Los password de un solo uso también llamados OTP (One Time Password) son passwords que solo se pueden usar una vez o durante un periodo de tiempo breve. Es una buena medida de seguridad, aunque estas contraseñas sean robadas o interceptadas se reduce el tiempo que el atacante puede acceder al sistema. Uno de sus usos es como segundo factor de autenticación. Casi todos habremos tenido que usar alguna vez códigos que nos envían al móvil o que genera algún aplicación y cuyo tiempo de vida es breve. Eso es un OTP.
Cuando hay un canal seguro para notificar el OTP, por ejemplo un mensaje por SMS. Es sencillo crear un OTP, se genera un código aleatorio asociado a ese usuario y listo.
Pero no siempre hay un canal seguro. En ese caso la solución es algo más complicada. Necesitamos tener dos programas que generen exactamente la misma contraseña en el mismo momento. Para estos sistemas necesitaremos dos cosas.
- Un secreto o clave, que es compartido por ambos sistemas y debe de permanecer en secreto para que sea seguro. La llamaremos k
- Una secuencia o contador, este dato puede ser publico sin ningún problema (en teoría) sirve para que ambos programas generadores creen la misma contraseña. Lo llamaremos c
Con random
Una implementación muy sencilla y de muy baja seguridad (suficiente para proyectos caseros) es usar el generado de números pseudoaleatorios de Arduino. En este caso el secreto es la semilla con la que se inicializa el generador. En este caso la secuencia o contador no es explicito, no se le pasa es implícito al numero de veces que se ha llamado a la función random. Lo que añade la dificultad añadida de tener ambas secuencias sincronizadas.
long randNumber;
void setup() {
randomSeed(k);
}
void calculateOTP() {
return random(10000, 99999);//contraseña de 5 digitos
}
Otro problema es que cada vez que se reinicia perdemos el punto donde estábamos de la secuencia y esta vuelve a empezar. Seria necesario guardar en la EEPROM el número de veces que hemos generado un OTP y luego llamar a la función ese numero de veces para resincronizar el estado del generador de números pseudoaletaorios.
Con una función hash
Otra táctica parecida es usar una función de hash. Para calcular la primera contraseña se llama a la función de hash con el secreto k, luego se usa el password anteriror, añadiendole el secreto k para calcular el siguiente:
k0 = H(k)
k1 = H(k0+k)
k2 = H(k1+k)
k3 = H(k2+k)
….
kn = H(kn-1+k)
La ventaja de este sistema es que basta con guardar en la EEPROM el último password generado para mantener la sincronización.
HTOP
Estos dos sistemas nos sirven para desarrollos caseros que no requieren demasiada seguridad para hacer una implementación segura podemos usar HMAC (hash-based message authentication code). HMAC usa una función de hash, un secreto o clave y un mensaje, en este caso el mensaje será el contador. A esta implementación se le conoce como HTOP (HMAC-based one-time password).
Empecemos viendo como funciona HMAC
HTOP(k, c) = HMAC(k, c) = H( (k ^ opad) || H(k ^ ipad) || c )
- H es la función e hash
- k es la clave secreta
- c es el contador
- opad es un bloque formado por el valor 0x5c repetido
- opad es un bloque formado por el valor 0x36 repetido
- || es la operación OR
- ^ es la operación XOR
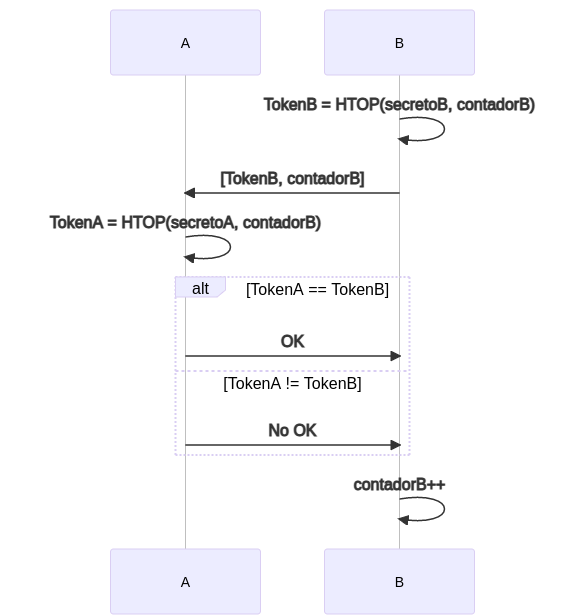
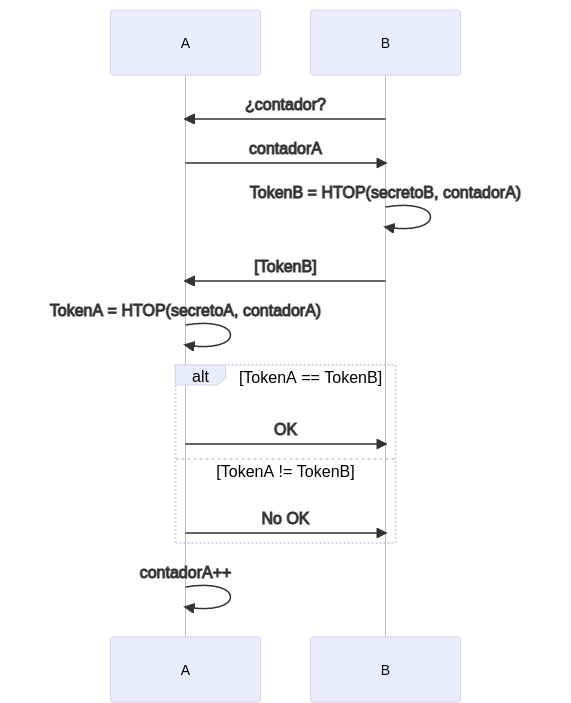
En este caso no necesitamos tener el contador sincronizado. El contador se puede pasar en la petición. Supongamos que el dispositivo B intenta contactar con el dispositivo A, el proceso puede ocurrir de dos maneras:
- B usa su contador interno y la pasa el password (TokenB ) con el contador usado para calcularlo. A calcula el password con el contador que le pasa B y verifica si coinciden
- B le pide a A un contador y A le pasa el contador con el que B tiene que generar el password (tokenB) y se lo devuelve a A que verifica si coinciden
El segundo caso es más seguro ya que evitamos que un atacante
TOTP
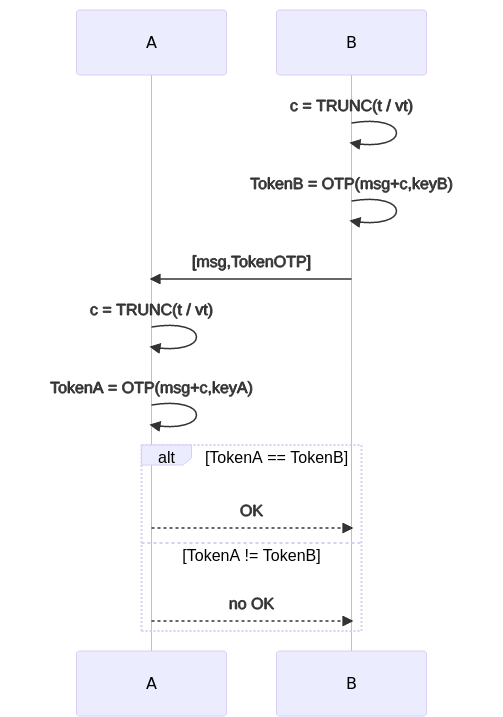
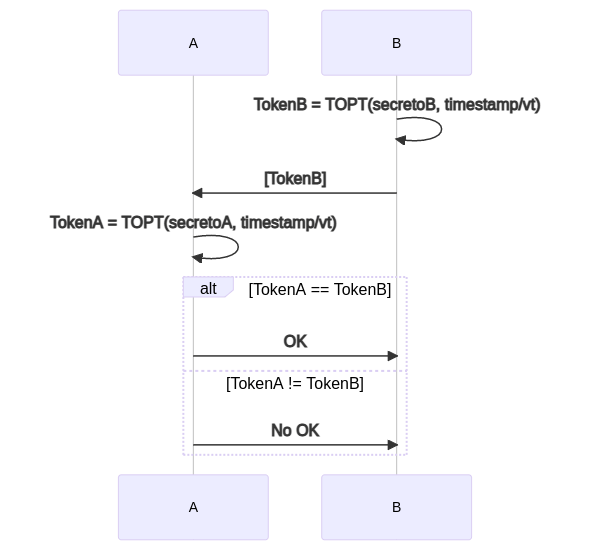
Lo ideal seria que ninguno tuviera que intercambiar el contador, que ambos tuvieran un contador sincronizado. Una opción seria usar la hora actual. O un timestamp que exprese la hora actual como milisegundos transcurridos desde el 1 de enero de 1970 a las 00:00:000. Es decir que TOTP (Time-based One-time Password) es HMAC usando como mensaje el tiempo o lo que es lo mismo usar HTOP usando como contador el tiempo.
El único problema aquí es que cada milisegundo la contraseña cambia y puede ser muy poco tiempo para realizar el intercambio de password. La solución es dejar una ventana de tiempo durante la cual el password es válido. Si usamos t para indicar el tiempo en milisegundo y vt el tiempo (en milisegundos) durante el cual el password es válido.
c = Trunc(t/vt)
TOTP(k, c) = HMAC(k, c)
Así nos ahorramos la parte de tener que intercambiar el contador entre dispositivos. Ambos usan la hora actual con una ventana de tiempo vt.
El problema es que Arduino no tiene un RTC (real time clock) por lo que no tiene forma de saber directamente qué hora es, necesita un elemento externo que le informe de ello.
«TOTP» sin RTC
Hay una forma un poco tramposa de implementar TOTP sin usar un RTC. En este caso partimos de HTOP, usaremos la segunda forma de HTOP en la que A le pasa el contador a B. El funcionamiento es exactamente igual que antes solo que tras un periodo de tiempo t la variable contadorA se incrementa automáticamente dejando a B con un OTP que ya no es valido.
No es un sistema tan cómodo como tener ambos sistemas sincronizados por su reloj. Ademas de que si varios dispositivos quieren conectarse al dispositivo A puede ser complicado de gestionar y necesitarías un contador y un secreto para cada uno.
¿Cual elegir?
Las soluciones basadas en HMAC son las más seguras pero también las más exigentes en tiempo y memoria. Y aunque TOTP es la segura y cómoda implica tener un RTC y que todos los dispositivos lo tengan sincronizados. Cada uno tiene que elegir el método según el balance de seguridad y coste.
Código
Para implementar todo esto podemos usar la librería Cryptosuite para Arduino. Permite usar la funciones hash SHA-1 y SHA-256.
Una vez copiada a nuestro directorio de librerías de Arduino puede usarse añadiendo el include correspondiente
Un ejemplo de uso de HMAC es:
uint8_t *hash;
Sha256.initHmac(key,keyLength); //secreto y su longitud
Sha256.print(counter); //contador
hash = Sha256.resultHmac();