La función distancia se usa muy a menudo en muchos algoritmos para calcular la distancia entre puntos en el espacio. Hay algoritmos que hacen un uso intensivo de esta función como k-nn, k-means, o casi cualquier método que incluya buscar puntos cercanos. Por lo que reducir el coste de calcularla reporta una mayoría considerable de rendimiento.
Distintas distancias
Por suerte podemos usar funciones distancia diferentes. Una función distancia tiene que cumplir las siguientes condiciones cuando
x != y:
dist(x,x) = 0
dist(x,y) != 0
dist(x,y) = dist(y,x)
dist(x,y) <= dist(x,z) + dist(z,y)
Para calcular la distancia entre dos puntos es habitual usar la distancia euclídea:
dist(A,B) = √∑(Ai-Bi)²
Podemos hacer una primera mejora, si solo necesitamos comparar distancias podemos ahorrarnos la raíz cuadrada. Obtenemos una función distancia perfectamente válida y que puede reemplazar la euclídea
Pero hay una mejora más eliminar los cuadrados de las restas. Sin embargo hay un detalle a tener en cuenta, el cuadro de un número negativo es positivo, por lo que no basta con eliminarlos hay que reemplazarlos por el valor absoluto.
Esta parece un mejora menor pero en caso de espacios de muchas dimensiones puede llegar a notarse.
Pero no somos los primeros en llegar a esta conclusión, es conocida como distancia Manhattan:
dist(A,B) = ∑|Ai-Bi|
Realmente podemos reemplazar la distancia euclídea por cualquier distancia (tiene que cumplir los cuatro puntos anteriores) siempre que la nueva distancia cumpla que si en la distancia euclídea la distancia entre dos puntos cualesquiera A y B es mayor (o menor) que entre dos puntos cualesquiera C y D, en la nueva distancia también ha de ser mayor (o menor) en la nueva distancia.
Desigualdad triangular
Viendo la cuarta propiedad de las funciones distancia, conocida como desigualdad triangular, podemos usarla para acelerar la comparación entre distancias.
Teniendo tres puntos A,B,C sabemos que:
dist(A,B) + dist(B,C) >= dist(A,C)
|dist(A,B) – dist(B,C) | <= dist(A,C)
Es decir la suma de dos lados de un triángulo es mayor o igual que el tercer lado y el valor absoluto de la resta de dos lados es menor o igual que el tercer lado.
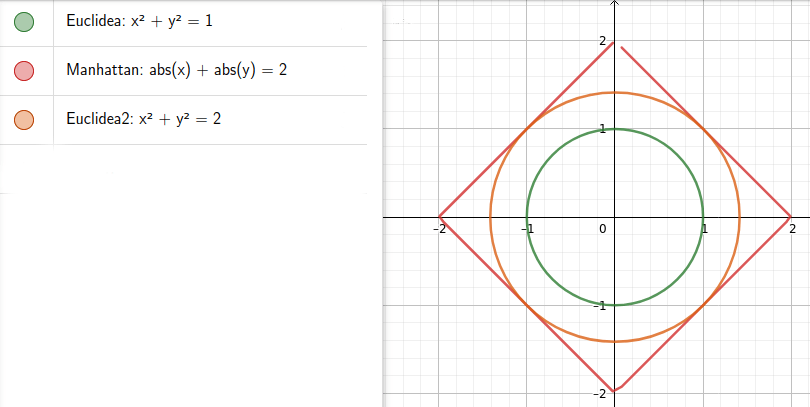
En la imagen de debajo de este texto se puede ver ejemplos visuales:

Esto nos sirve para acotar distancias sin calcularlas. Calculando solo dos distancias podemos acotar el valor mínimo y máximo de la tercera lo cual nos puede permitir descartarla sin calcularla.
Por ejemplo, nos dan un punto C y tenemos que averiguar qué otro punto está más cerca A o B. A y B ya los conocíamos así que tenemos precalculada dist(A,B). Calculamos dist(B,C), si dist(B,C) < |dist(A,B) – dist(B,C)| entonces podemos decir que dist(A,C) > dist(B,C) ¡Sin calcularla!
En muchas situaciones tenemos puntos que son previamente conocidos/aprendidos. Por lo que podemos tener una tabla de distancias entre puntos precalculadas y usarlas para acotar distancias sin necesidad de calcular la distancia entre todos los puntos.
El problema es que una tabla de distancias entre puntos puede ocupar demasiado espacio en memoria. Veamos una alternativa, calcular la distancia de todos los puntos al mismo punto. Si no hay muy buenas razones para usar otro punto usaremos el origen de coordenadas (el punto cuyas coordenadas son todas ceros). Es muy poco costoso calcular la distancia de origen a un punto P
dist(O, P) = √∑Pi² (euclídea)
dist(O, P) = ∑Pi (Manhattan)
Ahora si tenemos precalculadas las distancias de los puntos a comparar con el origen y nos dan un nuevo punto P. Calculamos dist(O, P) y tenemos precalculado dist(O,A) y queremos saber dist(A, P).
Sabemos que:
dist(O, A) + dist(O, P) >= dist(A, P) >= |dist(O, A) – dist(O, P)|
Max dist(A, P) = dist(O, A) + dist(O, P)
Min dist(A, P) = |dist(O, A) – dist(O, P)|
Ya tenemos una cota mínima y máxima de cual es la distancia de de A a P. Realmente por si misma no nos sirve de nada pero si hay que comparar con muchos puntos es suficiente pare descartar muchos de ellos.
Comparar distancias
Vamos a ver con una imagen la diferencia entre las tres distancias comentada en este texto. Euclídea, Euclídea² (sin hacer la raíz cuadrada) y distancia Manhattan. En la imagen inferior se puede ver la forma y el área que cubre una «circunferencia» de radio 2. (Tomando como circunferencia como aquel objeto geométrico cuyo todos sus puntos estan a la misma distancia del centro, en este caso 0,0)