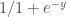Memoization, o memoización en español, es una técnica que permite ahorrar tiempo y recursos en el caso de que tengamos funciones cuyo tiempo de ejecución sea muy largo y se le llame varias veces con los mismos parámetros.
La idea es muy sencilla. En cada llamada a la función realizamos los siguientes pasos:
- Con los parámetros calculamos una clave única
- Comprobamos si ya tenemos un resultado asociado a esa clave
- Si lo tenemos devolvemos ese valor.
- Si no lo tenemos llamamos a la función
- Almacenamos el resultado de la función asociados a la clave calculada
La idea es calcular una clave única a partir de los parámetros que se pasan a la función y almacenar el resultado de la primera vez que se le llama para luego las las siguientes veces poder devolverlo sin calcularlo recuperándolo de la memoria.
Hay que ser consiente de que esta técnica permite una ventaja: reducir el tiempo de ejecución y pero con dos penalizaciones: la primera es que la mejora solo se consigue a partir de la segunda vez que se llama a la función, la primera vez se incrementa el coste puesto que se añade el tiempo de cálculo de la clave y de almacenar el resultado en memoria. La segunda penalización es que requiere espacio en memoria para guardar los resultados.
Esto solo funciona si la función cumple ciertas condiciones:
- El resultado de la función depende única y exclusivamente de los parámetros que se le pasan.
- Siempre devuelve el mismo resultado para los mismos parámetros.
- La única funcionalidad que realiza la función es calcular el resultado.
- Se llama varias veces a la función con los mismo parámetros.
- El coste de calculo del resultado es mayor que el coste de calcular la clave y buscar el resultado almacenado en memoria.
- Se intenta optimizar el tiempo de ejecución sobre el uso de memoria.
Ejemplo de implementación
Vamos a ver como implementar una clase JS para aplicar memoization.El código completo se puede encontrar en su repositorio de github.
La memoization tiene dos elementos principales, la función sobre la que se va a aplicar y como se calcula clave a partir de los argumentos que se pasan a esta función. En el constructor de la función vamos requerir estos dos argumentos, si bien el segundo tiene un valor por defecto. También es necesario inicializar la cache donde se guardaran los resultados.
constructor (func, keyFunc) {
this.func = func;
this.cache = {};
this.calculateKey = keyFunc || this.calculateKey;
}
Vamos a ver un ejemplo de función que calcula la clave para almacenar el resultado. En la versión por defecto lo que se hace es generar un array con todos los parámetros y convertirlos a un cadena de texto JSON.
calculateKey(){
let args = Array.from(arguments);
return JSON.stringify(args);
}
Tenemos, la función y la forma de calcular la clave. Nos queda como gestionamos la cache. Los pasos son:
- Calcular la clave
- Recuperar el valor asociado a esa clave
- Si el valor existe se devuelve
- Si no existe se calcula
call(){
let key = this.calculateKey(...arguments);
if(this.isInCache(key)){
return this.cache[key];
} else {
let result = this.func(...arguments);
this.add(key, result);
return result;
}
}
El código completo:
class Memo {
constructor (func, keyFunc) {
this.func = func;
this.cache = {};
this.calculateKey = keyFunc || this.calculateKey;
}
call(){
let key = this.calculateKey(...arguments);
if(this.isInCache(key)){
return this.cache[key];
} else {
let result = this.func(...arguments);
this.add(key, result);
return result;
}
}
calculateKey(){
let args = Array.from(arguments);
return JSON.stringify(args);
}
isInCache(key){
return key in this.cache;
}
add(key, value){
this.cache[key] = value;
}
}
Estrategias para generar la clave de la cache
Hay casos en que varias configuraciones distintas de parámetros son equivalentes. Cuando estos casos se conocen a priori, sin necesidad de calcular el resultado, una mejora puede ser cambiar la función que genera la clave para que tenga en cuenta esta particularidad. Principalmente hay dos estrategias para hacerlo: que la clave que se genera sea la misma para todos estos casos o generar todas las claves que se sabe que tienen el mismo resultado y añadirlas a la cache. Veamos algunos ejemplos.
Propiedad conmutativa: Hay casos en que puede intercambiar el valor de algunos parámetros sin que afecte al resultado. En estos casos una buena optimización es una vez calculado uno de estos casos se aplique a todos los que son equivalentes.
Por ejemplo si la función sum(a,b) realiza la suma de a y b. El resultado será el mismo aunque intercambien valores. sum(2,5) = sum(5,2). Podríamos generar ambas claves «[2,5]» y «[5,2]» y asignarles el mismo resultado.
Otra forma de hacerlo seria ordenar los parámetros de menor a mayor así sum(2,5) y sum(5,2) generarían la misma clave: «[2,5]».
Aproximaciones de números con decimales: En muchos casos la diferencia entre dos números decimales es tan pequeña que prácticamente no va a afectar al resultado. Para evitar calcular un resultado cuando no es necesario se puede calcular la clave limitando el numero de decimales.
Por ejemplo si fijamos que número máximo de decimales sean 2, tanto sum(3.141592 , 2) como sum(3.1416 , 2) generarían la misma clave «[3.14,2]»
Cadenas de texto: Otro de los casos habituales es que haya cadenas de texto que son equivalentes. Un caso habitual son las mayúsculas y minúsculas, en muchos casos no influye en el resultado. En un caso así search(«juan») y search(«Juan») deberían de generar las dos la misma clave: «[juan]»
Datos estructurados: Un caso especial es el de los argumentos que son alguna estructura de datos y que pueden tener muchas formas equivalentes. Por ejemplo, si uno de los parámetros que recibe es un JSON con dos valores «a» y «b» estas dos formas serian la misma: {«a»:1,»b»:2} y {«b»:2,»a»:1}. Llevando el ejemplo más lejos, si la funciona solo va mirar los campos «a» y «b» el caso {«a»:1,»b»:2,»c»:3} seria idéntico. Otro caso son los arrays cuando el orden de los elementos dentro de él da igual. Estos casos son mucho más difíciles de tratar ya que no se puede poner una regla que siempre sea válida y habrá que buscar soluciones propias para cada caso.
Como ejemplo podemos ver un par de ejemplos de como calcular la clave para la cache.
El primero ordena los argumentos que se le pasan;
function calculateKeySorted(){
let args = Array.from(arguments).sort();
return JSON.stringify(args);
}
El segundo convierte los argumentos a minúsculas:
function calculateKeyToLowerCase(){
let args = Array.from(arguments);
return JSON.stringify(args).toLowerCase();
}


![\sqrt[n]{\prod_{} x}](https://s0.wp.com/latex.php?latex=%5Csqrt%5Bn%5D%7B%5Cprod_%7B%7D+x%7D&bg=ffffff&fg=404040&s=0&c=20201002)