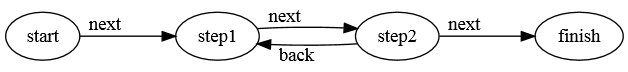Archivo de la categoría: Electrónica, robotica, Arduino, esp y SDR
en esta sección encontraras los artículos referentes a temas relacionados con la electrónica y la robótica, lo que incluye cosas como sensores, comunicación, arduino, …
Lo que vamos a ver en este texto tiene bastante de truco matemático, pero funciona lo suficientemente bien para que merezca la pena hacerlos.
Ya en otro post vimos como implementar la regresión lineal en Arduino, aprovechando ese mismo código se puede calcular la regresión para otras funciones que se pueden adaptar mejor a los datos que la lineal.
Cómo de aquí en adelante nos hará falta vamos a recordar que la fórmula de la regresión lineal es:
y = a + b*x
El algoritmo de la regresión lineal lo que hace es a partir de ejemplos de valores de x e y calcular los valores de a y b
Ahora intentemos explicar el truco que usamos. Primero tomamos la función que queremos ajustar a los datos, por ejemplo:
y = a * e^(b*x)
Buscamos una transformación lineal que deje la fórmula de la misma forma que la de la regresión lineal. En nuestro ejemplo calcular el ln de ambos lados de la igualdad:
ln(y) = ln(a) + b*x
Este truco solo funciona cuando sea posible encontrar una transformación de este tipo, que no siempre se puede.
Realizamos cambios de variables para transformar la formula:
x -> x y -> ln(y) a -> ln(a) b -> b
Ahora podemos usar el mismo algoritmo que en la regresión lineal solo que con un par de cambios de variables:
En la fase de aprendizaje, cuando tengamos la pareja de valores (x,y) le pasaremos al algoritmo de regresión lineal (x,ln(y))
Una vez calculados los parámetros no tendremos (a, b) si no (ln(a), b) por lo que para obtener a tendremos que elevar e al valor obtenido a = e ^ln(a)
Ahora que tenemos los parámetros (a,b) para estimar un valor en lugar de usar la ecuación de la recta (regresión lineal) usaremos y = a * e^(b*x)
Regresión exponencial
La fórmula de esta regresión es:
y = a*e^(b*x)
La transformación lineal que vamos a usar es:
ln(y) = ln(a) + b*x
Como ya hemos visto los cambios de variable son:
x -> x y -> ln(y) a -> ln(a) b -> b
En pseudocódigo:
regExp::learn(x,y){
regLineal.learn(x,ln(y));
}
regExp::calculate(x){
a = e ^ regLineal.a;
b = regLineal.b;
y = a*e^(b*x);
return y;
}
Regresión logarítmica
La fórmula de esta regresión es:
y = a*ln(x)+b
La transformación lineal que vamos a usar es:
y = a*ln(x)+b
Efectivamente es la misma puesto que ya tiene la forma deseada.
Los cambios de variable son:
x -> ln(x) y -> y a -> a b -> b
En pseudocódigo:
regLog::learn(x,y){
regLineal.learn(ln(x),y);
}
regLog::calculate(x){
a = regLineal.a;
b = regLineal.b;
y = a*ln(x)+b;
return y;
}
Regresión potencial
La fórmula de esta regresión es:
y = b*x^a
La transformación lineal que vamos a usar es:
ln(y) = a*ln(x)+10^b
Los cambios de variable son:
x -> ln(x) y -> ln(y) a -> a b -> 10^b
En pseudocódigo:
regPot::learn(x,y){
regLineal.learn(ln(x),ln(y));
}
regPot::calculate(x){
a = regLineal.a;
b = 10^regLineal.b;
y = b*x^a
return y;
}
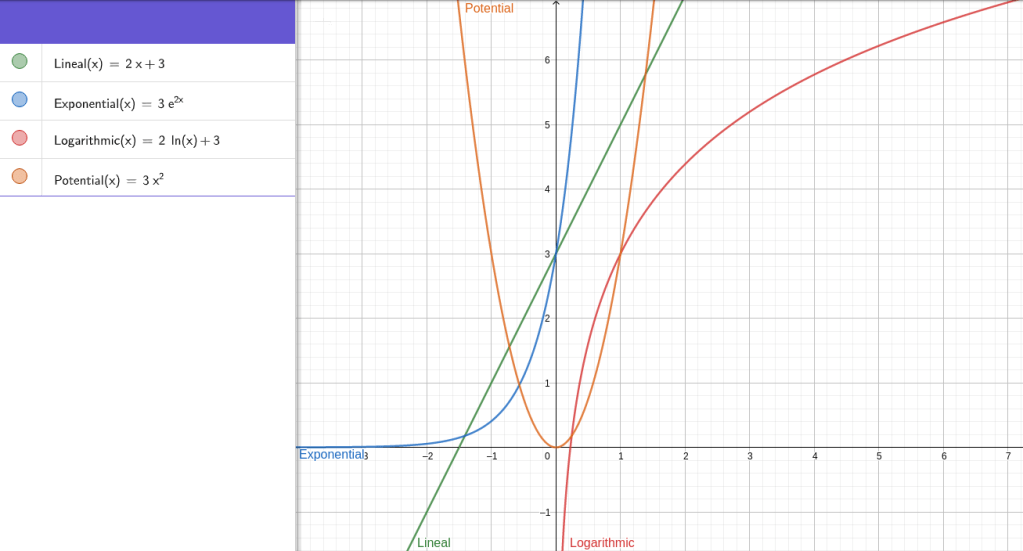
Ejemplo gráfico
Para ver bien las diferencias entre las cuatro regresiones dejo esta imagen donde se pueden ver todas para los valores a= 1 y b = 3
Comparativa entre las cuatro regresiones con a= 2 y b = 3
La librería
Todo lo aquí explicado se puede encontrar en la librería Regressino que implementa estas cuatro regresiones con ejemplos de como usarlas
Vamos a ver cómo crear una máquina de estados finitos muy sencilla para Arduino o Node MCU. Debido a las limitaciones de ambas plataformas vamos a ver una idea muy sencilla.
Empezaremos por aclarar los conceptos básicos:
Estados: son los distintos valores que puede tomar la máquina de estados finitos.
Eventos: producen el cambio de un estado a otro.
Transiciones: definen como los eventos cambian los estados. Cada transición constan de tres elementos, un evento, un estado origen y un estado destino. Indica que cuando se produzca el evento si el estado actual es el estado origen este cambiará por el estado destino.
Una mef (máquina de estados finitos) está siempre en un único estado y hay eventos que producen el cambio de estado siguiendo unas reglas (las transiciones). Aunque con esto ya tenemos una mef, para que sea realmente útil tiene que facilitar la ejecución de funciones asociada a los distintos estados y eventos.
Para facilitar todo esto podemos usar la librería easy finite state machine que simplifica la programación usando macros del preprocesador.
Estados y eventos
Vamos a empezar por los eventos y estados, para ello podemos usar enum de C que nos permite escribir código de forma muy intuitiva.
STATES {start, step1, step2, finish};
EVENTS {next, back};
También habrá que definir una variable que guarde el estado actual e inicializarla con el estado inicial.
enum States efsmState = start
Con la librería:
INIT(start)
Cambiar el valor del estado es muy sencillo, basta con hacer:
efsmState = start
O con las macros:
changeState(start)
Así como comparar el valor del estado:
isState(start)
Transiciones:
De todas formas lo habitual no es realizar los cambios de estados directamente sino a través de eventos. Los eventos vamos a gestionarlos con la función efsmEvent(event) que los aglutina todos. Esta función recibe el evento como parámetro y contiene las transiciones. Básicamente son un montón de «if». Usando la librería se usa la macro TRANSITION
Su significado es: Si se lanza el evento y el estado es el estadoOrigen se pasa al estadoDestino y se llama a función. No es necesario poner una función asociada, se puede dejar en blanco.
Las transiciones se definen entre las macros:
START_TRANSITIONS y END_TRANSITIONS
Las transicione son una gran ayuda, aunque su funcionamiento se puede sustituir con isState(state) y changeState(state).
Cuando se ejecuta efsmExecute() verifica y llama a la función asociada a cada estados. Es decir, cuando se llama a esta función se verifica en qué estado está la máquina y llama a la función asociada a ese estado. Con la forma que tiene Arduino de funcionar usando una función loop que está en bucle constante la idea es colocar efsmExecute() en la función loop() para que se llame en cada iteración.
EXECUTION(executionState,function())
Si no se asocia ninguna función a un estado no se ejecutará nada.
Se definen entre las macros:
START_EXECUTIONS y END_EXECUTIONS
No es obligatorio definirlas. Por ejemlo cuando la mef solo tenga que lanzar funciones en los cambios de estado (transiciones).
Disparadores:
Los disparadores generan eventos asociados a distintos sucesos. Su idea es facilitar la programación de acciones habituales que lanzan eventos. Se ejecutan cuando se llama a la función efsmTriggers().
Para que un disparador se lance, el estado de la mef ha de ser el mismo que el que se le pasa como primer parámetro. Hay de tres tipos de disparadores:
Un condicional lanza un evento si el condicional especificado se cumple:
CONDITIONAL(state, condition, event)
Un contador lanza un evento después de haber llamado un número determinado de veces a la función efsmTriggers() tras al último evento válido.
COUNTER(state, number, event)
Un temporizador lanza un evento cuando ha pasado un determinado tiempo (en milisegundos) desde que se lanzó el último evento válido.
TIMER(state, number, event)
«Tras el último evento válido’ significa que cada vez que se lanza un evento y este produce una transición los contadores se reinician. Si se quisieran reiniciar a mano se pueden usar: resetTimer() y resetCounter()
Los disparadores se definen entre las macros:
START_TRIGGERS y END_TRIGGERS
No es necesario definir disparadores , si se quiere lanzar algún evento manualmente se puede hacer llamando directamente a efsmEvent(event).
En resumen:
Se definen estados y eventos.
Se establece el estado inicial.
Se crean transiciones que indican que cambios entre estados se producen con cada evento asi como la función que se lanzara cuando se produzca esa transición.
Se escriben la ejecuciones indicando que función se lanzará cuando la máquina este en cada estado.
Se declaran los disparadores que lanzaran eventos (o se programa el lanzamiento a mano).
Se añade a la función loop efsmExecute() y efsmTriggers()
Un ejemplo:
Para ver todo un poco más claro vamos a ver un ejemplo basado en el que incluye la librería. En el se modela la máquina de estados finitos representada en el siguiente diagrama:
Máquina de estados finitos del ejemplo
El código es el siguiente:
#include <efsm.h>
STATES {start, step1, step2, finish};
EVENTS {next, back};
INIT(start)
START_TRANSITIONS
TRANSITION(next,start,step1,Serial.println("next")) //next start -> step1
TRANSITION(next,step1,step2,Serial.println("next")) //next step1 -> step2
TRANSITION(next,step2,finish,Serial.println("next")) //next step2 -> finish
TRANSITION(back,step2,step1,Serial.println("back")) //back step2 -> step1
TRANSITION(ANY_EVENT,ANY_STATE,ANY_STATE,Serial.println("FAIL!!!")) //in any other case
END_TRANSITIONS
START_EXECUTIONS
EXECUTION(start,Serial.println("start")) //state is start
EXECUTION(step1,Serial.println("step1")) //state is step1
EXECUTION(step2,Serial.println("step2")) //state is step2
EXECUTION(finish,Serial.println("finish")) //state is finish
END_EXECUTIONS
START_TRIGGERS
COUNTER(start,5,next); //State start wait 5 iterations and launch event next
TIMER(step1,2000,next); //State step1 wait 2 sg and launch event next
END_TRIGGERS
void setup() {
Serial.begin(9600);
resetTimer();
resetCounter();
}
void loop() {
efsmExecute();
if(isState(step2)){
efsmEvent(next);
}
efsmTriggers();
delay(1000);
}
Este texto mejorado y ampliado forma parte de mi libro sobre como mejorar tus programas en Arduino. Puedes echarle un vistazo aquí.
Puedes ver un vídeo sobre el tema en mi canal de Youtube:
Haz click para ver el vídeo en mi canal de Youtube
Aprovechando lo que hemos creado en la entrada sobre el debug en arduino vamos a usarlo para para realizar test en el código de nuestros programas en arduino.
Al igual que el código debug, todo el código de test ha de desaparecer del código compilado cuando se quite el #define TEST. Por ejemplo en este caso cuando hacemos tests en lugar de devolver el valor de la entrada analógica fija uno por defecto, sin embargo cuando no hagamos test funcionara de forma correcta.
#ifdef TEST
//código que se ejecutara para los test
sensor = 128;
#else
//Código que se ejecutara cuando no haya test
sensor = analogRead(sensorPin);
#endif
También necesitamos una función que nos envíe por el puerto en serie si un test ha sido correcto o incorrecto. Como verificar le null a veces tiene su complejidad se ha creado otra función propia para ello.
En lugar de llamarlas directamente se hace usando las macros TEST(X) y TESTNULL(X). Para que desaparezcan cuando se desactiven los test.
¿Pero que pasa si cuando un test falla queremos para la ejecución? Por ejemplo porque puede ser peligroso para el circuito o porque algún elemento no se ha inicializado correctamente. Para eso se han definido dos funciones idénticas pero dentro de la etiqueta ERROR ya que pueden ser utiles en la ejecución habitual del programa cuando ya no se hacen test. ASSERT(X) y ASSERTNONULL(X)*. La diferencia con TEST es que si son ciertas paran la ejecución del programa llamando a la función stop() definida en la librería.
Esta función bloquea la ejecución del código creando un bucle infinito y bloqueando las interrupciones. Es una salida segura cuando no sabes como continuar y hacerlo podría dañar algo. También se le puede llamar directamente usando la macro STOP
Un ejemplo de uso:
#define DEBUG
#define TRACE
#define INFO
#define ERROR
#define TEST
#include <Debug.h>
int c = 0;
void(* reset) (void) = 0;
void setup() {
Serial.begin(9600);
}
void loop() {
TRACEMSG("Start loop");
inc();
TEST(c 40)
STOP
#endif
delay(500);
}
void inc(){
ENTER
c++;
EXIT
}
La forma habitual de hacer debug en arduino usar la instrucción Serial.print() para mostrar en la consola de monitorización del IDE de arduino los datos.
Este sistema tiene varias pegas:
Aumenta el tamaño del codigo y el espacio que ocupa el mismo
Consume tiempo de ejecución
Interfiere con el uso del puerto USB o de la comunicacion serie
No aporta ninguna informacion para saber en que parte del codigo ocurre.
No distingue entre mensajes de log, traza, debug, error…..
Una forma de resolver parte de estos problemas es usando el preprocesador de C.La idea es definir una serie de macros cuyo valor dependa de que se haya definido una variable del preprocesador. De tal forma que si la variable no esta definida la macro se reemplazada por nada asi evitamos que cuando no consuma espacio en memoria, que interfiera con el uso del puerto serie cuando no estamos depurando.
De tal forma que cuadno queremos depurar definimos la siguiente variable
#define DEBUG
Y todas los sitios dodne aparezca DEBUGPRINT(X) seran sustituidos por Serial.print(X); Pero cuando la quitamos todas las lineas son reemplazadas por nada y desaparecen del programa no ocupando ni esapcio ni tiempo de ejecución.
Hay que definir otro más, DEBUGPRINTLN(X) para el caso de que en lugar de quere un Serial.print(X) queramos usar un Serial.println(X)
Ademas vamos a permitir incluir alguna informacion de en que funcion, archivo y linea del codigo estmos.
Podemos definir varias macros según el los «niveles» de log mostrando solo los que nos interesen, en nuestro caso vamos a definir cinco: DEBUG TRACE INFO ERROR TEST
Al final nos quedan quince macros, a las que se han añadido dos más ENTER y EXIT para indicar la entrada y salida de una función que resultan muy útiles para la traza del código.
DEBUG:
DEBUGPRINT(X) Serial.print(X); DEBUGPRINTLN(X) Serial.println(X); DEBUGMSG(X) Serial.println(«DEBUG function file.ino:line X»);
TRACE:
TRACEPRINTLN(X) Serial.println(X); TRACEPRINT(X) Serial.print(X); TRACEMSG(X) Serial.println(«TRACE function file.ino:line X»); ENTER Serial.print(«TRACE: ENTER -> function»); EXIT Serial.print(«TRACE: EXIT -> function»);
INFO:
INFOPRINTLN(X) Serial.println(X); INFOPRINT(X) Serial.print(X); INFOMSG(X) Serial.println(«INFO function file.ino:line X»);
ERROR:
ERRORPRINTLN(X) Serial.println(X); ERRORPRINT(X) Serial.print(X); ERRORMSG(X) Serial.println(«ERROR function file.ino:line X»);
TEST:
TESTPRINTLN(X) Serial.println(X); TESTPRINT(X) Serial.print(X); TESTMSG(X) Serial.println(«TEST function file.ino:line X»);
Todo estas macros y alguna funcionalidad más se puden encontrar en la libreria debugino.
En un ejemplo de su uso podemos ver como funciona. Hay que señalar la necesidad de inicializar la comunicación serie con Serial.begin(9600);. Para configurar que mensajes se muestran y cuales no basta con quitar el #define correspondiente y esos mensajes desaparecerán.
#define DEBUG
#define TRACE
#define INFO
#define ERROR
#define TEST
#include <Debug.h>
int c = 0;
void setup() {
Serial.begin(9600);
}
void loop() {
TRACEMSG("Start loop");
inc();
TEST(c < 30);
DEBUGPRINT("Value of C ")
DEBUGPRINTLN(c);
#ifdef ERROR
if(c > 40)
STOP
#endif
delay(500);
}
void inc(){
ENTER
c++;
EXIT
}
Este texto mejorado y ampliado forma parte de mi libro sobre como mejorar tus programas en Arduino. Puedes echarle un vistazo aquí.
También puedes ver el vídeo sobre este post en mi canal:
Haz click para ver le vídeo en mi canal de youtube
Los umbrales son la forma más intuitiva de filtrado de errores. Consiste en establecer valores a partir de los cuales no confiamos en las medidas de nuestros sensores. Estos umbrales pueden establecerse por varios motivos.
Limite de funcionamiento de nuestro sensor. Son los limites más alla de los cuales sabemos que nuestro sensor no trabaja correctamente. Por ejemplo muchos sensores de distancia comienzan a dar lecturas muy poco confiables a partir de ciertas distancias tanto de muy cerca como de muy lejos.
Limites del entorno. Limites esperados del entorno donde nuestro sensor esta situado. Por ejemplo un sensor de teperatura colocado en una habitación normal de una vivienda se pueden fijar como limites como límite inferior 0° y como limite superior 60° aunque el sensor trabaje en un rango mayor de temperaturas.
Umbrales para el valor
Se aplican directamente al valor medido por el sensor. Las lecturas que excedan los limites son eliminadas. Estos filtros con los primeros que se comprueban y facilitan el trabajo de los filtros que apliquemos después al eliminar valores erroneos extremos. Su implementación es muy sencilla.
Siendo S el valor medido por el sensor , y Tmin y Tmax los umbrales mínimo y máximo S será válido si:
S > Tmin & S < Tmax
Umbrales para el cambio
Se aplican a la cantidad que cambia el valor medido por el sensor en un tiempo determinado. Para poder usar este filtro es necesario conocer el tiempo que a transcurrido entre medidas del sensor. Se fija un valor máximo de cambio por unidad de tiempo. El valor del sensor se considerará valido si el cambio de valor respecto de la lectura anterior es menor que el tiempo transcurrido por el valor máximo de la unidad de cambio
Siendo S el valor medido por el sensor, t el momento actual, dt el periodo de tiempo transcurrido desde la anterior medida de valores del sensor, T el umbral de cambio máximo permitido S será válido si:
Hay que tener en cuenta que S puede ser un valor correcto dentro de los umbrales Tmin y Tmax, pero que ha cambiado demasiado rápido para considerar la lectura correcta. por ejemplo tenemos un sensor de temperatura dentro de una habitación y en un segundo la temperatura pasa de 12º a 35º, obviamente hay algo mal.
Partimos de que tenemos una fuente aleatoria de bits (como el generador del mi otro post) pero desconocemos si es justa. ¿Que significa justa?. Significa que ambos valores (0,1) tiene la misma probabilidad (50%). Un bit puede ser aleatorio, pero no por ello sus posible valores han de tener la misma probabilidad. Vamos a usar como ejemplo un generador de bits cuyas probabilidades son:
P(0) = 0,1 = 10% P(1) = 0,9 = 90%
si usamos esta fuente para generar bytes, números con muchos bit a 1 (11111101, 11110011,….) son más probables que el resto. Para evitar esto podemos convertir el generador de números en uno justo.
Para transformar la salida de ese generador en un salida justa necesitamos obtener dos bits. Si son iguales los desechamos, si son distintos devolvemos el valor del primero (también se podría usar el del segundo). ¿donde esta el truco? Que las probabilidad de que la pareja de bits sea [0,1] o [1,0] son siempre las mismas.
[0,1] = P(0) * P(1) [1, 0] = P(1) * P(0)
Podemos ver una tabla con todas las opciones
Bit1
Bit2
Resultado
Probabilidad
Ejemplo
0
0
P(0) * P(0)
0,1 * 0,1 = 0,01
0
1
0
P(0) * P(1)
0,1 * 0,9 = 0,09
1
0
1
P(1) * P(0)
0,9 * 0,1 = 0,09
1
1
P(1) * P(1)
0,9 * 0.9 = 0,81
La desventaja de este sistema es que si las probabilidades están muy desparejadas puede costar tiempo encontrar una pareja distinta, en este caso el 82% de la veces habrá que descartar la pareja de bits.
Sin embargo cuenta con la ventaja de que no hace falta que conozcamos las probabilidades si tenemos dudas y necesitamos que nuestra cadena aleatoria, simplemente podemos aplicar este método y listo.
El código de ejemplo:
byte randomFairAnalog(int analogInput){
byte rnd = 0;
for(int i = 0; i < 8; ){
delay(5);
int aux1 = analogRead(analogInput)%2;
delay(5);
int aux2 = analogRead(analogInput)%2;
if(aux1 == aux2)
continue;
rnd += (aux1 << i);
i++;
}
return rnd;
}
Cuidado con este código en caso de que por algún motivo las lecturas del puerto dejen de ser aleatorias y sean todo el rato la misma la función caerá en un bucle infinito.
El ruido puede causar comportamiento errático. En este caso vamos a ver que problemas puede causar cuando hay un umbral de activación en un sistema. Por ejemplo una célula fotoeléctrica que determina cuando encender o apagar unas luces. Para ello hemos programado un microcontrolador «lea» el valor de la célula y cuando sea menor de 100 encienda la luz. Cuando el valor se aproxime a este punto puede devolver lecturas como estas:
100, 99, 98, 101, 102, 99, 100, 97
Que traducido a la luz que controla sería:
Off, On, On, Off, Off, On, Off, On
La bombilla parpadea sin parar, va parecer que los espíritus tratan de comunicarse con nosotros a través de ella. Para evitar eso se puede separar el umbral en dos. Uno para encender la luz y otro para apagarla. A este hueco se le llama histéresis. Por ejemplo se podría decidir que por debajo de 100 se enciende pero no se apaga hasta que el valor sea 105. Esta distancia sirve para evitar que la luz actúe erraticamente encendiéndose y apagándose sin parar cuando el valor es próximo al del umbral de activación.
Este metido es para detectar y reducir los ruidos intensos y poco frecuentes. La idea principal es que el valor leído más el ruido de baja intensidad se comportan como una función de normal. Se podría ver como que a mayor intensidad del ruido menos probable es que aparezca. Visto en forma de gráfica:
En la imagen se puede ver que según un valor se aleja de la media (μ) menos probable es que pertenezca a la muestra. Así que según su distancia a la muestra podemos saber lo probable que es que pertenezca. Sabiendo esto se ponen una distancia máxima a la media de tal forma que habrá dos umbrales (μ+distancia y μ-distancia) los valores que queden fuera de esos umbrales de eliminan. Valores habituales de filtrado corresponde a μ±σ, μ±2σ y μ±3σ. O aproximadamente dejan fuera el 16%, 2% y 0.1% de los valores (a cada lado del umbral).Para filtrar valores fijamos la probabilidad de pertenencia a la muestra que les «exigimos». Por ejemplo si un valor solo puede pertenecer a la muestra con una seguridad del 5% lo descartamos.
Este proceso lo podemos aplica una vez o varias, repitiéndolo hasta que no se elimine ninguno de los valores.
Una vez eliminados los valores que quedan fuera del umbral podemos aplicar alguno de los filtros ya vista como la moda, mediana o media para calcular el valor.
Ejemplo:
Usamos como limite 2σ. repetiremos el filtrado hasta que no haya descartes en las muestras
Otra idea para reducir el ruido es ordenar todos los valores y coger el central. La idea es muy parecida a la de la media. Se considera el ruido como la suma de una pequeña cantidad aleatoria cuyo valor oscila entre -e y e. Si el valor real es V las muestras se dividirán entre la que sumen el ruido (V+e) y la que lo resten (V-e) . Quedando el valor real V mas o menos en el centro de todos los valores. La mediana es precisamente eso, el valor en el centro de todos los valores. Para calcularlo es necesario ordenar la lista de muestras. Este es su punto débil ya que aumenta el coste computacional de calcular la mediana.
Tiene varias ventajas:
Es sencillo
Es insensible al ruido intenso pero poco frecuente.
También tiene sus inconvenientes:
Ordenar las muestras puede ser una tarea costosa a nivel computacional
Solo se puede usar cuando se puedan tomar varias muestras de la misma medida
Ejemplo:
Partimos de las siguientes muestras [23, 4, 5, 5, 6, 4, 5, 4, 5, 6, 4, 12]
Mediana: 5
El resultado no se ha visto influido por los valores extremos (12 y 23)
El uso de la moda para evitar el ruido es parecida al caso de la media, pero en lugar de sumar todos los valores se selecciona el que más veces se repite. La idea en que se basa en que la mayoría del ruido es pequeño así que el valor que más veces aparezca es el más cercano al real.
Al igual que la media, esta técnica solo sirve si se pueden capturar suficiente numero de muestras sin que el valor cambie de forma apreciable. En este caso necesitamos mas valores que en caso de la media.
Tiene varias ventajas:
Es sencillo
Requiere poco «coste computacional»
Es insensible al ruido intenso pero poco frecuente.
También tiene sus inconvenientes:
Solo se puede usar cuando se puedan tomar varias muestras de la misma medida
Requiere muchas medidas para ser exacto
Por lo general supone perder «resolución» en la medida para poder «agrupar» las medidas y calcular la moda. Por ejemplo si tenemos los valores 4,13 y 4,18 hay que eliminar el último decimal para poder contar ambos como el mismo valor 4,1
Ejemplo:
Partimos de las siguientes muestras [23, 4, 5, 5, 6, 4, 5, 4, 5, 6, 4, 12]
Moda: 4
El resultado no se ha visto influido por los valores extremos (12 y 23)